 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Consistency and Performance of the Iterative Bayesian Update
Aug 13, 2025



For many social, scientific, and commercial purposes, it is often important to estimate the distribution of the users' data regarding a sensitive attribute, e.g., their ages, locations, etc. To allow this estimation while protecting the users' privacy, every user applies a local privacy protection mechanism that releases a noisy (sanitized) version of their original datum to the data collector; then the original distribution is estimated using one of the known methods, such as the matrix inversion (INV), RAPPOR's estimator, and the iterative Bayesian update (IBU). Unlike the other estimators, the consistency of IBU, i.e., the convergence of its estimate to the real distribution as the amount of noisy data grows, has been either ignored or incorrectly proved in the literature. In this article, we use the fact that IBU is a maximum likelihood estimator to prove that IBU is consistent. We also show, through experiments on real datasets, that IBU significantly outperforms the other methods when the users' data are sanitized by geometric, Laplace, and exponential mechanisms, whereas it is comparable to the other methods in the case of the k-RR and RAPPOR mechanisms. Finally, we consider the case when the alphabet of the sensitive data is infinite, and we show a technique that allows IBU to operate in this case too.
Mitigating Membership Inference Vulnerability in Personalized Federated Learning
Mar 12, 2025Federated Learning (FL) has emerged as a promising paradigm for collaborative model training without the need to share clients' personal data, thereby preserving privacy. However, the non-IID nature of the clients' data introduces major challenges for FL, highlighting the importance of personalized federated learning (PFL) methods. In PFL, models are trained to cater to specific feature distributions present in the population data. A notable method for PFL is the Iterative Federated Clustering Algorithm (IFCA), which mitigates the concerns associated with the non-IID-ness by grouping clients with similar data distributions. While it has been shown that IFCA enhances both accuracy and fairness, its strategy of dividing the population into smaller clusters increases vulnerability to Membership Inference Attacks (MIA), particularly among minorities with limited training samples. In this paper, we introduce IFCA-MIR, an improved version of IFCA that integrates MIA risk assessment into the clustering process. Allowing clients to select clusters based on both model performance and MIA vulnerability, IFCA-MIR achieves an improved performance with respect to accuracy, fairness, and privacy. We demonstrate that IFCA-MIR significantly reduces MIA risk while maintaining comparable model accuracy and fairness as the original IFCA.
Jeffrey's update rule as a minimizer of Kullback-Leibler divergence
Feb 21, 2025In this paper, we show a more concise and high level proof than the original one, derived by researcher Bart Jacobs, for the following theorem: in the context of Bayesian update rules for learning or updating internal states that produce predictions, the relative entropy between the observations and the predictions is reduced when applying Jeffrey's update rule to update the internal state.
Comparing privacy notions for protection against reconstruction attacks in machine learning
Feb 06, 2025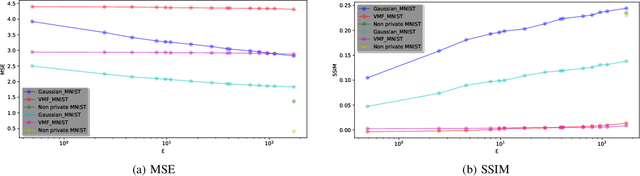



Within the machine learning community, reconstruction attacks are a principal concern and have been identified even in federated learning (FL), which was designed with privacy preservation in mind. In response to these threats, the privacy community recommends the use of differential privacy (DP) in the stochastic gradient descent algorithm, termed DP-SGD. However, the proliferation of variants of DP in recent years\textemdash such as metric privacy\textemdash has made it challenging to conduct a fair comparison between different mechanisms due to the different meanings of the privacy parameters $\epsilon$ and $\delta$ across different variants. Thus, interpreting the practical implications of $\epsilon$ and $\delta$ in the FL context and amongst variants of DP remains ambiguous. In this paper, we lay a foundational framework for comparing mechanisms with differing notions of privacy guarantees, namely $(\epsilon,\delta)$-DP and metric privacy. We provide two foundational means of comparison: firstly, via the well-established $(\epsilon,\delta)$-DP guarantees, made possible through the R\'enyi differential privacy framework; and secondly, via Bayes' capacity, which we identify as an appropriate measure for reconstruction threats.
Metric Privacy in Federated Learning for Medical Imaging: Improving Convergence and Preventing Client Inference Attacks
Feb 03, 2025
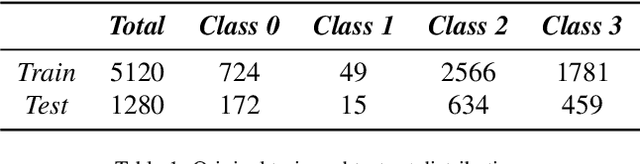
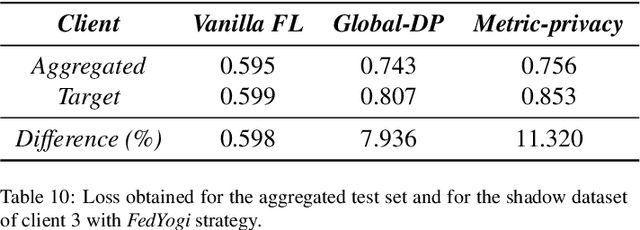
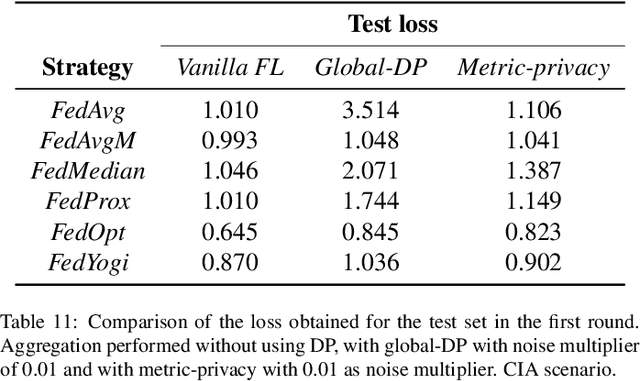
Federated learning is a distributed learning technique that allows training a global model with the participation of different data owners without the need to share raw data. This architecture is orchestrated by a central server that aggregates the local models from the clients. This server may be trusted, but not all nodes in the network. Then, differential privacy (DP) can be used to privatize the global model by adding noise. However, this may affect convergence across the rounds of the federated architecture, depending also on the aggregation strategy employed. In this work, we aim to introduce the notion of metric-privacy to mitigate the impact of classical server side global-DP on the convergence of the aggregated model. Metric-privacy is a relaxation of DP, suitable for domains provided with a notion of distance. We apply it from the server side by computing a distance for the difference between the local models. We compare our approach with standard DP by analyzing the impact on six classical aggregation strategies. The proposed methodology is applied to an example of medical imaging and different scenarios are simulated across homogeneous and non-i.i.d clients. Finally, we introduce a novel client inference attack, where a semi-honest client tries to find whether another client participated in the training and study how it can be mitigated using DP and metric-privacy. Our evaluation shows that metric-privacy can increase the performance of the model compared to standard DP, while offering similar protection against client inference attacks.
Bayes' capacity as a measure for reconstruction attacks in federated learning
Jun 19, 2024

Within the machine learning community, reconstruction attacks are a principal attack of concern and have been identified even in federated learning, which was designed with privacy preservation in mind. In federated learning, it has been shown that an adversary with knowledge of the machine learning architecture is able to infer the exact value of a training element given an observation of the weight updates performed during stochastic gradient descent. In response to these threats, the privacy community recommends the use of differential privacy in the stochastic gradient descent algorithm, termed DP-SGD. However, DP has not yet been formally established as an effective countermeasure against reconstruction attacks. In this paper, we formalise the reconstruction threat model using the information-theoretic framework of quantitative information flow. We show that the Bayes' capacity, related to the Sibson mutual information of order infinity, represents a tight upper bound on the leakage of the DP-SGD algorithm to an adversary interested in performing a reconstruction attack. We provide empirical results demonstrating the effectiveness of this measure for comparing mechanisms against reconstruction threats.
A Systematic and Formal Study of the Impact of Local Differential Privacy on Fairness: Preliminary Results
May 23, 2024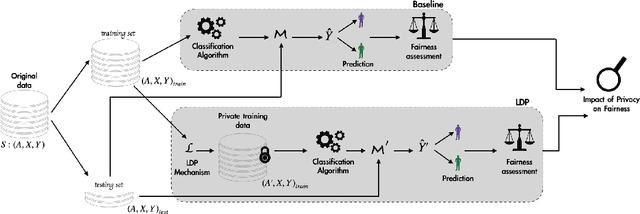


Machine learning (ML) algorithms rely primarily on the availability of training data, and, depending on the domain, these data may include sensitive information about the data providers, thus leading to significant privacy issues. Differential privacy (DP) is the predominant solution for privacy-preserving ML, and the local model of DP is the preferred choice when the server or the data collector are not trusted. Recent experimental studies have shown that local DP can impact ML prediction for different subgroups of individuals, thus affecting fair decision-making. However, the results are conflicting in the sense that some studies show a positive impact of privacy on fairness while others show a negative one. In this work, we conduct a systematic and formal study of the effect of local DP on fairness. Specifically, we perform a quantitative study of how the fairness of the decisions made by the ML model changes under local DP for different levels of privacy and data distributions. In particular, we provide bounds in terms of the joint distributions and the privacy level, delimiting the extent to which local DP can impact the fairness of the model. We characterize the cases in which privacy reduces discrimination and those with the opposite effect. We validate our theoretical findings on synthetic and real-world datasets. Our results are preliminary in the sense that, for now, we study only the case of one sensitive attribute, and only statistical disparity, conditional statistical disparity, and equal opportunity difference.
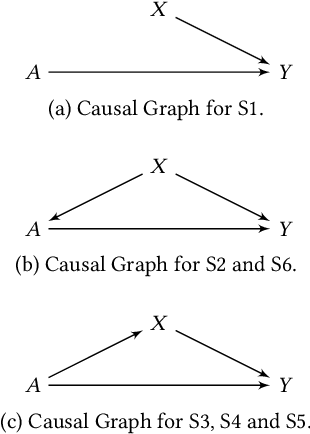
On the Impact of Multi-dimensional Local Differential Privacy on Fairness
Dec 08, 2023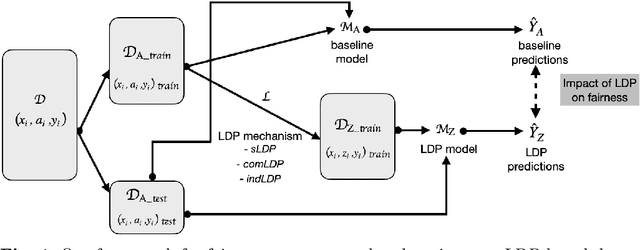



Automated decision systems are increasingly used to make consequential decisions in people's lives. Due to the sensitivity of the manipulated data as well as the resulting decisions, several ethical concerns need to be addressed for the appropriate use of such technologies, in particular, fairness and privacy. Unlike previous work, which focused on centralized differential privacy (DP) or local DP (LDP) for a single sensitive attribute, in this paper, we examine the impact of LDP in the presence of several sensitive attributes (i.e., multi-dimensional data) on fairness. Detailed empirical analysis on synthetic and benchmark datasets revealed very relevant observations. In particular, (1) multi-dimensional LDP is an efficient approach to reduce disparity, (2) the multi-dimensional approach of LDP (independent vs. combined) matters only at low privacy guarantees, and (3) the outcome Y distribution has an important effect on which group is more sensitive to the obfuscation. Last, we summarize our findings in the form of recommendations to guide practitioners in adopting effective privacy-preserving practices while maintaining fairness and utility in ML applications.
Causal Discovery Under Local Privacy
Nov 15, 2023Differential privacy is a widely adopted framework designed to safeguard the sensitive information of data providers within a data set. It is based on the application of controlled noise at the interface between the server that stores and processes the data, and the data consumers. Local differential privacy is a variant that allows data providers to apply the privatization mechanism themselves on their data individually. Therefore it provides protection also in contexts in which the server, or even the data collector, cannot be trusted. The introduction of noise, however, inevitably affects the utility of the data, particularly by distorting the correlations between individual data components. This distortion can prove detrimental to tasks such as causal discovery. In this paper, we consider various well-known locally differentially private mechanisms and compare the trade-off between the privacy they provide, and the accuracy of the causal structure produced by algorithms for causal learning when applied to data obfuscated by these mechanisms. Our analysis yields valuable insights for selecting appropriate local differentially private protocols for causal discovery tasks. We foresee that our findings will aid researchers and practitioners in conducting locally private causal discovery.
Online Sensitivity Optimization in Differentially Private Learning
Oct 02, 2023



Training differentially private machine learning models requires constraining an individual's contribution to the optimization process. This is achieved by clipping the $2$-norm of their gradient at a predetermined threshold prior to averaging and batch sanitization. This selection adversely influences optimization in two opposing ways: it either exacerbates the bias due to excessive clipping at lower values, or augments sanitization noise at higher values. The choice significantly hinges on factors such as the dataset, model architecture, and even varies within the same optimization, demanding meticulous tuning usually accomplished through a grid search. In order to circumvent the privacy expenses incurred in hyperparameter tuning, we present a novel approach to dynamically optimize the clipping threshold. We treat this threshold as an additional learnable parameter, establishing a clean relationship between the threshold and the cost function. This allows us to optimize the former with gradient descent, with minimal repercussions on the overall privacy analysis. Our method is thoroughly assessed against alternative fixed and adaptive strategies across diverse datasets, tasks, model dimensions, and privacy levels. Our results demonstrate its comparable or superior performance in all evaluated scenarios, given the same privacy requirements.