 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQU-BraTS: MICCAI BraTS 2020 Challenge on Quantifying Uncertainty in Brain Tumor Segmentation -- Analysis of Ranking Metrics and Benchmarking Results
Dec 19, 2021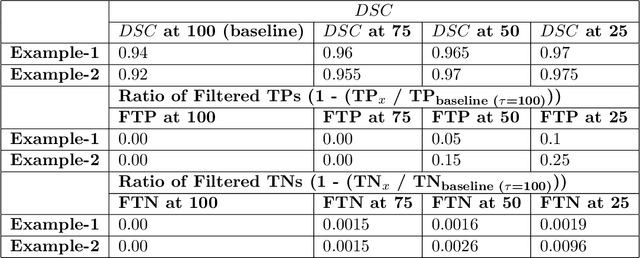
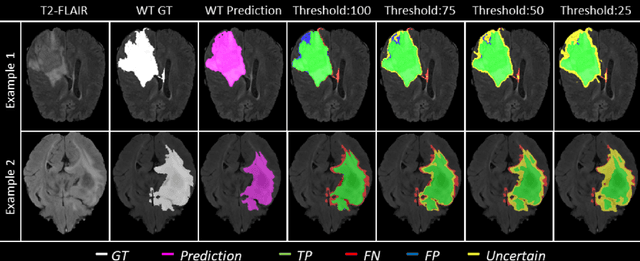
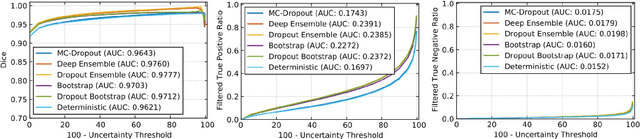
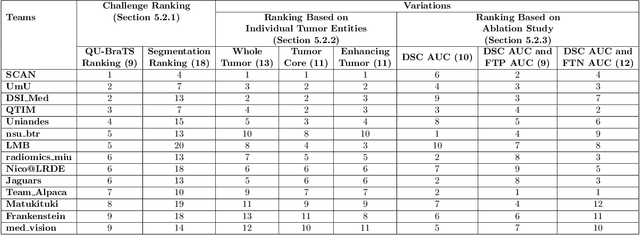
Deep learning (DL) models have provided the state-of-the-art performance in a wide variety of medical imaging benchmarking challenges, including the Brain Tumor Segmentation (BraTS) challenges. However, the task of focal pathology multi-compartment segmentation (e.g., tumor and lesion sub-regions) is particularly challenging, and potential errors hinder the translation of DL models into clinical workflows. Quantifying the reliability of DL model predictions in the form of uncertainties, could enable clinical review of the most uncertain regions, thereby building trust and paving the way towards clinical translation. Recently, a number of uncertainty estimation methods have been introduced for DL medical image segmentation tasks. Developing metrics to evaluate and compare the performance of uncertainty measures will assist the end-user in making more informed decisions. In this study, we explore and evaluate a metric developed during the BraTS 2019-2020 task on uncertainty quantification (QU-BraTS), and designed to assess and rank uncertainty estimates for brain tumor multi-compartment segmentation. This metric (1) rewards uncertainty estimates that produce high confidence in correct assertions, and those that assign low confidence levels at incorrect assertions, and (2) penalizes uncertainty measures that lead to a higher percentages of under-confident correct assertions. We further benchmark the segmentation uncertainties generated by 14 independent participating teams of QU-BraTS 2020, all of which also participated in the main BraTS segmentation task. Overall, our findings confirm the importance and complementary value that uncertainty estimates provide to segmentation algorithms, and hence highlight the need for uncertainty quantification in medical image analyses. Our evaluation code is made publicly available at https://github.com/RagMeh11/QU-BraTS.
Cross-Vendor CT Image Data Harmonization Using CVH-CT
Oct 19, 2021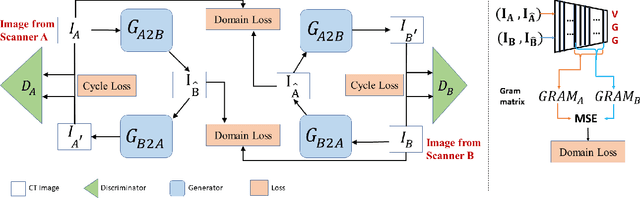

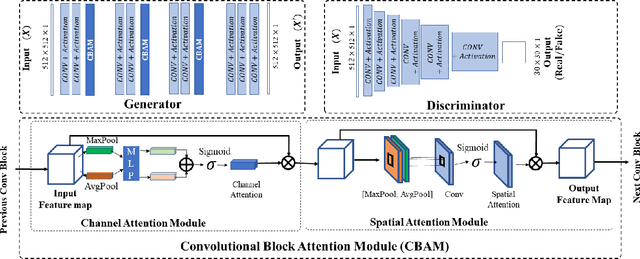
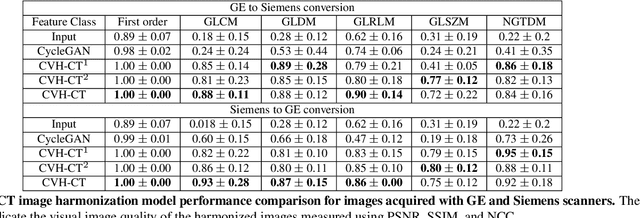
While remarkable advances have been made in Computed Tomography (CT), most of the existing efforts focus on imaging enhancement while reducing radiation dose. How to harmonize CT image data captured using different scanners is vital in cross-center large-scale radiomics studies but remains the boundary to explore. Furthermore, the lack of paired training image problem makes it computationally challenging to adopt existing deep learning models. %developed for CT image standardization. %this problem more challenging. We propose a novel deep learning approach called CVH-CT for harmonizing CT images captured using scanners from different vendors. The generator of CVH-CT uses a self-attention mechanism to learn the scanner-related information. We also propose a VGG feature-based domain loss to effectively extract texture properties from unpaired image data to learn the scanner-based texture distributions. The experimental results show that CVH-CT is clearly better than the baselines because of the use of the proposed domain loss, and CVH-CT can effectively reduce the scanner-related variability in terms of radiomic features.
CT Image Harmonization for Enhancing Radiomics Studies
Jul 03, 2021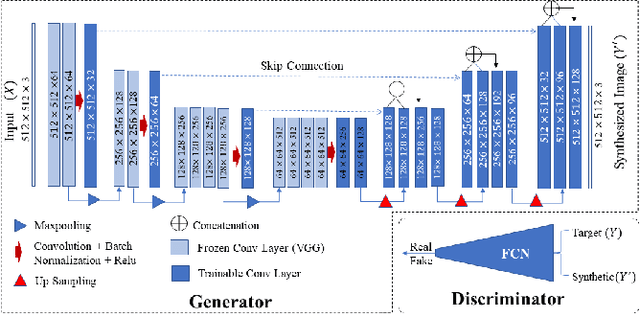
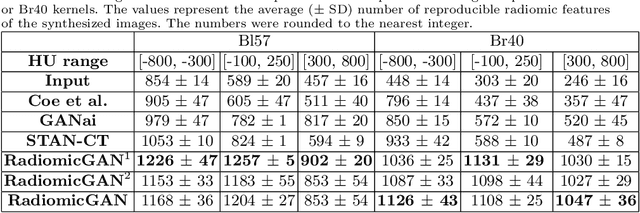
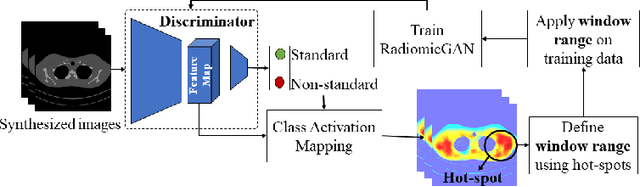

While remarkable advances have been made in Computed Tomography (CT), capturing CT images with non-standardized protocols causes low reproducibility regarding radiomic features, forming a barrier on CT image analysis in a large scale. RadiomicGAN is developed to effectively mitigate the discrepancy caused by using non-standard reconstruction kernels. RadiomicGAN consists of hybrid neural blocks including both pre-trained and trainable layers adopted to learn radiomic feature distributions efficiently. A novel training approach, called Dynamic Window-based Training, has been developed to smoothly transform the pre-trained model to the medical imaging domain. Model performance evaluated using 1401 radiomic features show that RadiomicGAN clearly outperforms the state-of-art image standardization models.
Sequential vessel segmentation via deep channel attention network
Feb 10, 2021
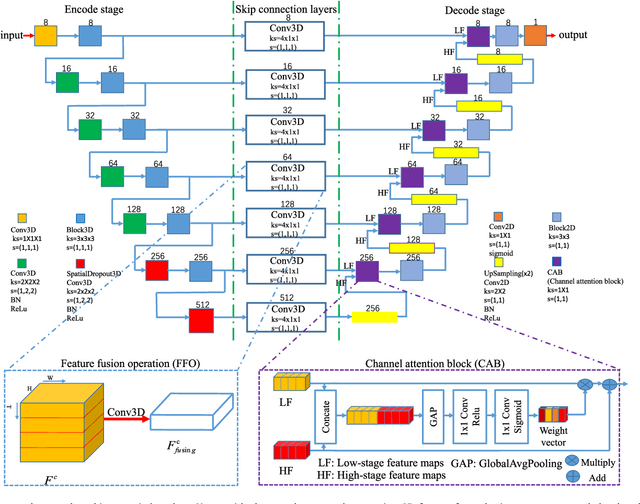
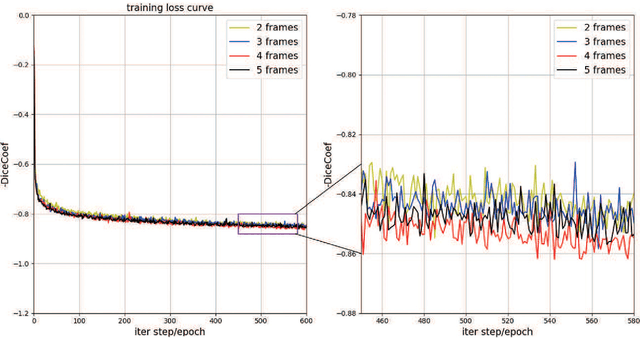

This paper develops a novel encoder-decoder deep network architecture which exploits the several contextual frames of 2D+t sequential images in a sliding window centered at current frame to segment 2D vessel masks from the current frame. The architecture is equipped with temporal-spatial feature extraction in encoder stage, feature fusion in skip connection layers and channel attention mechanism in decoder stage. In the encoder stage, a series of 3D convolutional layers are employed to hierarchically extract temporal-spatial features. Skip connection layers subsequently fuse the temporal-spatial feature maps and deliver them to the corresponding decoder stages. To efficiently discriminate vessel features from the complex and noisy backgrounds in the XCA images, the decoder stage effectively utilizes channel attention blocks to refine the intermediate feature maps from skip connection layers for subsequently decoding the refined features in 2D ways to produce the segmented vessel masks. Furthermore, Dice loss function is implemented to train the proposed deep network in order to tackle the class imbalance problem in the XCA data due to the wide distribution of complex background artifacts. Extensive experiments by comparing our method with other state-of-the-art algorithms demonstrate the proposed method's superior performance over other methods in terms of the quantitative metrics and visual validation. The source codes are at https://github.com/Binjie-Qin/SVS-net
* 14
STAN-CT: Standardizing CT Image using Generative Adversarial Network
Apr 02, 2020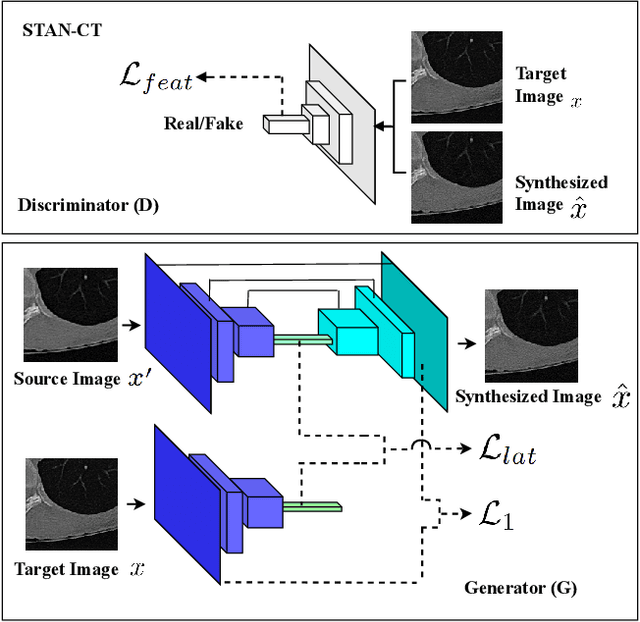


Computed tomography (CT) plays an important role in lung malignancy diagnostics and therapy assessment and facilitating precision medicine delivery. However, the use of personalized imaging protocols poses a challenge in large-scale cross-center CT image radiomic studies. We present an end-to-end solution called STAN-CT for CT image standardization and normalization, which effectively reduces discrepancies in image features caused by using different imaging protocols or using different CT scanners with the same imaging protocol. STAN-CT consists of two components: 1) a novel Generative Adversarial Networks (GAN) model that is capable of effectively learning the data distribution of a standard imaging protocol with only a few rounds of generator training, and 2) an automatic DICOM reconstruction pipeline with systematic image quality control that ensure the generation of high-quality standard DICOM images. Experimental results indicate that the training efficiency and model performance of STAN-CT have been significantly improved compared to the state-of-the-art CT image standardization and normalization algorithms.