 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorking memory inspired hierarchical video decomposition with transformative representations
Apr 25, 2022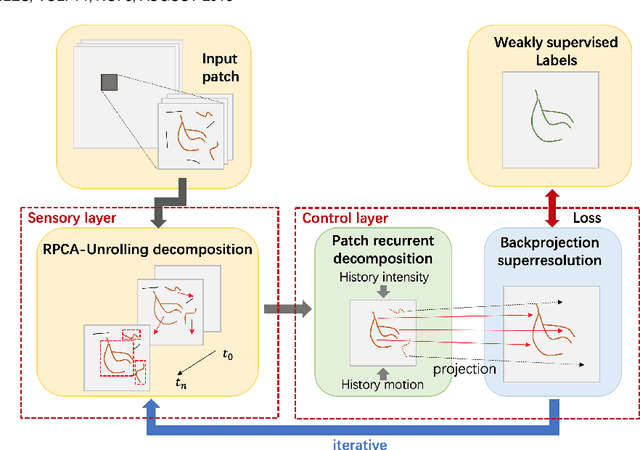
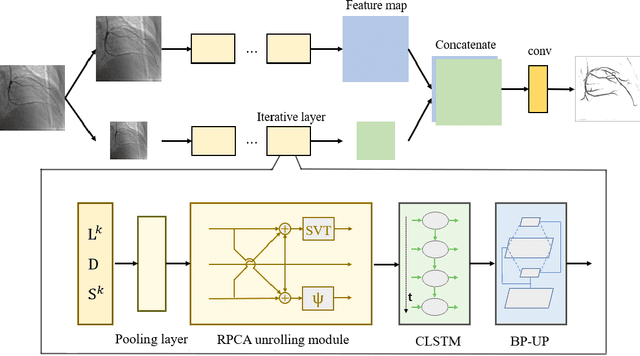
Video decomposition is very important to extract moving foreground objects from complex backgrounds in computer vision, machine learning, and medical imaging, e.g., extracting moving contrast-filled vessels from the complex and noisy backgrounds of X-ray coronary angiography (XCA). However, the challenges caused by dynamic backgrounds, overlapping heterogeneous environments and complex noises still exist in video decomposition. To solve these problems, this study is the first to introduce a flexible visual working memory model in video decomposition tasks to provide interpretable and high-performance hierarchical deep architecture, integrating the transformative representations between sensory and control layers from the perspective of visual and cognitive neuroscience. Specifically, robust PCA unrolling networks acting as a structure-regularized sensor layer decompose XCA into sparse/low-rank structured representations to separate moving contrast-filled vessels from noisy and complex backgrounds. Then, patch recurrent convolutional LSTM networks with a backprojection module embody unstructured random representations of the control layer in working memory, recurrently projecting spatiotemporally decomposed nonlocal patches into orthogonal subspaces for heterogeneous vessel retrieval and interference suppression. This video decomposition deep architecture effectively restores the heterogeneous profiles of intensity and the geometries of moving objects against the complex background interferences. Experiments show that the proposed method significantly outperforms state-of-the-art methods in accurate moving contrast-filled vessel extraction with excellent flexibility and computational efficiency.
Robust PCA Unrolling Network for Super-resolution Vessel Extraction in X-ray Coronary Angiography
Apr 24, 2022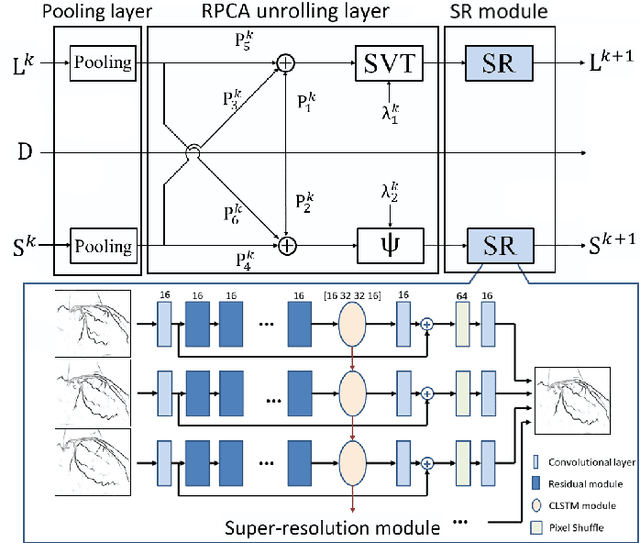
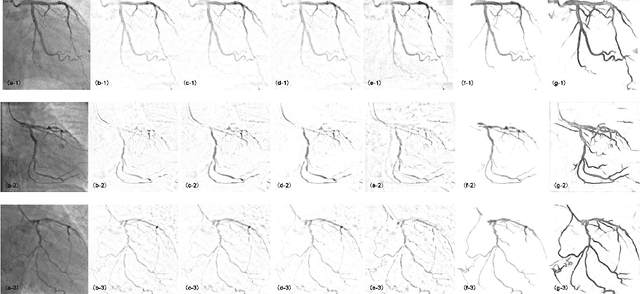

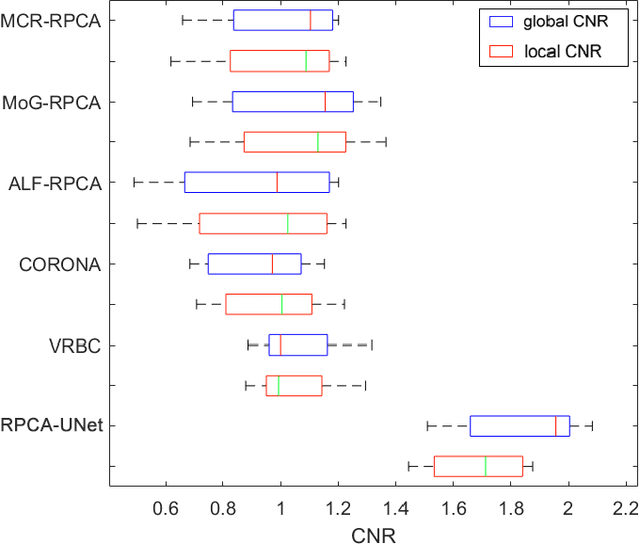
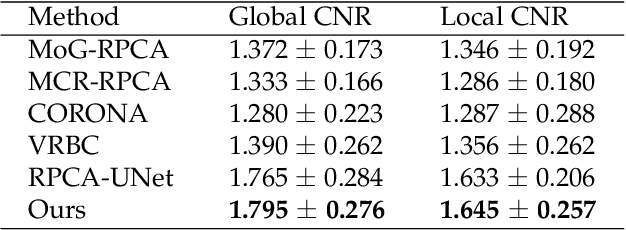
Although robust PCA has been increasingly adopted to extract vessels from X-ray coronary angiography (XCA) images, challenging problems such as inefficient vessel-sparsity modelling, noisy and dynamic background artefacts, and high computational cost still remain unsolved. Therefore, we propose a novel robust PCA unrolling network with sparse feature selection for super-resolution XCA vessel imaging. Being embedded within a patch-wise spatiotemporal super-resolution framework that is built upon a pooling layer and a convolutional long short-term memory network, the proposed network can not only gradually prune complex vessel-like artefacts and noisy backgrounds in XCA during network training but also iteratively learn and select the high-level spatiotemporal semantic information of moving contrast agents flowing in the XCA-imaged vessels. The experimental results show that the proposed method significantly outperforms state-of-the-art methods, especially in the imaging of the vessel network and its distal vessels, by restoring the intensity and geometry profiles of heterogeneous vessels against complex and dynamic backgrounds.
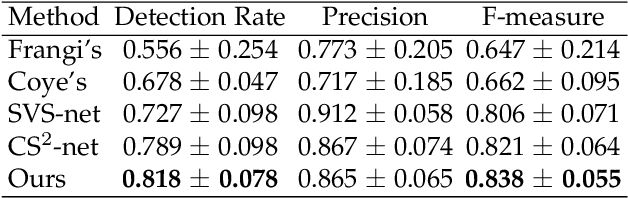
Sequential vessel segmentation via deep channel attention network
Feb 10, 2021
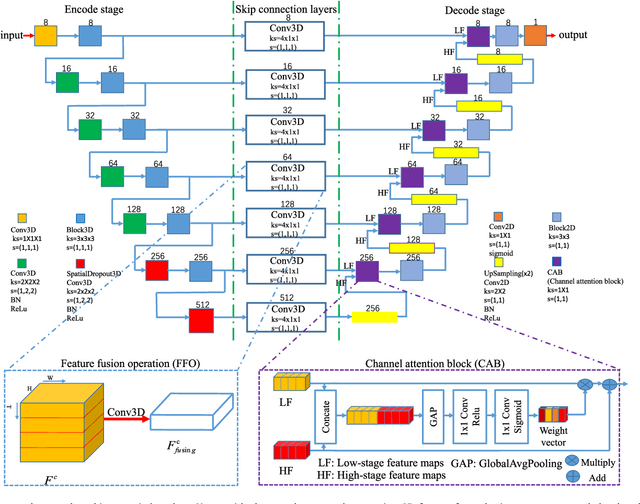

This paper develops a novel encoder-decoder deep network architecture which exploits the several contextual frames of 2D+t sequential images in a sliding window centered at current frame to segment 2D vessel masks from the current frame. The architecture is equipped with temporal-spatial feature extraction in encoder stage, feature fusion in skip connection layers and channel attention mechanism in decoder stage. In the encoder stage, a series of 3D convolutional layers are employed to hierarchically extract temporal-spatial features. Skip connection layers subsequently fuse the temporal-spatial feature maps and deliver them to the corresponding decoder stages. To efficiently discriminate vessel features from the complex and noisy backgrounds in the XCA images, the decoder stage effectively utilizes channel attention blocks to refine the intermediate feature maps from skip connection layers for subsequently decoding the refined features in 2D ways to produce the segmented vessel masks. Furthermore, Dice loss function is implemented to train the proposed deep network in order to tackle the class imbalance problem in the XCA data due to the wide distribution of complex background artifacts. Extensive experiments by comparing our method with other state-of-the-art algorithms demonstrate the proposed method's superior performance over other methods in terms of the quantitative metrics and visual validation. The source codes are at https://github.com/Binjie-Qin/SVS-net
* 14
Texture variation adaptive image denoising with nonlocal PCA
Oct 26, 2018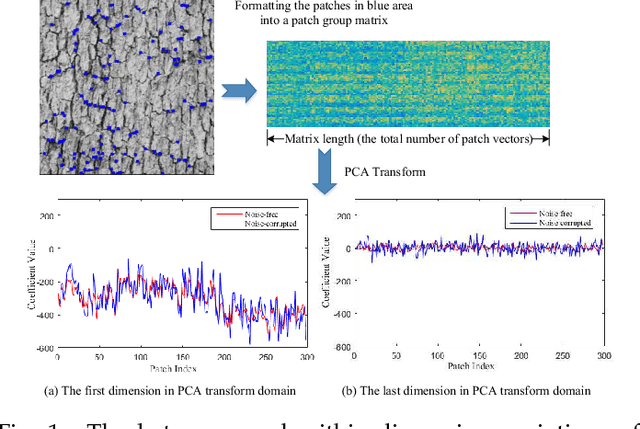
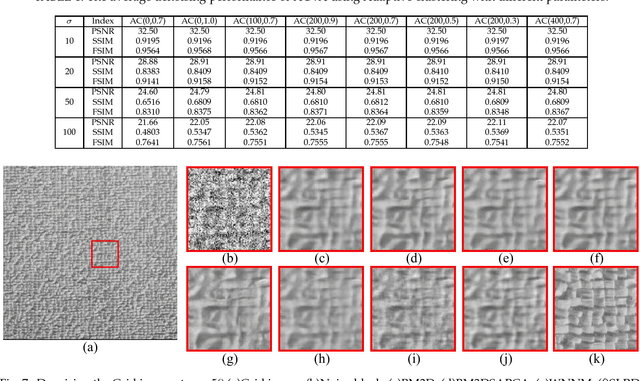


Image textures, as a kind of local variations, provide important information for human visual system. Many image textures, especially the small-scale or stochastic textures are rich in high-frequency variations, and are difficult to be preserved. Current state-of-the-art denoising algorithms typically adopt a nonlocal approach consisting of image patch grouping and group-wise denoising filtering. To achieve a better image denoising while preserving the variations in texture, we first adaptively group high correlated image patches with the same kinds of texture elements (texels) via an adaptive clustering method. This adaptive clustering method is applied in an over-clustering-and-iterative-merging approach, where its noise robustness is improved with a custom merging threshold relating to the noise level and cluster size. For texture-preserving denoising of each cluster, considering that the variations in texture are captured and wrapped in not only the between-dimension energy variations but also the within-dimension variations of PCA transform coefficients, we further propose a PCA-transform-domain variation adaptive filtering method to preserve the local variations in textures. Experiments on natural images show the superiority of the proposed transform-domain variation adaptive filtering to traditional PCA-based hard or soft threshold filtering. As a whole, the proposed denoising method achieves a favorable texture preserving performance both quantitatively and visually, especially for stochastic textures, which is further verified in camera raw image denoising.
Local Structure Matching Driven by Joint-Saliency-Structure Adaptive Kernel Regression
Apr 15, 2013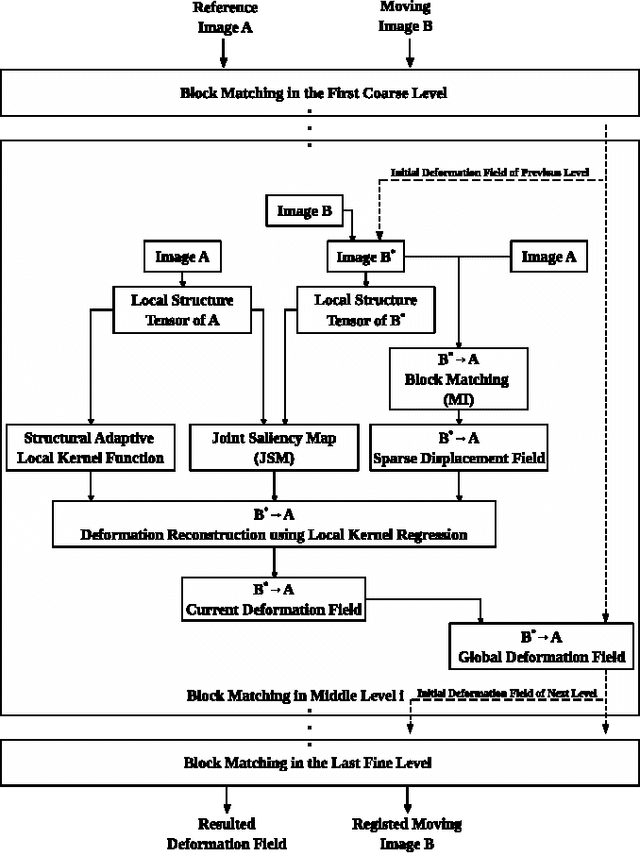

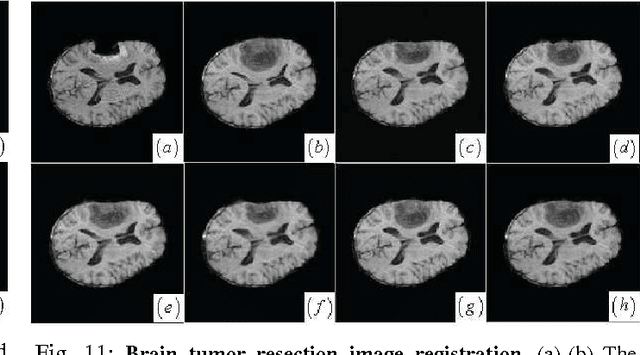

For nonrigid image registration, matching the particular structures (or the outliers) that have missing correspondence and/or local large deformations, can be more difficult than matching the common structures with small deformations in the two images. Most existing works depend heavily on the outlier segmentation to remove the outlier effect in the registration. Moreover, these works do not handle simultaneously the missing correspondences and local large deformations. In this paper, we defined the nonrigid image registration as a local adaptive kernel regression which locally reconstruct the moving image's dense deformation vectors from the sparse deformation vectors in the multi-resolution block matching. The kernel function of the kernel regression adapts its shape and orientation to the reference image's structure to gather more deformation vector samples of the same structure for the iterative regression computation, whereby the moving image's local deformations could be compliant with the reference image's local structures. To estimate the local deformations around the outliers, we use joint saliency map that highlights the corresponding saliency structures (called Joint Saliency Structures, JSSs) in the two images to guide the dense deformation reconstruction by emphasizing those JSSs' sparse deformation vectors in the kernel regression. The experimental results demonstrate that by using local JSS adaptive kernel regression, the proposed method achieves almost the best performance in alignment of all challenging image pairs with outlier structures compared with other five state-of-the-art nonrigid registration algorithms.
Scale Selection of Adaptive Kernel Regression by Joint Saliency Map for Nonrigid Image Registration
Apr 03, 2013

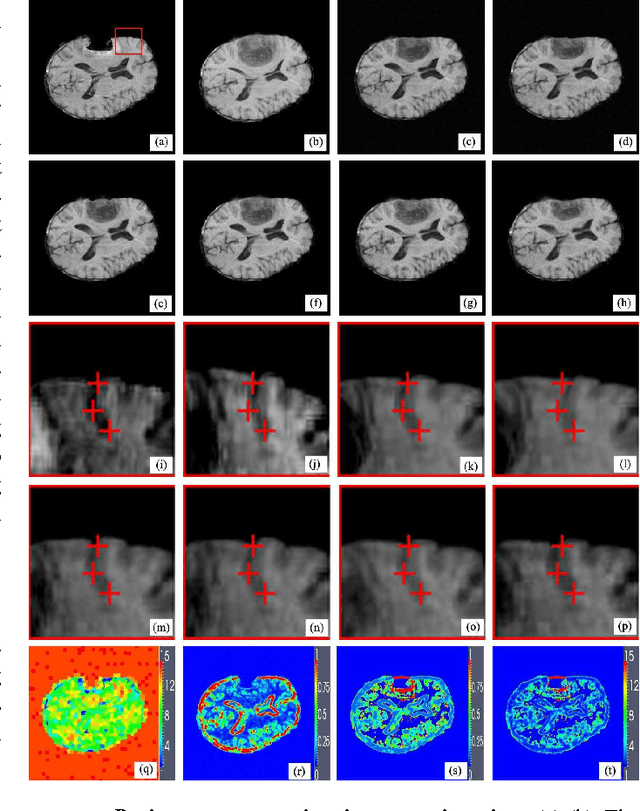

Joint saliency map (JSM) [1] was developed to assign high joint saliency values to the corresponding saliency structures (called Joint Saliency Structures, JSSs) but zero or low joint saliency values to the outliers (or mismatches) that are introduced by missing correspondence or local large deformations between the reference and moving images to be registered. JSM guides the local structure matching in nonrigid registration by emphasizing these JSSs' sparse deformation vectors in adaptive kernel regression of hierarchical sparse deformation vectors for iterative dense deformation reconstruction. By designing an effective superpixel-based local structure scale estimator to compute the reference structure's structure scale, we further propose to determine the scale (the width) of kernels in the adaptive kernel regression through combining the structure scales to JSM-based scales of mismatch between the local saliency structures. Therefore, we can adaptively select the sample size of sparse deformation vectors to reconstruct the dense deformation vectors for accurately matching the every local structures in the two images. The experimental results demonstrate better accuracy of our method in aligning two images with missing correspondence and local large deformation than the state-of-the-art methods.
Registration of Images with Outliers Using Joint Saliency Map
Mar 29, 2013



Mutual information (MI) is a popular similarity measure for image registration, whereby good registration can be achieved by maximizing the compactness of the clusters in the joint histogram. However, MI is sensitive to the "outlier" objects that appear in one image but not the other, and also suffers from local and biased maxima. We propose a novel joint saliency map (JSM) to highlight the corresponding salient structures in the two images, and emphatically group those salient structures into the smoothed compact clusters in the weighted joint histogram. This strategy could solve both the outlier and the local maxima problems. Experimental results show that the JSM-MI based algorithm is not only accurate but also robust for registration of challenging image pairs with outliers.