 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential vessel segmentation via deep channel attention network
Paper and Code
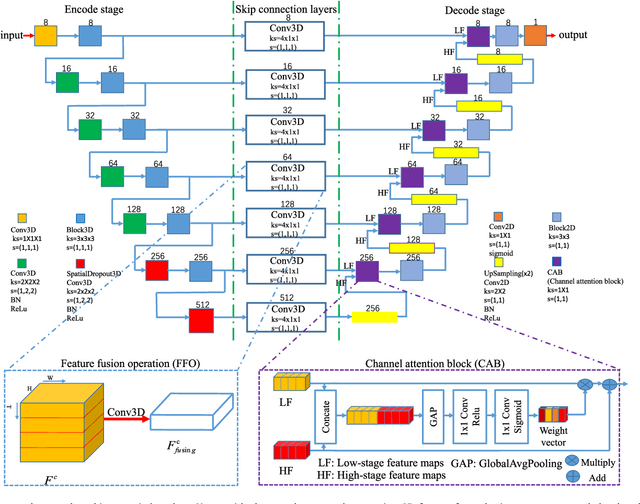
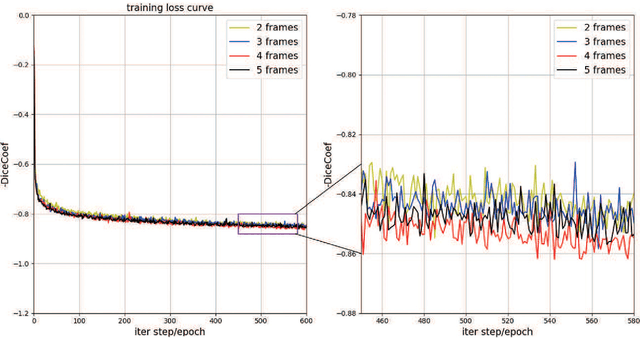

This paper develops a novel encoder-decoder deep network architecture which exploits the several contextual frames of 2D+t sequential images in a sliding window centered at current frame to segment 2D vessel masks from the current frame. The architecture is equipped with temporal-spatial feature extraction in encoder stage, feature fusion in skip connection layers and channel attention mechanism in decoder stage. In the encoder stage, a series of 3D convolutional layers are employed to hierarchically extract temporal-spatial features. Skip connection layers subsequently fuse the temporal-spatial feature maps and deliver them to the corresponding decoder stages. To efficiently discriminate vessel features from the complex and noisy backgrounds in the XCA images, the decoder stage effectively utilizes channel attention blocks to refine the intermediate feature maps from skip connection layers for subsequently decoding the refined features in 2D ways to produce the segmented vessel masks. Furthermore, Dice loss function is implemented to train the proposed deep network in order to tackle the class imbalance problem in the XCA data due to the wide distribution of complex background artifacts. Extensive experiments by comparing our method with other state-of-the-art algorithms demonstrate the proposed method's superior performance over other methods in terms of the quantitative metrics and visual validation. The source codes are at https://github.com/Binjie-Qin/SVS-net