 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-unaware Lifelong Robot Learning with Retrieval-based Weighted Local Adaptation
Oct 03, 2024



Real-world environments require robots to continuously acquire new skills while retaining previously learned abilities, all without the need for clearly defined task boundaries. Storing all past data to prevent forgetting is impractical due to storage and privacy concerns. To address this, we propose a method that efficiently restores a robot's proficiency in previously learned tasks over its lifespan. Using an Episodic Memory (EM), our approach enables experience replay during training and retrieval during testing for local fine-tuning, allowing rapid adaptation to previously encountered problems without explicit task identifiers. Additionally, we introduce a selective weighting mechanism that emphasizes the most challenging segments of retrieved demonstrations, focusing local adaptation where it is most needed. This framework offers a scalable solution for lifelong learning in dynamic, task-unaware environments, combining retrieval-based adaptation with selective weighting to enhance robot performance in open-ended scenarios.
Explaining Learned Reward Functions with Counterfactual Trajectories
Feb 07, 2024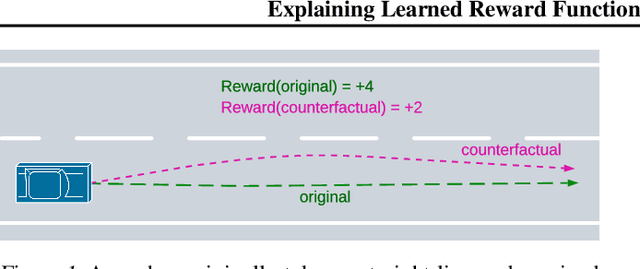
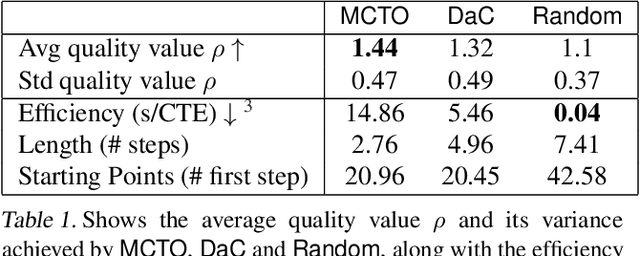


Learning rewards from human behaviour or feedback is a promising approach to aligning AI systems with human values but fails to consistently extract correct reward functions. Interpretability tools could enable users to understand and evaluate possible flaws in learned reward functions. We propose Counterfactual Trajectory Explanations (CTEs) to interpret reward functions in reinforcement learning by contrasting an original with a counterfactual partial trajectory and the rewards they each receive. We derive six quality criteria for CTEs and propose a novel Monte-Carlo-based algorithm for generating CTEs that optimises these quality criteria. Finally, we measure how informative the generated explanations are to a proxy-human model by training it on CTEs. CTEs are demonstrably informative for the proxy-human model, increasing the similarity between its predictions and the reward function on unseen trajectories. Further, it learns to accurately judge differences in rewards between trajectories and generalises to out-of-distribution examples. Although CTEs do not lead to a perfect understanding of the reward, our method, and more generally the adaptation of XAI methods, are presented as a fruitful approach for interpreting learned reward functions.
ReproducedPapers.org: Openly teaching and structuring machine learning reproducibility
Dec 01, 2020

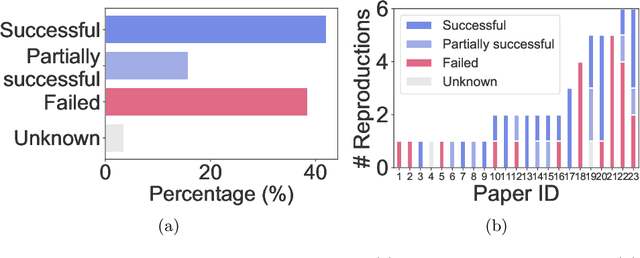
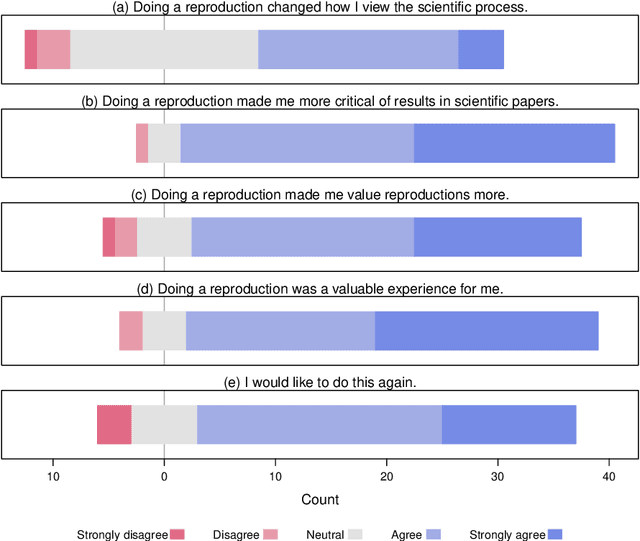
We present ReproducedPapers.org: an open online repository for teaching and structuring machine learning reproducibility. We evaluate doing a reproduction project among students and the added value of an online reproduction repository among AI researchers. We use anonymous self-assessment surveys and obtained 144 responses. Results suggest that students who do a reproduction project place more value on scientific reproductions and become more critical thinkers. Students and AI researchers agree that our online reproduction repository is valuable.
Maximizing Information Gain in Partially Observable Environments via Prediction Reward
May 11, 2020
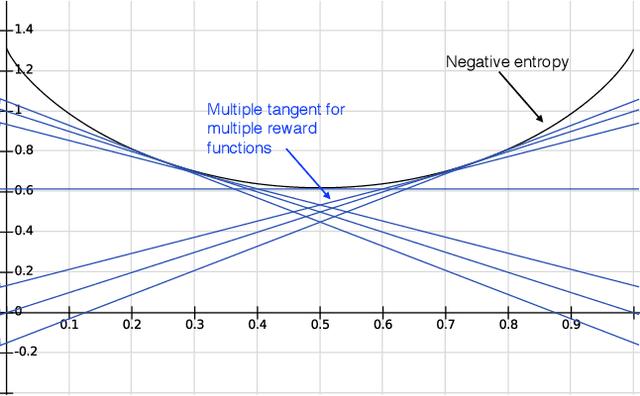
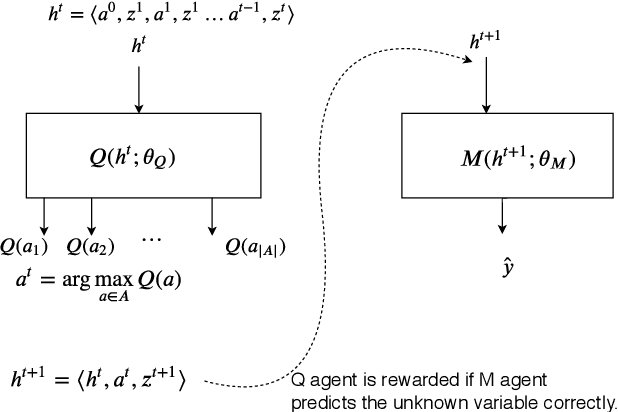
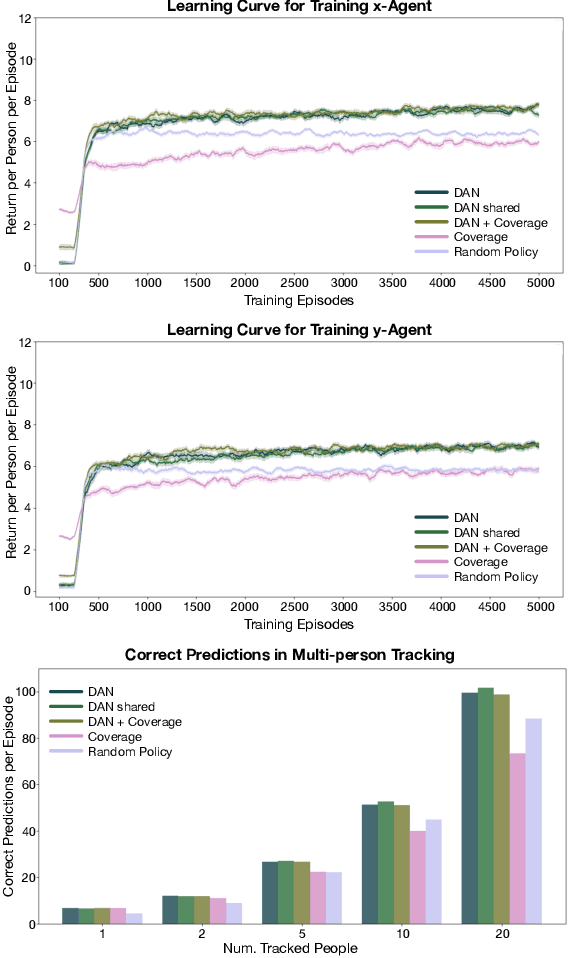
Information gathering in a partially observable environment can be formulated as a reinforcement learning (RL), problem where the reward depends on the agent's uncertainty. For example, the reward can be the negative entropy of the agent's belief over an unknown (or hidden) variable. Typically, the rewards of an RL agent are defined as a function of the state-action pairs and not as a function of the belief of the agent; this hinders the direct application of deep RL methods for such tasks. This paper tackles the challenge of using belief-based rewards for a deep RL agent, by offering a simple insight that maximizing any convex function of the belief of the agent can be approximated by instead maximizing a prediction reward: a reward based on prediction accuracy. In particular, we derive the exact error between negative entropy and the expected prediction reward. This insight provides theoretical motivation for several fields using prediction rewards---namely visual attention, question answering systems, and intrinsic motivation---and highlights their connection to the usually distinct fields of active perception, active sensing, and sensor placement. Based on this insight we present deep anticipatory networks (DANs), which enables an agent to take actions to reduce its uncertainty without performing explicit belief inference. We present two applications of DANs: building a sensor selection system for tracking people in a shopping mall and learning discrete models of attention on fashion MNIST and MNIST digit classification.
Decentralized MCTS via Learned Teammate Models
Mar 19, 2020


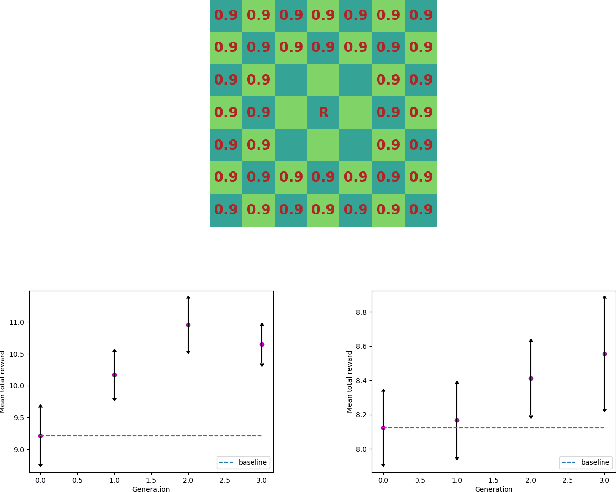
A key difficulty of cooperative decentralized planning lies in making accurate predictions about the decisions of other agents. In this paper we present a policy improvement operator for learning to plan in iterated cooperative multi-agent scenarios. At each application of our method, a selected agent learns an approximation of policies of its teammates from data from past simulations. Under the assumption of ideal function approximation, successive iterations of our algorithm are guaranteed to improve the policies, and eventually lead to convergence to a Nash equilibrium in a coordinate ascent manner. We combine the policy improvement operator with the decentralized Monte Carlo Tree Search planning method and demonstrate the application of the algorithm on several scenarios in the spatial task allocation problem introduced in (Claes et al., 2015). We show that deep learning and convolutional neural networks can be efficiently employed to produce policy approximators which exploit the spatial features of the problem, and that the proposed algorithm improves over the baseline planning performance for particularly challenging domain configurations.
Bayesian Reinforcement Learning in Factored POMDPs
Nov 14, 2018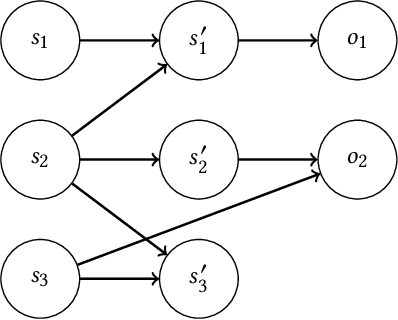

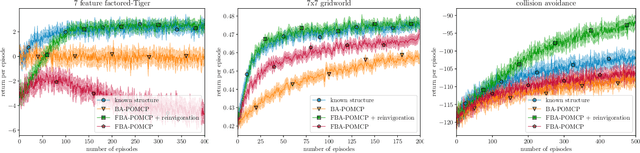

Bayesian approaches provide a principled solution to the exploration-exploitation trade-off in Reinforcement Learning. Typical approaches, however, either assume a fully observable environment or scale poorly. This work introduces the Factored Bayes-Adaptive POMDP model, a framework that is able to exploit the underlying structure while learning the dynamics in partially observable systems. We also present a belief tracking method to approximate the joint posterior over state and model variables, and an adaptation of the Monte-Carlo Tree Search solution method, which together are capable of solving the underlying problem near-optimally. Our method is able to learn efficiently given a known factorization or also learn the factorization and the model parameters at the same time. We demonstrate that this approach is able to outperform current methods and tackle problems that were previously infeasible.