 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorking memory inspired hierarchical video decomposition with transformative representations
Paper and Code
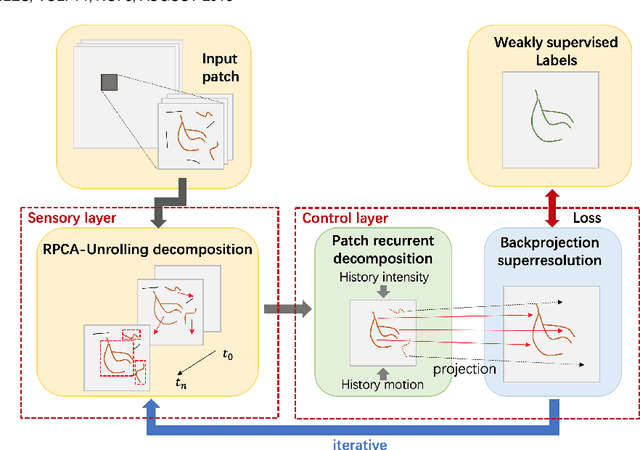
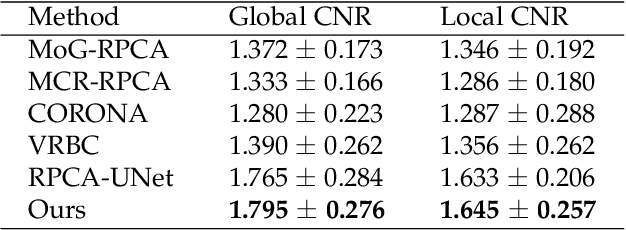
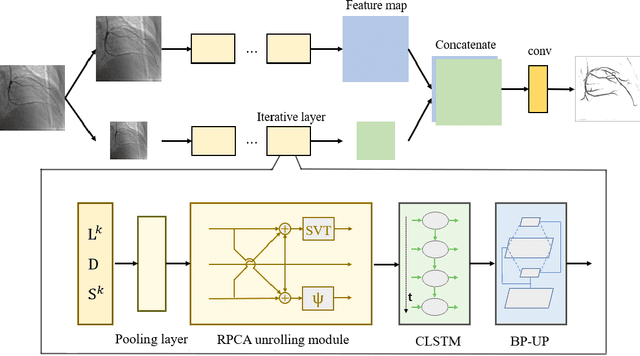
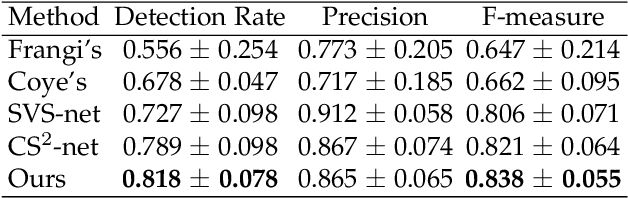
Video decomposition is very important to extract moving foreground objects from complex backgrounds in computer vision, machine learning, and medical imaging, e.g., extracting moving contrast-filled vessels from the complex and noisy backgrounds of X-ray coronary angiography (XCA). However, the challenges caused by dynamic backgrounds, overlapping heterogeneous environments and complex noises still exist in video decomposition. To solve these problems, this study is the first to introduce a flexible visual working memory model in video decomposition tasks to provide interpretable and high-performance hierarchical deep architecture, integrating the transformative representations between sensory and control layers from the perspective of visual and cognitive neuroscience. Specifically, robust PCA unrolling networks acting as a structure-regularized sensor layer decompose XCA into sparse/low-rank structured representations to separate moving contrast-filled vessels from noisy and complex backgrounds. Then, patch recurrent convolutional LSTM networks with a backprojection module embody unstructured random representations of the control layer in working memory, recurrently projecting spatiotemporally decomposed nonlocal patches into orthogonal subspaces for heterogeneous vessel retrieval and interference suppression. This video decomposition deep architecture effectively restores the heterogeneous profiles of intensity and the geometries of moving objects against the complex background interferences. Experiments show that the proposed method significantly outperforms state-of-the-art methods in accurate moving contrast-filled vessel extraction with excellent flexibility and computational efficiency.