 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbe-based Fine-tuning for Reducing Toxicity
Oct 24, 2025Probes trained on model activations can detect undesirable behaviors like deception or biases that are difficult to identify from outputs alone. This makes them useful detectors to identify misbehavior. Furthermore, they are also valuable training signals, since they not only reward outputs, but also good internal processes for arriving at that output. However, training against interpretability tools raises a fundamental concern: when a monitor becomes a training target, it may cease to be reliable (Goodhart's Law). We propose two methods for training against probes based on Supervised Fine-tuning and Direct Preference Optimization. We conduct an initial exploration of these methods in a testbed for reducing toxicity and evaluate the amount by which probe accuracy drops when training against them. To retain the accuracy of probe-detectors after training, we attempt (1) to train against an ensemble of probes, (2) retain held-out probes that aren't used for training, and (3) retrain new probes after training. First, probe-based preference optimization unexpectedly preserves probe detectability better than classifier-based methods, suggesting the preference learning objective incentivizes maintaining rather than obfuscating relevant representations. Second, probe diversity provides minimal practical benefit - simply retraining probes after optimization recovers high detection accuracy. Our findings suggest probe-based training can be viable for certain alignment methods, though probe ensembles are largely unnecessary when retraining is feasible.
Taxonomy, Opportunities, and Challenges of Representation Engineering for Large Language Models
Feb 27, 2025Representation Engineering (RepE) is a novel paradigm for controlling the behavior of LLMs. Unlike traditional approaches that modify inputs or fine-tune the model, RepE directly manipulates the model's internal representations. As a result, it may offer more effective, interpretable, data-efficient, and flexible control over models' behavior. We present the first comprehensive survey of RepE for LLMs, reviewing the rapidly growing literature to address key questions: What RepE methods exist and how do they differ? For what concepts and problems has RepE been applied? What are the strengths and weaknesses of RepE compared to other methods? To answer these, we propose a unified framework describing RepE as a pipeline comprising representation identification, operationalization, and control. We posit that while RepE methods offer significant potential, challenges remain, including managing multiple concepts, ensuring reliability, and preserving models' performance. Towards improving RepE, we identify opportunities for experimental and methodological improvements and construct a guide for best practices.
Safety is Essential for Responsible Open-Ended Systems
Feb 06, 2025
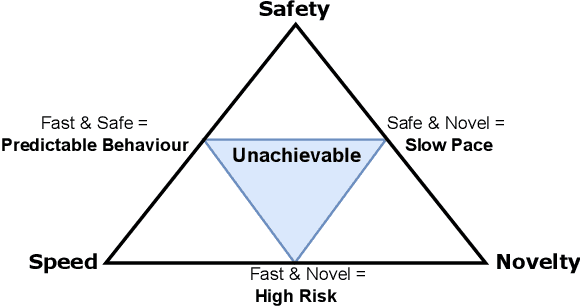
AI advancements have been significantly driven by a combination of foundation models and curiosity-driven learning aimed at increasing capability and adaptability. A growing area of interest within this field is Open-Endedness - the ability of AI systems to continuously and autonomously generate novel and diverse artifacts or solutions. This has become relevant for accelerating scientific discovery and enabling continual adaptation in AI agents. This position paper argues that the inherently dynamic and self-propagating nature of Open-Ended AI introduces significant, underexplored risks, including challenges in maintaining alignment, predictability, and control. This paper systematically examines these challenges, proposes mitigation strategies, and calls for action for different stakeholders to support the safe, responsible and successful development of Open-Ended AI.
Representation noising effectively prevents harmful fine-tuning on LLMs
May 23, 2024



Releasing open-source large language models (LLMs) presents a dual-use risk since bad actors can easily fine-tune these models for harmful purposes. Even without the open release of weights, weight stealing and fine-tuning APIs make closed models vulnerable to harmful fine-tuning attacks (HFAs). While safety measures like preventing jailbreaks and improving safety guardrails are important, such measures can easily be reversed through fine-tuning. In this work, we propose Representation Noising (RepNoise), a defence mechanism that is effective even when attackers have access to the weights and the defender no longer has any control. RepNoise works by removing information about harmful representations such that it is difficult to recover them during fine-tuning. Importantly, our defence is also able to generalize across different subsets of harm that have not been seen during the defence process. Our method does not degrade the general capability of LLMs and retains the ability to train the model on harmless tasks. We provide empirical evidence that the effectiveness of our defence lies in its "depth": the degree to which information about harmful representations is removed across all layers of the LLM.
Immunization against harmful fine-tuning attacks
Feb 26, 2024Approaches to aligning large language models (LLMs) with human values has focused on correcting misalignment that emerges from pretraining. However, this focus overlooks another source of misalignment: bad actors might purposely fine-tune LLMs to achieve harmful goals. In this paper, we present an emerging threat model that has arisen from alignment circumvention and fine-tuning attacks. However, lacking in previous works is a clear presentation of the conditions for effective defence. We propose a set of conditions for effective defence against harmful fine-tuning in LLMs called "Immunization conditions," which help us understand how we would construct and measure future defences. Using this formal framework for defence, we offer a synthesis of different research directions that might be persued to prevent harmful fine-tuning attacks and provide a demonstration of how to use these conditions experimentally showing early results of using an adversarial loss to immunize LLama2-7b-chat.
Explaining Learned Reward Functions with Counterfactual Trajectories
Feb 07, 2024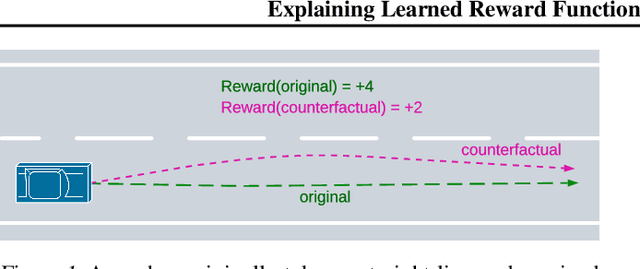


Learning rewards from human behaviour or feedback is a promising approach to aligning AI systems with human values but fails to consistently extract correct reward functions. Interpretability tools could enable users to understand and evaluate possible flaws in learned reward functions. We propose Counterfactual Trajectory Explanations (CTEs) to interpret reward functions in reinforcement learning by contrasting an original with a counterfactual partial trajectory and the rewards they each receive. We derive six quality criteria for CTEs and propose a novel Monte-Carlo-based algorithm for generating CTEs that optimises these quality criteria. Finally, we measure how informative the generated explanations are to a proxy-human model by training it on CTEs. CTEs are demonstrably informative for the proxy-human model, increasing the similarity between its predictions and the reward function on unseen trajectories. Further, it learns to accurately judge differences in rewards between trajectories and generalises to out-of-distribution examples. Although CTEs do not lead to a perfect understanding of the reward, our method, and more generally the adaptation of XAI methods, are presented as a fruitful approach for interpreting learned reward functions.