 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Camera Cow Identification via Disentangled Representation Learning
Feb 07, 2026Precise identification of individual cows is a fundamental prerequisite for comprehensive digital management in smart livestock farming. While existing animal identification methods excel in controlled, single-camera settings, they face severe challenges regarding cross-camera generalization. When models trained on source cameras are deployed to new monitoring nodes characterized by divergent illumination, backgrounds, viewpoints, and heterogeneous imaging properties, recognition performance often degrades dramatically. This limits the large-scale application of non-contact technologies in dynamic, real-world farming environments. To address this challenge, this study proposes a cross-camera cow identification framework based on disentangled representation learning. This framework leverages the Subspace Identifiability Guarantee (SIG) theory in the context of bovine visual recognition. By modeling the underlying physical data generation process, we designed a principle-driven feature disentanglement module that decomposes observed images into multiple orthogonal latent subspaces. This mechanism effectively isolates stable, identity-related biometric features that remain invariant across cameras, thereby substantially improving generalization to unseen cameras. We constructed a high-quality dataset spanning five distinct camera nodes, covering heterogeneous acquisition devices and complex variations in lighting and angles. Extensive experiments across seven cross-camera tasks demonstrate that the proposed method achieves an average accuracy of 86.0%, significantly outperforming the Source-only Baseline (51.9%) and the strongest cross-camera baseline method (79.8%). This work establishes a subspace-theoretic feature disentanglement framework for collaborative cross-camera cow identification, offering a new paradigm for precise animal monitoring in uncontrolled smart farming environments.
Knowledge-aware Graph Transformer for Pedestrian Trajectory Prediction
Jan 10, 2024



Predicting pedestrian motion trajectories is crucial for path planning and motion control of autonomous vehicles. Accurately forecasting crowd trajectories is challenging due to the uncertain nature of human motions in different environments. For training, recent deep learning-based prediction approaches mainly utilize information like trajectory history and interactions between pedestrians, among others. This can limit the prediction performance across various scenarios since the discrepancies between training datasets have not been properly incorporated. To overcome this limitation, this paper proposes a graph transformer structure to improve prediction performance, capturing the differences between the various sites and scenarios contained in the datasets. In particular, a self-attention mechanism and a domain adaption module have been designed to improve the generalization ability of the model. Moreover, an additional metric considering cross-dataset sequences is introduced for training and performance evaluation purposes. The proposed framework is validated and compared against existing methods using popular public datasets, i.e., ETH and UCY. Experimental results demonstrate the improved performance of our proposed scheme.
Segmentation and Tracking of Vegetable Plants by Exploiting Vegetable Shape Feature for Precision Spray of Agricultural Robots
Jun 26, 2023With the increasing deployment of agricultural robots, the traditional manual spray of liquid fertilizer and pesticide is gradually being replaced by agricultural robots. For robotic precision spray application in vegetable farms, accurate plant phenotyping through instance segmentation and robust plant tracking are of great importance and a prerequisite for the following spray action. Regarding the robust tracking of vegetable plants, to solve the challenging problem of associating vegetables with similar color and texture in consecutive images, in this paper, a novel method of Multiple Object Tracking and Segmentation (MOTS) is proposed for instance segmentation and tracking of multiple vegetable plants. In our approach, contour and blob features are extracted to describe unique feature of each individual vegetable, and associate the same vegetables in different images. By assigning a unique ID for each vegetable, it ensures the robot to spray each vegetable exactly once, while traversing along the farm rows. Comprehensive experiments including ablation studies are conducted, which prove its superior performance over two State-Of-The-Art (SOTA) MOTS methods. Compared to the conventional MOTS methods, the proposed method is able to re-identify objects which have gone out of the camera field of view and re-appear again using the proposed data association strategy, which is important to ensure each vegetable be sprayed only once when the robot travels back and forth. Although the method is tested on lettuce farm, it can be applied to other similar vegetables such as broccoli and canola. Both code and the dataset of this paper is publicly released for the benefit of the community: https://github.com/NanH5837/LettuceMOTS.
CEKD:Cross Ensemble Knowledge Distillation for Augmented Fine-grained Data
Mar 13, 2022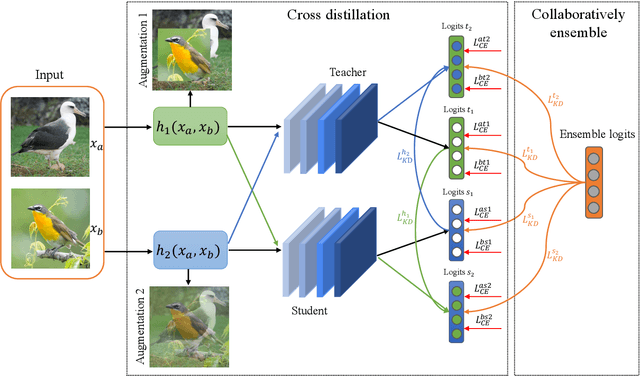
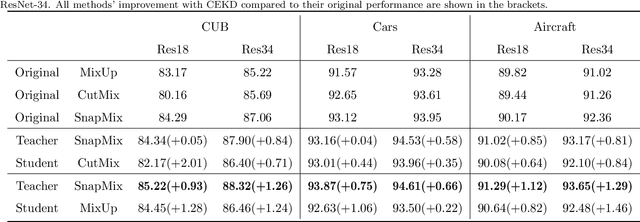
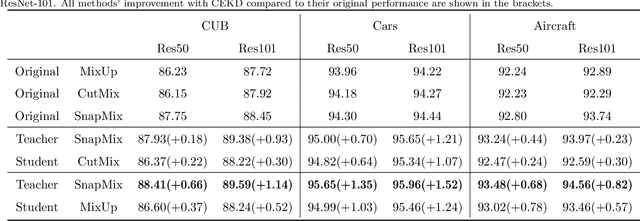

Data augmentation has been proved effective in training deep models. Existing data augmentation methods tackle the fine-grained problem by blending image pairs and fusing corresponding labels according to the statistics of mixed pixels, which produces additional noise harmful to the performance of networks. Motivated by this, we present a simple yet effective cross ensemble knowledge distillation (CEKD) model for fine-grained feature learning. We innovatively propose a cross distillation module to provide additional supervision to alleviate the noise problem, and propose a collaborative ensemble module to overcome the target conflict problem. The proposed model can be trained in an end-to-end manner, and only requires image-level label supervision. Extensive experiments on widely used fine-grained benchmarks demonstrate the effectiveness of our proposed model. Specifically, with the backbone of ResNet-101, CEKD obtains the accuracy of 89.59%, 95.96% and 94.56% in three datasets respectively, outperforming state-of-the-art API-Net by 0.99%, 1.06% and 1.16%.
Automated Aerial Animal Detection When Spatial Resolution Conditions Are Varied
Oct 04, 2021
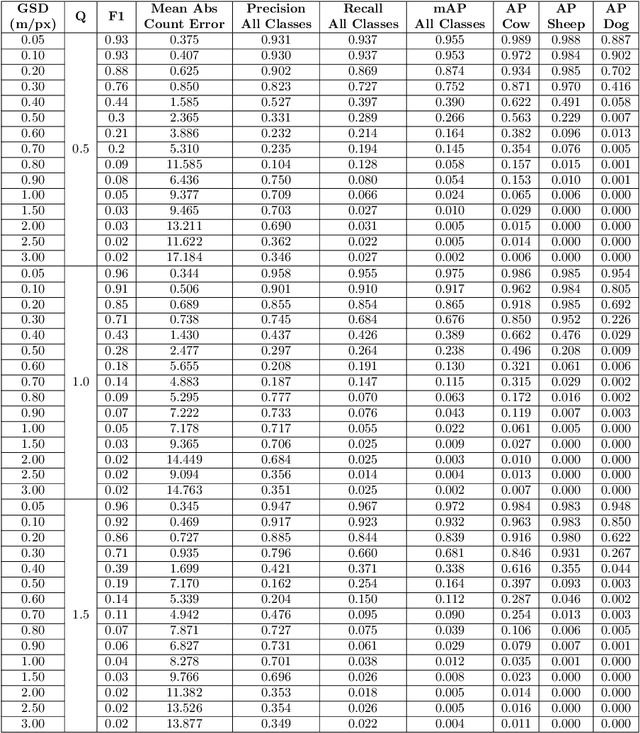
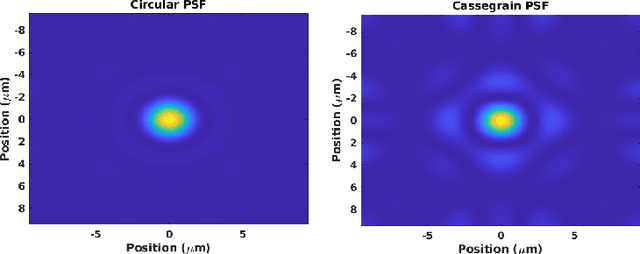
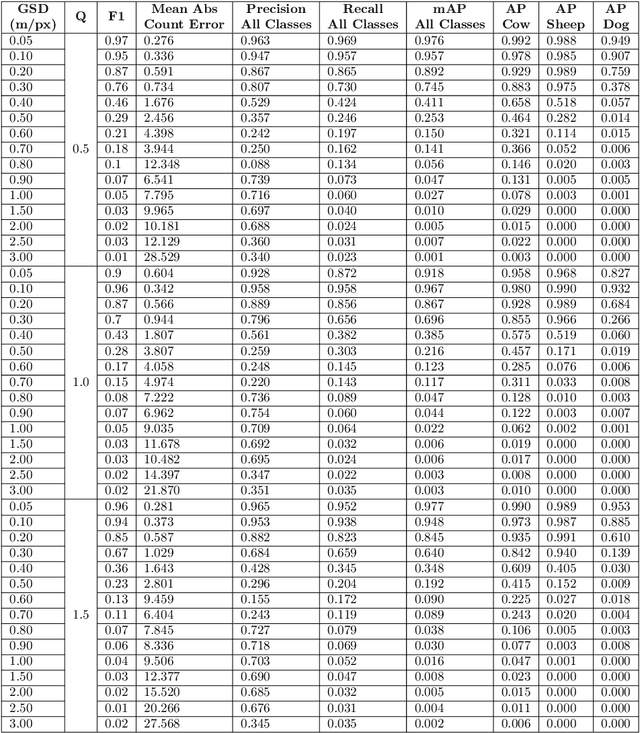
Knowing where livestock are located enables optimized management and mustering. However, Australian farms are large meaning that many of Australia's livestock are unmonitored which impacts farm profit, animal welfare and the environment. Effective animal localisation and counting by analysing satellite imagery overcomes this management hurdle however, high resolution satellite imagery is expensive. Thus, to minimise cost the lowest spatial resolution data that enables accurate livestock detection should be selected. In our work, we determine the association between object detector performance and spatial degradation for cattle, sheep and dogs. Accurate ground truth was established using high resolution drone images which were then downsampled to various ground sample distances (GSDs). Both circular and cassegrain aperture optics were simulated to generate point spread functions (PSFs) corresponding to various optical qualities. By simulating the PSF, rather than approximating it as a Gaussian, the images were accurately degraded to match the spatial resolution and blurring structure of satellite imagery. Two existing datasets were combined and used to train and test a YoloV5 object detection network. Detector performance was found to drop steeply around a GSD of 0.5m/px and was associated with PSF matrix structure within this GSD region. Detector mAP performance fell by 52 percent when a cassegrain, rather than circular, aperture was used at a 0.5m/px GSD. Overall blurring magnitude also had a small impact when matched to GSD, as did the internal network resolution. Our results here inform the selection of remote sensing data requirements for animal detection tasks, allowing farmers and ecologists to use more accessible medium resolution imagery with confidence.