 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractional Fairness in LLM Multi-Agent Systems: An Evaluation Framework
May 17, 2025As large language models (LLMs) are increasingly used in multi-agent systems, questions of fairness should extend beyond resource distribution and procedural design to include the fairness of how agents communicate. Drawing from organizational psychology, we introduce a novel framework for evaluating Interactional fairness encompassing Interpersonal fairness (IF) and Informational fairness (InfF) in LLM-based multi-agent systems (LLM-MAS). We extend the theoretical grounding of Interactional Fairness to non-sentient agents, reframing fairness as a socially interpretable signal rather than a subjective experience. We then adapt established tools from organizational justice research, including Colquitt's Organizational Justice Scale and the Critical Incident Technique, to measure fairness as a behavioral property of agent interaction. We validate our framework through a pilot study using controlled simulations of a resource negotiation task. We systematically manipulate tone, explanation quality, outcome inequality, and task framing (collaborative vs. competitive) to assess how IF influences agent behavior. Results show that tone and justification quality significantly affect acceptance decisions even when objective outcomes are held constant. In addition, the influence of IF vs. InfF varies with context. This work lays the foundation for fairness auditing and norm-sensitive alignment in LLM-MAS.
Causality Is Key to Understand and Balance Multiple Goals in Trustworthy ML and Foundation Models
Feb 28, 2025Ensuring trustworthiness in machine learning (ML) systems is crucial as they become increasingly embedded in high-stakes domains. This paper advocates for the integration of causal methods into machine learning to navigate the trade-offs among key principles of trustworthy ML, including fairness, privacy, robustness, accuracy, and explainability. While these objectives should ideally be satisfied simultaneously, they are often addressed in isolation, leading to conflicts and suboptimal solutions. Drawing on existing applications of causality in ML that successfully align goals such as fairness and accuracy or privacy and robustness, this paper argues that a causal approach is essential for balancing multiple competing objectives in both trustworthy ML and foundation models. Beyond highlighting these trade-offs, we examine how causality can be practically integrated into ML and foundation models, offering solutions to enhance their reliability and interpretability. Finally, we discuss the challenges, limitations, and opportunities in adopting causal frameworks, paving the way for more accountable and ethically sound AI systems.
Safety is Essential for Responsible Open-Ended Systems
Feb 06, 2025
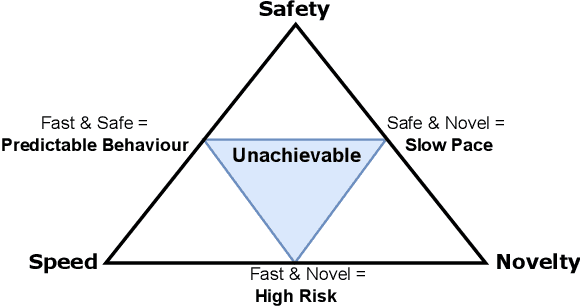
AI advancements have been significantly driven by a combination of foundation models and curiosity-driven learning aimed at increasing capability and adaptability. A growing area of interest within this field is Open-Endedness - the ability of AI systems to continuously and autonomously generate novel and diverse artifacts or solutions. This has become relevant for accelerating scientific discovery and enabling continual adaptation in AI agents. This position paper argues that the inherently dynamic and self-propagating nature of Open-Ended AI introduces significant, underexplored risks, including challenges in maintaining alignment, predictability, and control. This paper systematically examines these challenges, proposes mitigation strategies, and calls for action for different stakeholders to support the safe, responsible and successful development of Open-Ended AI.
LLM4GRN: Discovering Causal Gene Regulatory Networks with LLMs -- Evaluation through Synthetic Data Generation
Oct 21, 2024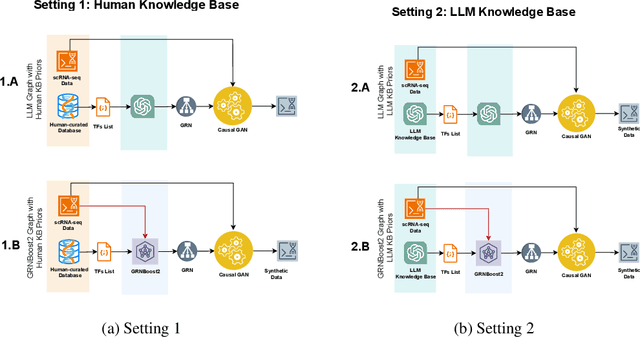



Gene regulatory networks (GRNs) represent the causal relationships between transcription factors (TFs) and target genes in single-cell RNA sequencing (scRNA-seq) data. Understanding these networks is crucial for uncovering disease mechanisms and identifying therapeutic targets. In this work, we investigate the potential of large language models (LLMs) for GRN discovery, leveraging their learned biological knowledge alone or in combination with traditional statistical methods. We develop a task-based evaluation strategy to address the challenge of unavailable ground truth causal graphs. Specifically, we use the GRNs suggested by LLMs to guide causal synthetic data generation and compare the resulting data against the original dataset. Our statistical and biological assessments show that LLMs can support statistical modeling and data synthesis for biological research.
BaBE: Enhancing Fairness via Estimation of Latent Explaining Variables
Jul 06, 2023



We consider the problem of unfair discrimination between two groups and propose a pre-processing method to achieve fairness. Corrective methods like statistical parity usually lead to bad accuracy and do not really achieve fairness in situations where there is a correlation between the sensitive attribute S and the legitimate attribute E (explanatory variable) that should determine the decision. To overcome these drawbacks, other notions of fairness have been proposed, in particular, conditional statistical parity and equal opportunity. However, E is often not directly observable in the data, i.e., it is a latent variable. We may observe some other variable Z representing E, but the problem is that Z may also be affected by S, hence Z itself can be biased. To deal with this problem, we propose BaBE (Bayesian Bias Elimination), an approach based on a combination of Bayes inference and the Expectation-Maximization method, to estimate the most likely value of E for a given Z for each group. The decision can then be based directly on the estimated E. We show, by experiments on synthetic and real data sets, that our approach provides a good level of fairness as well as high accuracy.