 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorVess: Morphology-Aware Pulmonary Vessel Segmentation Network
Jun 23, 2026Accurate pulmonary vessel segmentation remains challenging due to the sparse, tortuous, and multi-scale nature of vascular structures, where small branches are easily lost and topology integrity is difficult to preserve under voxel-wise supervision. Existing deep segmentation models primarily optimize binary masks, lacking explicit geometric constraints, thus struggling to recover continuous tubular morphology and fine vascular connectivity. In this study, we introduce MorVess, a morphology-aware segmentation framework that integrates differentiable geometric priors with large-scale foundation model adaptation to achieve fine-grained vascular parsing. MorVess jointly predicts vessel masks, distance maps, and thickness maps, providing explicit supervision for vascular boundaries, centerline consistency, and smooth diameter transitions. A lightweight 2.5D adapter bridges 3D spatial context and 2D SAM representations, while a global-local fusion block aggregates multi-level semantics and geometric cues for high-fidelity topology reconstruction. Across two challenging pulmonary CT benchmarks, MorVess delivers superior Dice, clDice, and HD95 scores, substantially improving small-vessel recovery and global connectivity. These results demonstrate that embedding geometric intelligence into pretrained vision models offers a principled and scalable pathway toward precise vessel analysis and clinically reliable structural quantification. Our source code is available at https://github.com/MaoFuyou/MorVess.
GLeVE: Graph-Guided Lesion Grounding with Proposal Verification in 3D CT
May 21, 2026Grounding radiology report descriptions to 3D CT volumes is essential for verifiable clinical interpretation, yet remains challenging due to the semantic-spatial gap between free-text narratives and volumetric anatomy. Existing report-assisted and vision-language grounding methods typically rely on phrase-level alignment or dense pixel supervision, resulting in limited lesion-wise correspondence and suboptimal localization accuracy. We propose GLeVE, a graph-guided lesion grounding framework with anatomical prior verification and octree-based autoregressive refinement. GLeVE treats each lesion description as an atomic semantic unit and encodes organ attribution, attributes, and inter-lesion relations through relation-aware graph reasoning to produce discriminative lesion-wise queries. Anatomy-aware proposal generation with region-level verification enforces one-to-one text-lesion alignment, while hierarchical octree refinement progressively improves boundary delineation. Experiments on AbdomenAtlas 3.0 demonstrate consistent gains over classical multimodal foundation models and report-supervised baselines in both segmentation accuracy and lesion-level localization.
R2AoP: Reliable and Robust Angle of Progression Estimation from Intrapartum Ultrasound
May 20, 2026Accurate estimation of the Angle of Progression (AoP) from intrapartum transperineal ultrasound is critical for objective assessment of labor progression, yet remains highly sensitive to imaging noise, boundary ambiguities, and the geometric amplification of local segmentation errors. We propose R2AoP, a reliable and robust AoP estimation framework that integrates structurally informed segmentation and confidence-guided geometric modeling to achieve stable and reproducible measurements. A three-branch local-structure-enhanced backbone improves the delineation of the pubic symphysis (PS) and fetal head (FH), while confidence-weighted contour fitting explicitly suppresses the influence of unreliable boundary points in AoP computation. To further improve performance under heterogeneous acquisition conditions, we introduce a lightweight geometry-reliable test-time adaptation strategy as an auxiliary component, enabling stable inference without target annotations. Extensive evaluations on multi-center benchmarks demonstrate consistent reductions in AoP error and boundary metrics compared with state-of-the-art AoP methods. Our source code is available at https://github.com/baiyou1234/R2AoP.
MedCollab: Causal-Driven Multi-Agent Collaboration for Full-Cycle Clinical Diagnosis via IBIS-Structured Argumentation
Mar 01, 2026Large language models (LLMs) have shown promise in healthcare applications, however, their use in clinical practice is still limited by diagnostic hallucinations and insufficiently interpretable reasoning. We present MedCollab, a novel multi-agent framework that emulates the hierarchical consultation workflow of modern hospitals to autonomously navigate the full-cycle diagnostic process. The framework incorporates a dynamic specialist recruitment mechanism that adaptively assembles clinical and examination agents according to patient-specific symptoms and examination results. To ensure the rigor of clinical work, we adopt a structured Issue-Based Information System (IBIS) argumentation protocol that requires agents to provide ``Positions'' backed by traceable evidence from medical knowledge and clinical data. Furthermore, the framework constructs a Hierarchical Disease Causal Chain that transforms flattened diagnostic predictions into a structured model of pathological progression through explicit logical operators. A multi-round Consensus Mechanism iteratively filters low-quality reasoning through logic auditing and weighted voting. Evaluated on real-world clinical datasets, MedCollab significantly outperforms pure LLMs and medical multi-agent systems in Accuracy and RaTEScore, demonstrating a marked reduction in medical hallucinations. These findings indicate that MedCollab provides an extensible, transparent, and clinically compliant approach to medical decision-making.
SR3R: Rethinking Super-Resolution 3D Reconstruction With Feed-Forward Gaussian Splatting
Feb 27, 20263D super-resolution (3DSR) aims to reconstruct high-resolution (HR) 3D scenes from low-resolution (LR) multi-view images. Existing methods rely on dense LR inputs and per-scene optimization, which restricts the high-frequency priors for constructing HR 3D Gaussian Splatting (3DGS) to those inherited from pretrained 2D super-resolution (2DSR) models. This severely limits reconstruction fidelity, cross-scene generalization, and real-time usability. We propose to reformulate 3DSR as a direct feed-forward mapping from sparse LR views to HR 3DGS representations, enabling the model to autonomously learn 3D-specific high-frequency geometry and appearance from large-scale, multi-scene data. This fundamentally changes how 3DSR acquires high-frequency knowledge and enables robust generalization to unseen scenes. Specifically, we introduce SR3R, a feed-forward framework that directly predicts HR 3DGS representations from sparse LR views via the learned mapping network. To further enhance reconstruction fidelity, we introduce Gaussian offset learning and feature refinement, which stabilize reconstruction and sharpen high-frequency details. SR3R is plug-and-play and can be paired with any feed-forward 3DGS reconstruction backbone: the backbone provides an LR 3DGS scaffold, and SR3R upscales it to an HR 3DGS. Extensive experiments across three 3D benchmarks demonstrate that SR3R surpasses state-of-the-art (SOTA) 3DSR methods and achieves strong zero-shot generalization, even outperforming SOTA per-scene optimization methods on unseen scenes.
AnyAD: Unified Any-Modality Anomaly Detection in Incomplete Multi-Sequence MRI
Dec 24, 2025Reliable anomaly detection in brain MRI remains challenging due to the scarcity of annotated abnormal cases and the frequent absence of key imaging modalities in real clinical workflows. Existing single-class or multi-class anomaly detection (AD) models typically rely on fixed modality configurations, require repetitive training, or fail to generalize to unseen modality combinations, limiting their clinical scalability. In this work, we present a unified Any-Modality AD framework that performs robust anomaly detection and localization under arbitrary MRI modality availability. The framework integrates a dual-pathway DINOv2 encoder with a feature distribution alignment mechanism that statistically aligns incomplete-modality features with full-modality representations, enabling stable inference even with severe modality dropout. To further enhance semantic consistency, we introduce an Intrinsic Normal Prototypes (INPs) extractor and an INP-guided decoder that reconstruct only normal anatomical patterns while naturally amplifying abnormal deviations. Through randomized modality masking and indirect feature completion during training, the model learns to adapt to all modality configurations without re-training. Extensive experiments on BraTS2018, MU-Glioma-Post, and Pretreat-MetsToBrain-Masks demonstrate that our approach consistently surpasses state-of-the-art industrial and medical AD baselines across 7 modality combinations, achieving superior generalization. This study establishes a scalable paradigm for multimodal medical AD under real-world, imperfect modality conditions. Our source code is available at https://github.com/wuchangw/AnyAD.
MedGEN-Bench: Contextually entangled benchmark for open-ended multimodal medical generation
Nov 18, 2025As Vision-Language Models (VLMs) increasingly gain traction in medical applications, clinicians are progressively expecting AI systems not only to generate textual diagnoses but also to produce corresponding medical images that integrate seamlessly into authentic clinical workflows. Despite the growing interest, existing medical visual benchmarks present notable limitations. They often rely on ambiguous queries that lack sufficient relevance to image content, oversimplify complex diagnostic reasoning into closed-ended shortcuts, and adopt a text-centric evaluation paradigm that overlooks the importance of image generation capabilities. To address these challenges, we introduce MedGEN-Bench, a comprehensive multimodal benchmark designed to advance medical AI research. MedGEN-Bench comprises 6,422 expert-validated image-text pairs spanning six imaging modalities, 16 clinical tasks, and 28 subtasks. It is structured into three distinct formats: Visual Question Answering, Image Editing, and Contextual Multimodal Generation. What sets MedGEN-Bench apart is its focus on contextually intertwined instructions that necessitate sophisticated cross-modal reasoning and open-ended generative outputs, moving beyond the constraints of multiple-choice formats. To evaluate the performance of existing systems, we employ a novel three-tier assessment framework that integrates pixel-level metrics, semantic text analysis, and expert-guided clinical relevance scoring. Using this framework, we systematically assess 10 compositional frameworks, 3 unified models, and 5 VLMs.
No Modality Left Behind: Adapting to Missing Modalities via Knowledge Distillation for Brain Tumor Segmentation
Sep 18, 2025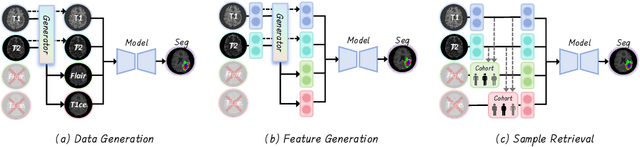
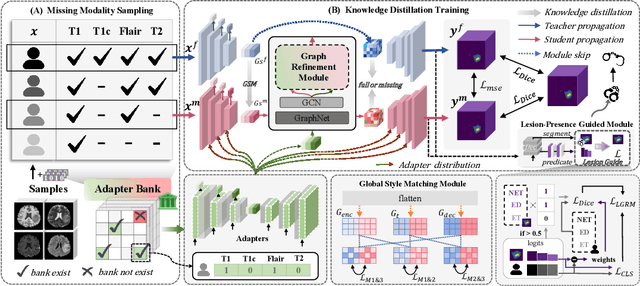
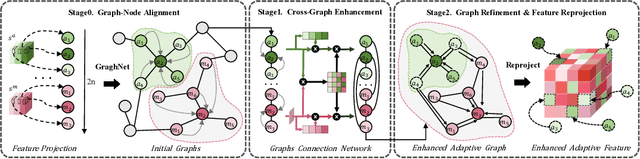
Accurate brain tumor segmentation is essential for preoperative evaluation and personalized treatment. Multi-modal MRI is widely used due to its ability to capture complementary tumor features across different sequences. However, in clinical practice, missing modalities are common, limiting the robustness and generalizability of existing deep learning methods that rely on complete inputs, especially under non-dominant modality combinations. To address this, we propose AdaMM, a multi-modal brain tumor segmentation framework tailored for missing-modality scenarios, centered on knowledge distillation and composed of three synergistic modules. The Graph-guided Adaptive Refinement Module explicitly models semantic associations between generalizable and modality-specific features, enhancing adaptability to modality absence. The Bi-Bottleneck Distillation Module transfers structural and textural knowledge from teacher to student models via global style matching and adversarial feature alignment. The Lesion-Presence-Guided Reliability Module predicts prior probabilities of lesion types through an auxiliary classification task, effectively suppressing false positives under incomplete inputs. Extensive experiments on the BraTS 2018 and 2024 datasets demonstrate that AdaMM consistently outperforms existing methods, exhibiting superior segmentation accuracy and robustness, particularly in single-modality and weak-modality configurations. In addition, we conduct a systematic evaluation of six categories of missing-modality strategies, confirming the superiority of knowledge distillation and offering practical guidance for method selection and future research. Our source code is available at https://github.com/Quanato607/AdaMM.
Brain-HGCN: A Hyperbolic Graph Convolutional Network for Brain Functional Network Analysis
Sep 18, 2025Functional magnetic resonance imaging (fMRI) provides a powerful non-invasive window into the brain's functional organization by generating complex functional networks, typically modeled as graphs. These brain networks exhibit a hierarchical topology that is crucial for cognitive processing. However, due to inherent spatial constraints, standard Euclidean GNNs struggle to represent these hierarchical structures without high distortion, limiting their clinical performance. To address this limitation, we propose Brain-HGCN, a geometric deep learning framework based on hyperbolic geometry, which leverages the intrinsic property of negatively curved space to model the brain's network hierarchy with high fidelity. Grounded in the Lorentz model, our model employs a novel hyperbolic graph attention layer with a signed aggregation mechanism to distinctly process excitatory and inhibitory connections, ultimately learning robust graph-level representations via a geometrically sound Fr\'echet mean for graph readout. Experiments on two large-scale fMRI datasets for psychiatric disorder classification demonstrate that our approach significantly outperforms a wide range of state-of-the-art Euclidean baselines. This work pioneers a new geometric deep learning paradigm for fMRI analysis, highlighting the immense potential of hyperbolic GNNs in the field of computational psychiatry.
Drawing2CAD: Sequence-to-Sequence Learning for CAD Generation from Vectorized Drawings
Aug 26, 2025



Computer-Aided Design (CAD) generative modeling is driving significant innovations across industrial applications. Recent works have shown remarkable progress in creating solid models from various inputs such as point clouds, meshes, and text descriptions. However, these methods fundamentally diverge from traditional industrial workflows that begin with 2D engineering drawings. The automatic generation of parametric CAD models from these 2D vector drawings remains underexplored despite being a critical step in engineering design. To address this gap, our key insight is to reframe CAD generation as a sequence-to-sequence learning problem where vector drawing primitives directly inform the generation of parametric CAD operations, preserving geometric precision and design intent throughout the transformation process. We propose Drawing2CAD, a framework with three key technical components: a network-friendly vector primitive representation that preserves precise geometric information, a dual-decoder transformer architecture that decouples command type and parameter generation while maintaining precise correspondence, and a soft target distribution loss function accommodating inherent flexibility in CAD parameters. To train and evaluate Drawing2CAD, we create CAD-VGDrawing, a dataset of paired engineering drawings and parametric CAD models, and conduct thorough experiments to demonstrate the effectiveness of our method. Code and dataset are available at https://github.com/lllssc/Drawing2CAD.