 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Maximum Entropy Misleads Policy Optimization
Jun 05, 2025The Maximum Entropy Reinforcement Learning (MaxEnt RL) framework is a leading approach for achieving efficient learning and robust performance across many RL tasks. However, MaxEnt methods have also been shown to struggle with performance-critical control problems in practice, where non-MaxEnt algorithms can successfully learn. In this work, we analyze how the trade-off between robustness and optimality affects the performance of MaxEnt algorithms in complex control tasks: while entropy maximization enhances exploration and robustness, it can also mislead policy optimization, leading to failure in tasks that require precise, low-entropy policies. Through experiments on a variety of control problems, we concretely demonstrate this misleading effect. Our analysis leads to better understanding of how to balance reward design and entropy maximization in challenging control problems.
Improving Value Estimation Critically Enhances Vanilla Policy Gradient
May 25, 2025
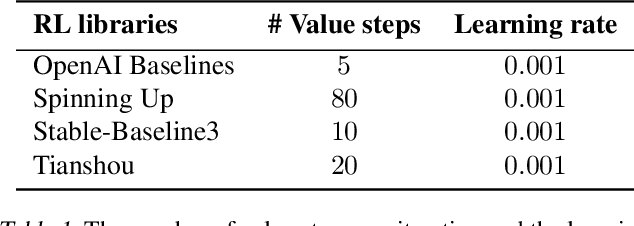
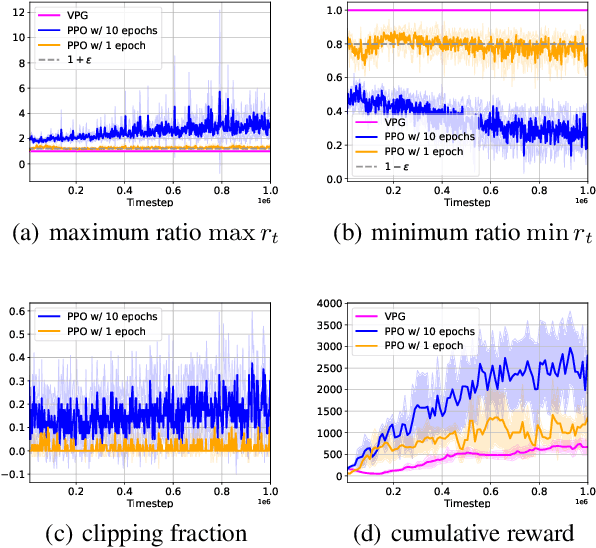
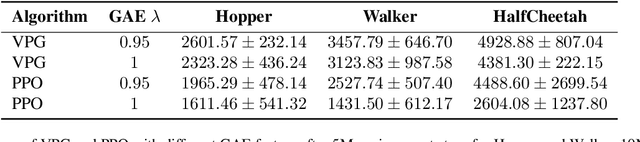
Modern policy gradient algorithms, such as TRPO and PPO, outperform vanilla policy gradient in many RL tasks. Questioning the common belief that enforcing approximate trust regions leads to steady policy improvement in practice, we show that the more critical factor is the enhanced value estimation accuracy from more value update steps in each iteration. To demonstrate, we show that by simply increasing the number of value update steps per iteration, vanilla policy gradient itself can achieve performance comparable to or better than PPO in all the standard continuous control benchmark environments. Importantly, this simple change to vanilla policy gradient is significantly more robust to hyperparameter choices, opening up the possibility that RL algorithms may still become more effective and easier to use.
Task-unaware Lifelong Robot Learning with Retrieval-based Weighted Local Adaptation
Oct 03, 2024



Real-world environments require robots to continuously acquire new skills while retaining previously learned abilities, all without the need for clearly defined task boundaries. Storing all past data to prevent forgetting is impractical due to storage and privacy concerns. To address this, we propose a method that efficiently restores a robot's proficiency in previously learned tasks over its lifespan. Using an Episodic Memory (EM), our approach enables experience replay during training and retrieval during testing for local fine-tuning, allowing rapid adaptation to previously encountered problems without explicit task identifiers. Additionally, we introduce a selective weighting mechanism that emphasizes the most challenging segments of retrieved demonstrations, focusing local adaptation where it is most needed. This framework offers a scalable solution for lifelong learning in dynamic, task-unaware environments, combining retrieval-based adaptation with selective weighting to enhance robot performance in open-ended scenarios.
Domain-Inspired Sharpness-Aware Minimization Under Domain Shifts
May 29, 2024



This paper presents a Domain-Inspired Sharpness-Aware Minimization (DISAM) algorithm for optimization under domain shifts. It is motivated by the inconsistent convergence degree of SAM across different domains, which induces optimization bias towards certain domains and thus impairs the overall convergence. To address this issue, we consider the domain-level convergence consistency in the sharpness estimation to prevent the overwhelming (deficient) perturbations for less (well) optimized domains. Specifically, DISAM introduces the constraint of minimizing variance in the domain loss, which allows the elastic gradient calibration in perturbation generation: when one domain is optimized above the averaging level \textit{w.r.t.} loss, the gradient perturbation towards that domain will be weakened automatically, and vice versa. Under this mechanism, we theoretically show that DISAM can achieve faster overall convergence and improved generalization in principle when inconsistent convergence emerges. Extensive experiments on various domain generalization benchmarks show the superiority of DISAM over a range of state-of-the-art methods. Furthermore, we show the superior efficiency of DISAM in parameter-efficient fine-tuning combined with the pretraining models. The source code is released at https://github.com/MediaBrain-SJTU/DISAM.
Federated Learning under Partially Class-Disjoint Data via Manifold Reshaping
May 29, 2024Statistical heterogeneity severely limits the performance of federated learning (FL), motivating several explorations e.g., FedProx, MOON and FedDyn, to alleviate this problem. Despite effectiveness, their considered scenario generally requires samples from almost all classes during the local training of each client, although some covariate shifts may exist among clients. In fact, the natural case of partially class-disjoint data (PCDD), where each client contributes a few classes (instead of all classes) of samples, is practical yet underexplored. Specifically, the unique collapse and invasion characteristics of PCDD can induce the biased optimization direction in local training, which prevents the efficiency of federated learning. To address this dilemma, we propose a manifold reshaping approach called FedMR to calibrate the feature space of local training. Our FedMR adds two interplaying losses to the vanilla federated learning: one is intra-class loss to decorrelate feature dimensions for anti-collapse; and the other one is inter-class loss to guarantee the proper margin among categories in the feature expansion. We conduct extensive experiments on a range of datasets to demonstrate that our FedMR achieves much higher accuracy and better communication efficiency. Source code is available at: https://github.com/MediaBrain-SJTU/FedMR.git.
Federated Learning with Bilateral Curation for Partially Class-Disjoint Data
May 29, 2024Partially class-disjoint data (PCDD), a common yet under-explored data formation where each client contributes a part of classes (instead of all classes) of samples, severely challenges the performance of federated algorithms. Without full classes, the local objective will contradict the global objective, yielding the angle collapse problem for locally missing classes and the space waste problem for locally existing classes. As far as we know, none of the existing methods can intrinsically mitigate PCDD challenges to achieve holistic improvement in the bilateral views (both global view and local view) of federated learning. To address this dilemma, we are inspired by the strong generalization of simplex Equiangular Tight Frame~(ETF) on the imbalanced data, and propose a novel approach called FedGELA where the classifier is globally fixed as a simplex ETF while locally adapted to the personal distributions. Globally, FedGELA provides fair and equal discrimination for all classes and avoids inaccurate updates of the classifier, while locally it utilizes the space of locally missing classes for locally existing classes. We conduct extensive experiments on a range of datasets to demonstrate that our FedGELA achieves promising performance~(averaged improvement of 3.9% to FedAvg and 1.5% to best baselines) and provide both local and global convergence guarantees. Source code is available at:https://github.com/MediaBrain-SJTU/FedGELA.git.
Fair Evaluation of Federated Learning Algorithms for Automated Breast Density Classification: The Results of the 2022 ACR-NCI-NVIDIA Federated Learning Challenge
May 22, 2024The correct interpretation of breast density is important in the assessment of breast cancer risk. AI has been shown capable of accurately predicting breast density, however, due to the differences in imaging characteristics across mammography systems, models built using data from one system do not generalize well to other systems. Though federated learning (FL) has emerged as a way to improve the generalizability of AI without the need to share data, the best way to preserve features from all training data during FL is an active area of research. To explore FL methodology, the breast density classification FL challenge was hosted in partnership with the American College of Radiology, Harvard Medical School's Mass General Brigham, University of Colorado, NVIDIA, and the National Institutes of Health National Cancer Institute. Challenge participants were able to submit docker containers capable of implementing FL on three simulated medical facilities, each containing a unique large mammography dataset. The breast density FL challenge ran from June 15 to September 5, 2022, attracting seven finalists from around the world. The winning FL submission reached a linear kappa score of 0.653 on the challenge test data and 0.413 on an external testing dataset, scoring comparably to a model trained on the same data in a central location.
* 16 pages, 9 figures
UniChest: Conquer-and-Divide Pre-training for Multi-Source Chest X-Ray Classification
Dec 18, 2023



Vision-Language Pre-training (VLP) that utilizes the multi-modal information to promote the training efficiency and effectiveness, has achieved great success in vision recognition of natural domains and shown promise in medical imaging diagnosis for the Chest X-Rays (CXRs). However, current works mainly pay attention to the exploration on single dataset of CXRs, which locks the potential of this powerful paradigm on larger hybrid of multi-source CXRs datasets. We identify that although blending samples from the diverse sources offers the advantages to improve the model generalization, it is still challenging to maintain the consistent superiority for the task of each source due to the existing heterogeneity among sources. To handle this dilemma, we design a Conquer-and-Divide pre-training framework, termed as UniChest, aiming to make full use of the collaboration benefit of multiple sources of CXRs while reducing the negative influence of the source heterogeneity. Specially, the ``Conquer" stage in UniChest encourages the model to sufficiently capture multi-source common patterns, and the ``Divide" stage helps squeeze personalized patterns into different small experts (query networks). We conduct thorough experiments on many benchmarks, e.g., ChestX-ray14, CheXpert, Vindr-CXR, Shenzhen, Open-I and SIIM-ACR Pneumothorax, verifying the effectiveness of UniChest over a range of baselines, and release our codes and pre-training models at https://github.com/Elfenreigen/UniChest.
Learning-based Motion Planning in Dynamic Environments Using GNNs and Temporal Encoding
Oct 16, 2022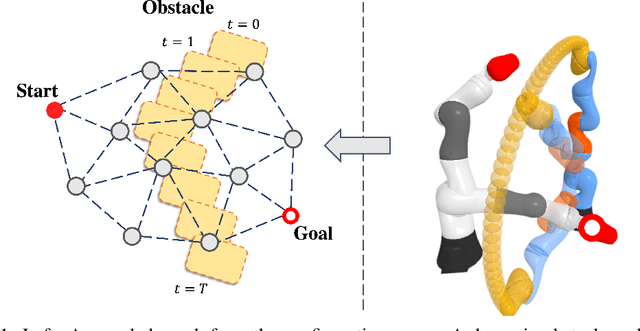
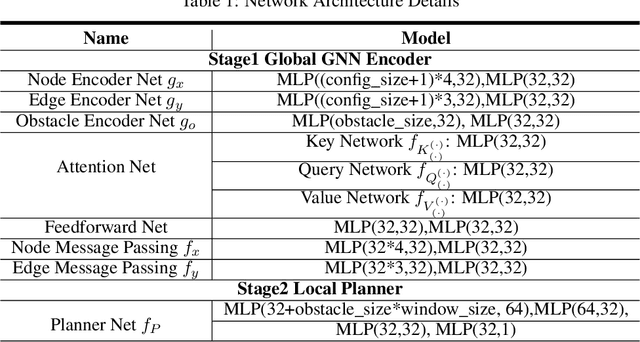
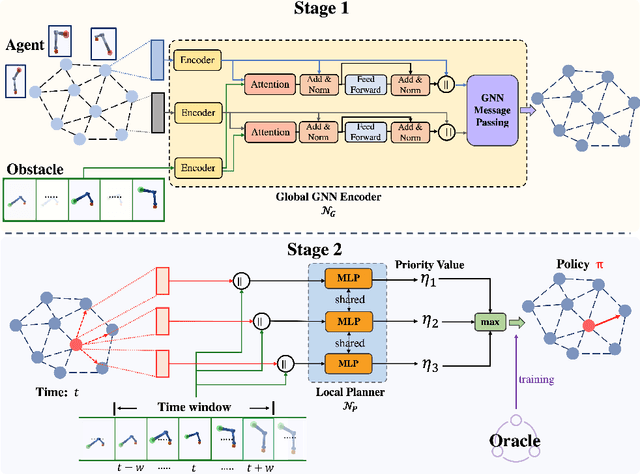
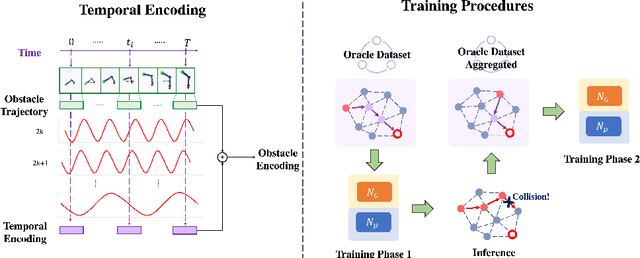
Learning-based methods have shown promising performance for accelerating motion planning, but mostly in the setting of static environments. For the more challenging problem of planning in dynamic environments, such as multi-arm assembly tasks and human-robot interaction, motion planners need to consider the trajectories of the dynamic obstacles and reason about temporal-spatial interactions in very large state spaces. We propose a GNN-based approach that uses temporal encoding and imitation learning with data aggregation for learning both the embeddings and the edge prioritization policies. Experiments show that the proposed methods can significantly accelerate online planning over state-of-the-art complete dynamic planning algorithms. The learned models can often reduce costly collision checking operations by more than 1000x, and thus accelerating planning by up to 95%, while achieving high success rates on hard instances as well.
Working memory inspired hierarchical video decomposition with transformative representations
Apr 25, 2022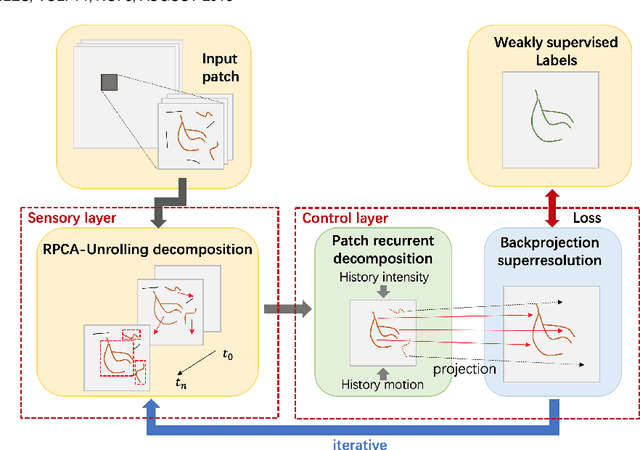
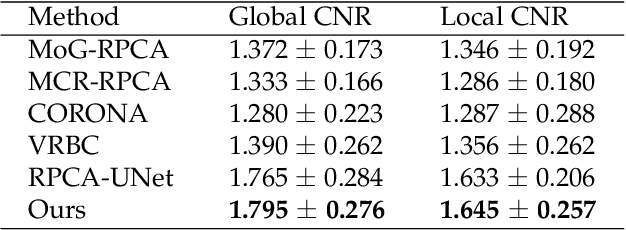
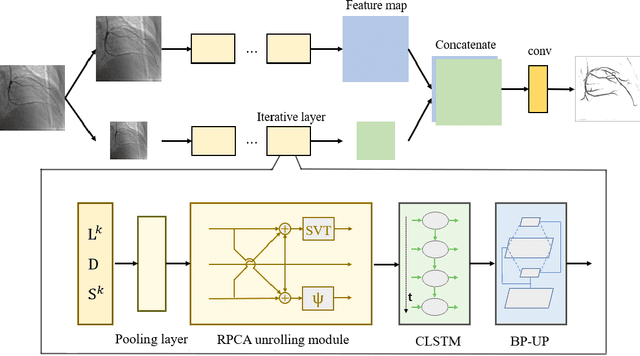
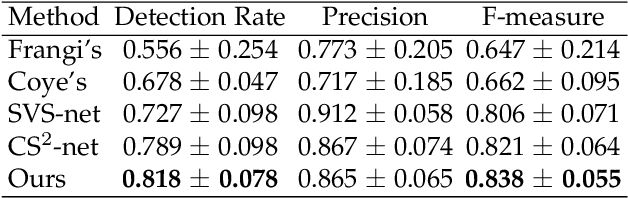
Video decomposition is very important to extract moving foreground objects from complex backgrounds in computer vision, machine learning, and medical imaging, e.g., extracting moving contrast-filled vessels from the complex and noisy backgrounds of X-ray coronary angiography (XCA). However, the challenges caused by dynamic backgrounds, overlapping heterogeneous environments and complex noises still exist in video decomposition. To solve these problems, this study is the first to introduce a flexible visual working memory model in video decomposition tasks to provide interpretable and high-performance hierarchical deep architecture, integrating the transformative representations between sensory and control layers from the perspective of visual and cognitive neuroscience. Specifically, robust PCA unrolling networks acting as a structure-regularized sensor layer decompose XCA into sparse/low-rank structured representations to separate moving contrast-filled vessels from noisy and complex backgrounds. Then, patch recurrent convolutional LSTM networks with a backprojection module embody unstructured random representations of the control layer in working memory, recurrently projecting spatiotemporally decomposed nonlocal patches into orthogonal subspaces for heterogeneous vessel retrieval and interference suppression. This video decomposition deep architecture effectively restores the heterogeneous profiles of intensity and the geometries of moving objects against the complex background interferences. Experiments show that the proposed method significantly outperforms state-of-the-art methods in accurate moving contrast-filled vessel extraction with excellent flexibility and computational efficiency.