 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4D-CAT: Synthesis of 4D Coronary Artery Trees from Systole and Diastole
Sep 03, 2024
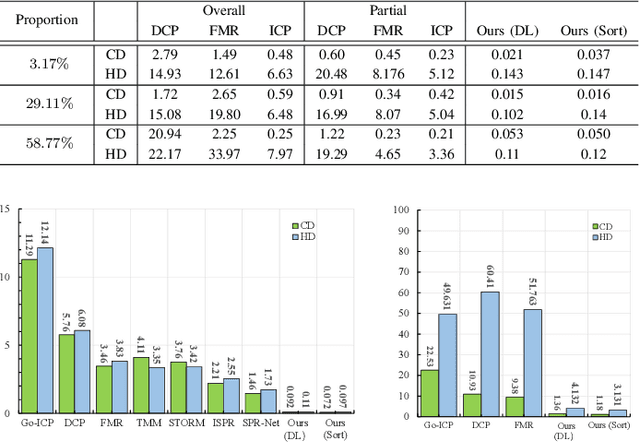

The three-dimensional vascular model reconstructed from CT images is widely used in medical diagnosis. At different phases, the beating of the heart can cause deformation of vessels, resulting in different vascular imaging states and false positive diagnostic results. The 4D model can simulate a complete cardiac cycle. Due to the dose limitation of contrast agent injection in patients, it is valuable to synthesize a 4D coronary artery trees through finite phases imaging. In this paper, we propose a method for generating a 4D coronary artery trees, which maps the systole to the diastole through deformation field prediction, interpolates on the timeline, and the motion trajectory of points are obtained. Specifically, the centerline is used to represent vessels and to infer deformation fields using cube-based sorting and neural networks. Adjacent vessel points are aggregated and interpolated based on the deformation field of the centerline point to obtain displacement vectors of different phases. Finally, the proposed method is validated through experiments to achieve the registration of non-rigid vascular points and the generation of 4D coronary trees.
Working memory inspired hierarchical video decomposition with transformative representations
Apr 25, 2022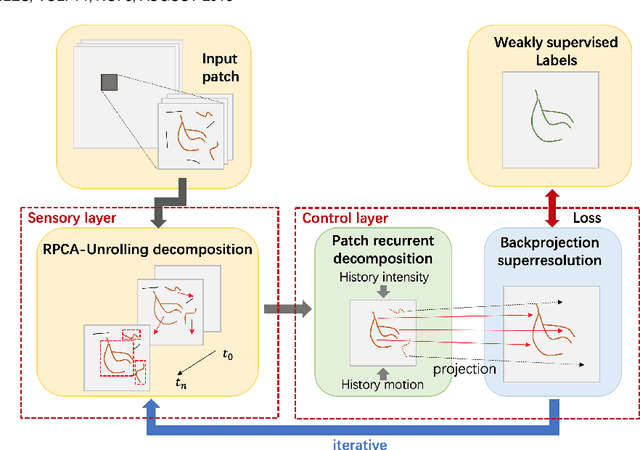
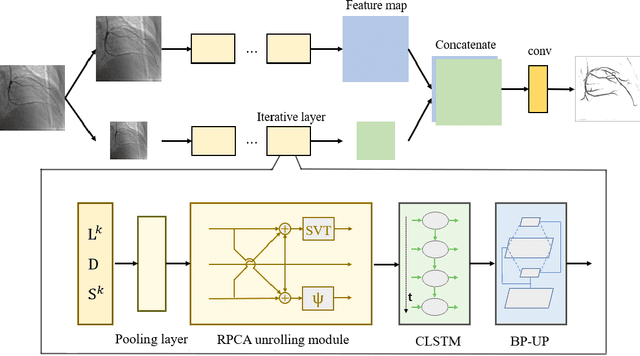
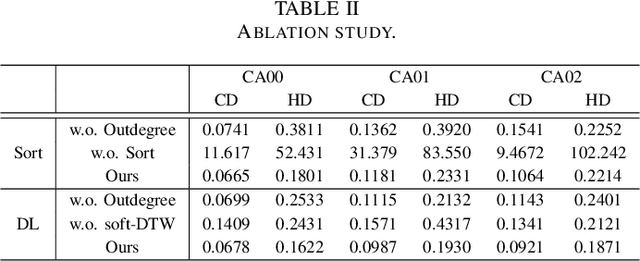
Video decomposition is very important to extract moving foreground objects from complex backgrounds in computer vision, machine learning, and medical imaging, e.g., extracting moving contrast-filled vessels from the complex and noisy backgrounds of X-ray coronary angiography (XCA). However, the challenges caused by dynamic backgrounds, overlapping heterogeneous environments and complex noises still exist in video decomposition. To solve these problems, this study is the first to introduce a flexible visual working memory model in video decomposition tasks to provide interpretable and high-performance hierarchical deep architecture, integrating the transformative representations between sensory and control layers from the perspective of visual and cognitive neuroscience. Specifically, robust PCA unrolling networks acting as a structure-regularized sensor layer decompose XCA into sparse/low-rank structured representations to separate moving contrast-filled vessels from noisy and complex backgrounds. Then, patch recurrent convolutional LSTM networks with a backprojection module embody unstructured random representations of the control layer in working memory, recurrently projecting spatiotemporally decomposed nonlocal patches into orthogonal subspaces for heterogeneous vessel retrieval and interference suppression. This video decomposition deep architecture effectively restores the heterogeneous profiles of intensity and the geometries of moving objects against the complex background interferences. Experiments show that the proposed method significantly outperforms state-of-the-art methods in accurate moving contrast-filled vessel extraction with excellent flexibility and computational efficiency.
Robust PCA Unrolling Network for Super-resolution Vessel Extraction in X-ray Coronary Angiography
Apr 24, 2022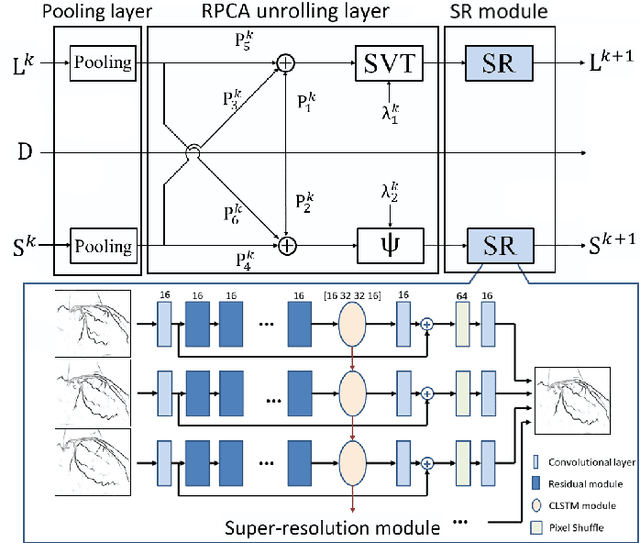
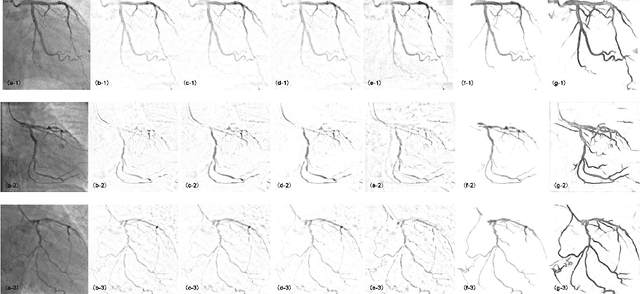

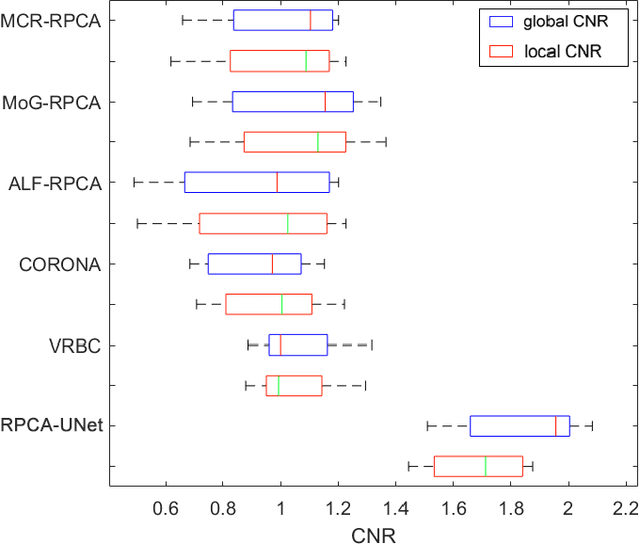
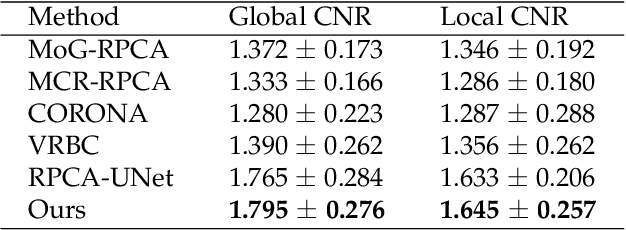
Although robust PCA has been increasingly adopted to extract vessels from X-ray coronary angiography (XCA) images, challenging problems such as inefficient vessel-sparsity modelling, noisy and dynamic background artefacts, and high computational cost still remain unsolved. Therefore, we propose a novel robust PCA unrolling network with sparse feature selection for super-resolution XCA vessel imaging. Being embedded within a patch-wise spatiotemporal super-resolution framework that is built upon a pooling layer and a convolutional long short-term memory network, the proposed network can not only gradually prune complex vessel-like artefacts and noisy backgrounds in XCA during network training but also iteratively learn and select the high-level spatiotemporal semantic information of moving contrast agents flowing in the XCA-imaged vessels. The experimental results show that the proposed method significantly outperforms state-of-the-art methods, especially in the imaging of the vessel network and its distal vessels, by restoring the intensity and geometry profiles of heterogeneous vessels against complex and dynamic backgrounds.
Sequential vessel segmentation via deep channel attention network
Feb 10, 2021
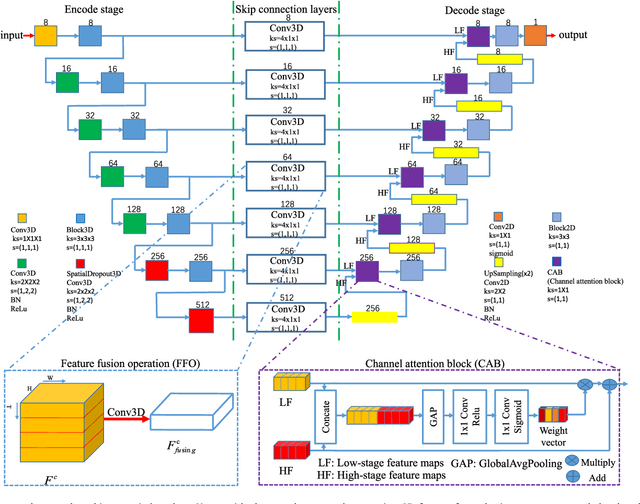
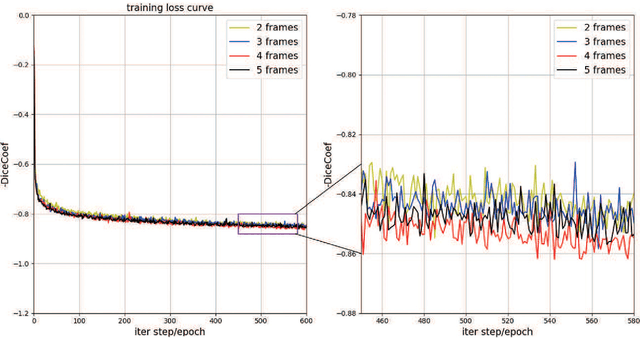

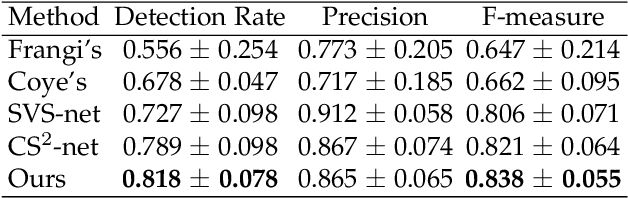
This paper develops a novel encoder-decoder deep network architecture which exploits the several contextual frames of 2D+t sequential images in a sliding window centered at current frame to segment 2D vessel masks from the current frame. The architecture is equipped with temporal-spatial feature extraction in encoder stage, feature fusion in skip connection layers and channel attention mechanism in decoder stage. In the encoder stage, a series of 3D convolutional layers are employed to hierarchically extract temporal-spatial features. Skip connection layers subsequently fuse the temporal-spatial feature maps and deliver them to the corresponding decoder stages. To efficiently discriminate vessel features from the complex and noisy backgrounds in the XCA images, the decoder stage effectively utilizes channel attention blocks to refine the intermediate feature maps from skip connection layers for subsequently decoding the refined features in 2D ways to produce the segmented vessel masks. Furthermore, Dice loss function is implemented to train the proposed deep network in order to tackle the class imbalance problem in the XCA data due to the wide distribution of complex background artifacts. Extensive experiments by comparing our method with other state-of-the-art algorithms demonstrate the proposed method's superior performance over other methods in terms of the quantitative metrics and visual validation. The source codes are at https://github.com/Binjie-Qin/SVS-net
* 14
Hallucinating very low-resolution and obscured face images
Dec 12, 2018

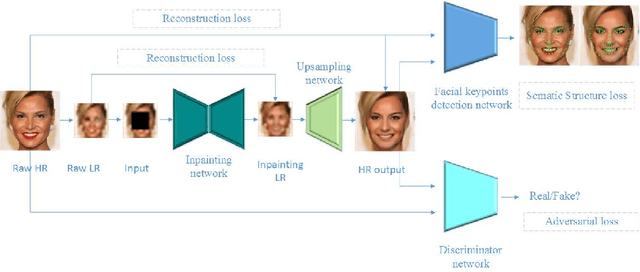

Most of the face hallucination methods are designed for complete inputs. They will not work well if the inputs are very tiny or contaminated by large occlusion. Inspired by this fact, we propose an obscured face hallucination network(OFHNet). The OFHNet consists of four parts: an inpainting network, an upsampling network, a discriminative network, and a fixed facial landmark detection network. The inpainting network restores the low-resolution(LR) obscured face images. The following upsampling network is to upsample the output of inpainting network. In order to ensure the generated high-resolution(HR) face images more photo-realistic, we utilize the discriminative network and the facial landmark detection network to better the result of upsampling network. In addition, we present a semantic structure loss, which makes the generated HR face images more pleasing. Extensive experiments show that our framework can restore the appealing HR face images from 1/4 missing area LR face images with a challenging scaling factor of 8x.