 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRectification Reimagined: A Unified Mamba Model for Image Correction and Rectangling with Prompts
Dec 21, 2025



Image correction and rectangling are valuable tasks in practical photography systems such as smartphones. Recent remarkable advancements in deep learning have undeniably brought about substantial performance improvements in these fields. Nevertheless, existing methods mainly rely on task-specific architectures. This significantly restricts their generalization ability and effective application across a wide range of different tasks. In this paper, we introduce the Unified Rectification Framework (UniRect), a comprehensive approach that addresses these practical tasks from a consistent distortion rectification perspective. Our approach incorporates various task-specific inverse problems into a general distortion model by simulating different types of lenses. To handle diverse distortions, UniRect adopts one task-agnostic rectification framework with a dual-component structure: a {Deformation Module}, which utilizes a novel Residual Progressive Thin-Plate Spline (RP-TPS) model to address complex geometric deformations, and a subsequent Restoration Module, which employs Residual Mamba Blocks (RMBs) to counteract the degradation caused by the deformation process and enhance the fidelity of the output image. Moreover, a Sparse Mixture-of-Experts (SMoEs) structure is designed to circumvent heavy task competition in multi-task learning due to varying distortions. Extensive experiments demonstrate that our models have achieved state-of-the-art performance compared with other up-to-date methods.
GFE-Mamba: Mamba-based AD Multi-modal Progression Assessment via Generative Feature Extraction from MCI
Jul 22, 2024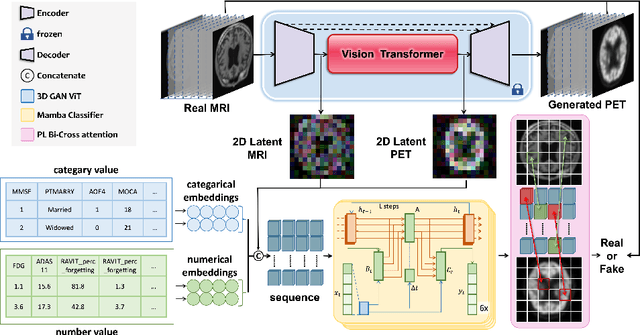



Alzheimer's Disease (AD) is an irreversible neurodegenerative disorder that often progresses from Mild Cognitive Impairment (MCI), leading to memory loss and significantly impacting patients' lives. Clinical trials indicate that early targeted interventions for MCI patients can potentially slow or halt the development and progression of AD. Previous research has shown that accurate medical classification requires the inclusion of extensive multimodal data, such as assessment scales and various neuroimaging techniques like Magnetic Resonance Imaging (MRI) and Positron Emission Tomography (PET). However, consistently tracking the diagnosis of the same individual over time and simultaneously collecting multimodal data poses significant challenges. To address this issue, we introduce GFE-Mamba, a classifier based on Generative Feature Extraction (GFE). This classifier effectively integrates data from assessment scales, MRI, and PET, enabling deeper multimodal fusion. It efficiently extracts both long and short sequence information and incorporates additional information beyond the pixel space. This approach not only improves classification accuracy but also enhances the interpretability and stability of the model. We constructed datasets of over 3000 samples based on the Alzheimer's Disease Neuroimaging Initiative (ADNI) for a two-step training process. Our experimental results demonstrate that the GFE-Mamba model is effective in predicting the conversion from MCI to AD and outperforms several state-of-the-art methods. Our source code and ADNI dataset processing code are available at https://github.com/Tinysqua/GFE-Mamba.
SCKansformer: Fine-Grained Classification of Bone Marrow Cells via Kansformer Backbone and Hierarchical Attention Mechanisms
Jun 14, 2024



The incidence and mortality rates of malignant tumors, such as acute leukemia, have risen significantly. Clinically, hospitals rely on cytological examination of peripheral blood and bone marrow smears to diagnose malignant tumors, with accurate blood cell counting being crucial. Existing automated methods face challenges such as low feature expression capability, poor interpretability, and redundant feature extraction when processing high-dimensional microimage data. We propose a novel fine-grained classification model, SCKansformer, for bone marrow blood cells, which addresses these challenges and enhances classification accuracy and efficiency. The model integrates the Kansformer Encoder, SCConv Encoder, and Global-Local Attention Encoder. The Kansformer Encoder replaces the traditional MLP layer with the KAN, improving nonlinear feature representation and interpretability. The SCConv Encoder, with its Spatial and Channel Reconstruction Units, enhances feature representation and reduces redundancy. The Global-Local Attention Encoder combines Multi-head Self-Attention with a Local Part module to capture both global and local features. We validated our model using the Bone Marrow Blood Cell Fine-Grained Classification Dataset (BMCD-FGCD), comprising over 10,000 samples and nearly 40 classifications, developed with a partner hospital. Comparative experiments on our private dataset, as well as the publicly available PBC and ALL-IDB datasets, demonstrate that SCKansformer outperforms both typical and advanced microcell classification methods across all datasets. Our source code and private BMCD-FGCD dataset are available at https://github.com/JustlfC03/SCKansformer.
Sequential vessel segmentation via deep channel attention network
Feb 10, 2021
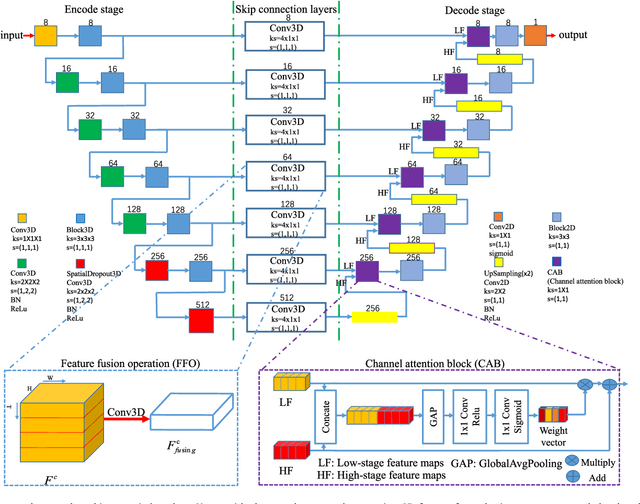
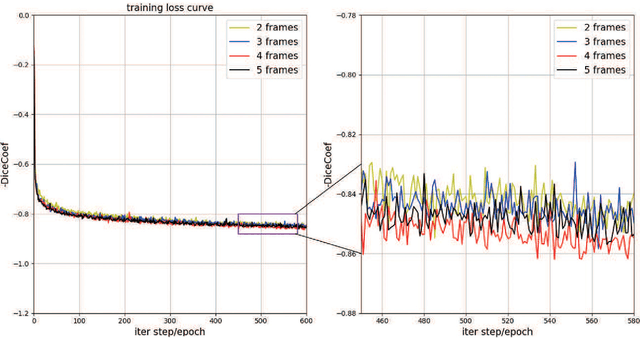

This paper develops a novel encoder-decoder deep network architecture which exploits the several contextual frames of 2D+t sequential images in a sliding window centered at current frame to segment 2D vessel masks from the current frame. The architecture is equipped with temporal-spatial feature extraction in encoder stage, feature fusion in skip connection layers and channel attention mechanism in decoder stage. In the encoder stage, a series of 3D convolutional layers are employed to hierarchically extract temporal-spatial features. Skip connection layers subsequently fuse the temporal-spatial feature maps and deliver them to the corresponding decoder stages. To efficiently discriminate vessel features from the complex and noisy backgrounds in the XCA images, the decoder stage effectively utilizes channel attention blocks to refine the intermediate feature maps from skip connection layers for subsequently decoding the refined features in 2D ways to produce the segmented vessel masks. Furthermore, Dice loss function is implemented to train the proposed deep network in order to tackle the class imbalance problem in the XCA data due to the wide distribution of complex background artifacts. Extensive experiments by comparing our method with other state-of-the-art algorithms demonstrate the proposed method's superior performance over other methods in terms of the quantitative metrics and visual validation. The source codes are at https://github.com/Binjie-Qin/SVS-net
* 14