 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-unaware Lifelong Robot Learning with Retrieval-based Weighted Local Adaptation
Oct 03, 2024



Real-world environments require robots to continuously acquire new skills while retaining previously learned abilities, all without the need for clearly defined task boundaries. Storing all past data to prevent forgetting is impractical due to storage and privacy concerns. To address this, we propose a method that efficiently restores a robot's proficiency in previously learned tasks over its lifespan. Using an Episodic Memory (EM), our approach enables experience replay during training and retrieval during testing for local fine-tuning, allowing rapid adaptation to previously encountered problems without explicit task identifiers. Additionally, we introduce a selective weighting mechanism that emphasizes the most challenging segments of retrieved demonstrations, focusing local adaptation where it is most needed. This framework offers a scalable solution for lifelong learning in dynamic, task-unaware environments, combining retrieval-based adaptation with selective weighting to enhance robot performance in open-ended scenarios.
Potato: A Data-Oriented Programming 3D Simulator for Large-Scale Heterogeneous Swarm Robotics
Aug 24, 2023



Large-scale simulation with realistic nonlinear dynamic models is crucial for algorithms development for swarm robotics. However, existing platforms are mainly developed based on Object-Oriented Programming (OOP) and either use simple kinematic models to pursue a large number of simulating nodes or implement realistic dynamic models with limited simulating nodes. In this paper, we develop a simulator based on Data-Oriented Programming (DOP) that utilizes GPU parallel computing to achieve large-scale swarm robotic simulations. Specifically, we use a multi-process approach to simulate heterogeneous agents and leverage PyTorch with GPU to simulate homogeneous agents with a large number. We test our approach using a nonlinear quadrotor model and demonstrate that this DOP approach can maintain almost the same computational speed when quadrotors are less than 5,000. We also provide two examples to present the functionality of the platform.
Monocular Camera and Single-Beam Sonar-Based Underwater Collision-Free Navigation with Domain Randomization
Dec 08, 2022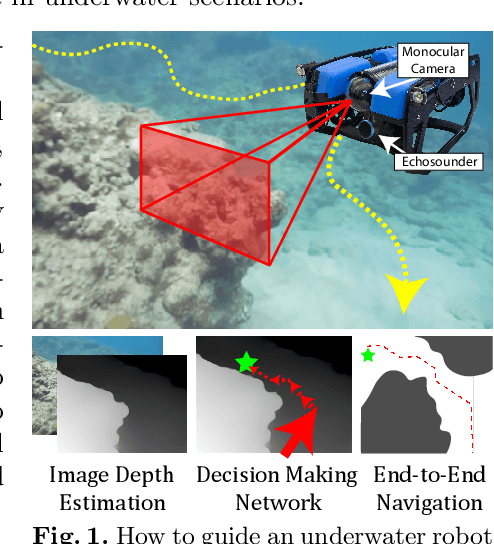

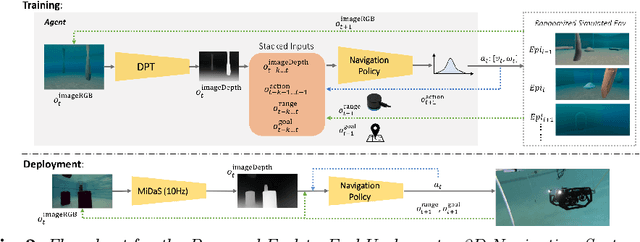

Underwater navigation presents several challenges, including unstructured unknown environments, lack of reliable localization systems (e.g., GPS), and poor visibility. Furthermore, good-quality obstacle detection sensors for underwater robots are scant and costly; and many sensors like RGB-D cameras and LiDAR only work in-air. To enable reliable mapless underwater navigation despite these challenges, we propose a low-cost end-to-end navigation system, based on a monocular camera and a fixed single-beam echo-sounder, that efficiently navigates an underwater robot to waypoints while avoiding nearby obstacles. Our proposed method is based on Proximal Policy Optimization (PPO), which takes as input current relative goal information, estimated depth images, echo-sounder readings, and previous executed actions, and outputs 3D robot actions in a normalized scale. End-to-end training was done in simulation, where we adopted domain randomization (varying underwater conditions and visibility) to learn a robust policy against noise and changes in visibility conditions. The experiments in simulation and real-world demonstrated that our proposed method is successful and resilient in navigating a low-cost underwater robot in unknown underwater environments. The implementation is made publicly available at https://github.com/dartmouthrobotics/deeprl-uw-robot-navigation.
Policy Learning for Active Target Tracking over Continuous SE(3) Trajectories
Dec 03, 2022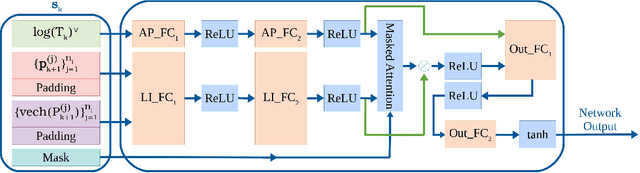
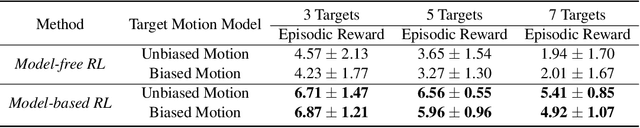
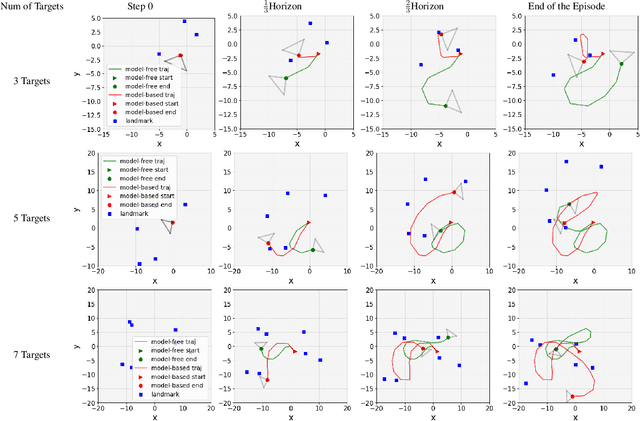
This paper proposes a novel model-based policy gradient algorithm for tracking dynamic targets using a mobile robot, equipped with an onboard sensor with limited field of view. The task is to obtain a continuous control policy for the mobile robot to collect sensor measurements that reduce uncertainty in the target states, measured by the target distribution entropy. We design a neural network control policy with the robot $SE(3)$ pose and the mean vector and information matrix of the joint target distribution as inputs and attention layers to handle variable numbers of targets. We also derive the gradient of the target entropy with respect to the network parameters explicitly, allowing efficient model-based policy gradient optimization.
Learning Continuous Control Policies for Information-Theoretic Active Perception
Sep 26, 2022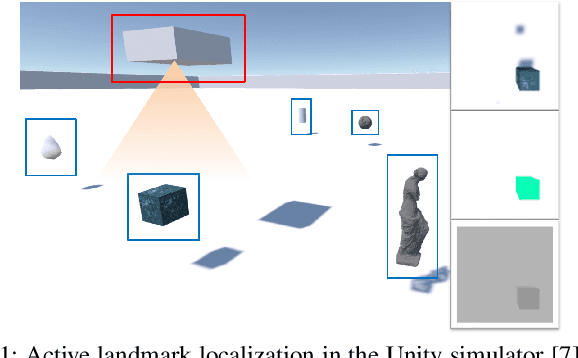
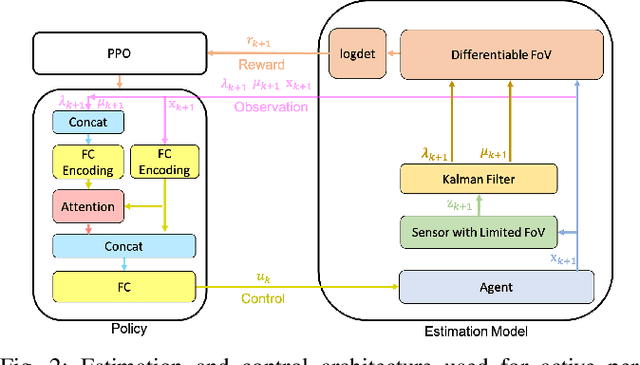
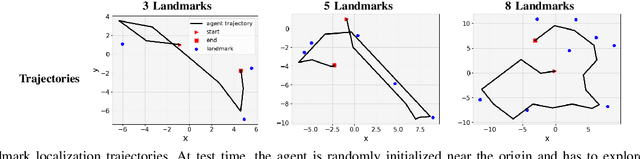
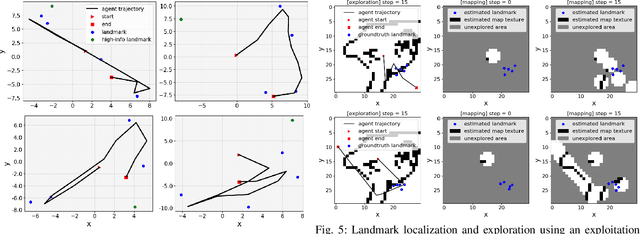
This paper proposes a method for learning continuous control policies for active landmark localization and exploration using an information-theoretic cost. We consider a mobile robot detecting landmarks within a limited sensing range, and tackle the problem of learning a control policy that maximizes the mutual information between the landmark states and the sensor observations. We employ a Kalman filter to convert the partially observable problem in the landmark state to Markov decision process (MDP), a differentiable field of view to shape the reward, and an attention-based neural network to represent the control policy. The approach is further unified with active volumetric mapping to promote exploration in addition to landmark localization. The performance is demonstrated in several simulated landmark localization tasks in comparison with benchmark methods.