 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy Neighbors: Efficient membership inference attacks against LLMs
Jun 24, 2024
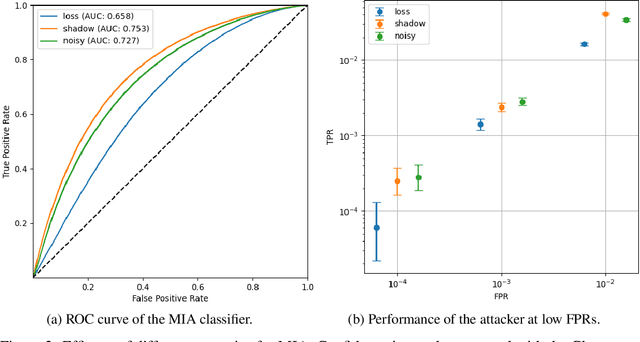

The potential of transformer-based LLMs risks being hindered by privacy concerns due to their reliance on extensive datasets, possibly including sensitive information. Regulatory measures like GDPR and CCPA call for using robust auditing tools to address potential privacy issues, with Membership Inference Attacks (MIA) being the primary method for assessing LLMs' privacy risks. Differently from traditional MIA approaches, often requiring computationally intensive training of additional models, this paper introduces an efficient methodology that generates \textit{noisy neighbors} for a target sample by adding stochastic noise in the embedding space, requiring operating the target model in inference mode only. Our findings demonstrate that this approach closely matches the effectiveness of employing shadow models, showing its usability in practical privacy auditing scenarios.
Online Sensitivity Optimization in Differentially Private Learning
Oct 02, 2023



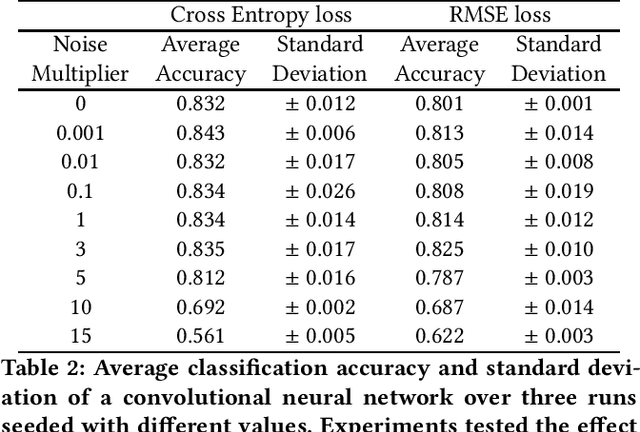
Training differentially private machine learning models requires constraining an individual's contribution to the optimization process. This is achieved by clipping the $2$-norm of their gradient at a predetermined threshold prior to averaging and batch sanitization. This selection adversely influences optimization in two opposing ways: it either exacerbates the bias due to excessive clipping at lower values, or augments sanitization noise at higher values. The choice significantly hinges on factors such as the dataset, model architecture, and even varies within the same optimization, demanding meticulous tuning usually accomplished through a grid search. In order to circumvent the privacy expenses incurred in hyperparameter tuning, we present a novel approach to dynamically optimize the clipping threshold. We treat this threshold as an additional learnable parameter, establishing a clean relationship between the threshold and the cost function. This allows us to optimize the former with gradient descent, with minimal repercussions on the overall privacy analysis. Our method is thoroughly assessed against alternative fixed and adaptive strategies across diverse datasets, tasks, model dimensions, and privacy levels. Our results demonstrate its comparable or superior performance in all evaluated scenarios, given the same privacy requirements.
Advancing Personalized Federated Learning: Group Privacy, Fairness, and Beyond
Sep 01, 2023Federated learning (FL) is a framework for training machine learning models in a distributed and collaborative manner. During training, a set of participating clients process their data stored locally, sharing only the model updates obtained by minimizing a cost function over their local inputs. FL was proposed as a stepping-stone towards privacy-preserving machine learning, but it has been shown vulnerable to issues such as leakage of private information, lack of personalization of the model, and the possibility of having a trained model that is fairer to some groups than to others. In this paper, we address the triadic interaction among personalization, privacy guarantees, and fairness attained by models trained within the FL framework. Differential privacy and its variants have been studied and applied as cutting-edge standards for providing formal privacy guarantees. However, clients in FL often hold very diverse datasets representing heterogeneous communities, making it important to protect their sensitive information while still ensuring that the trained model upholds the aspect of fairness for the users. To attain this objective, a method is put forth that introduces group privacy assurances through the utilization of $d$-privacy (aka metric privacy). $d$-privacy represents a localized form of differential privacy that relies on a metric-oriented obfuscation approach to maintain the original data's topological distribution. This method, besides enabling personalized model training in a federated approach and providing formal privacy guarantees, possesses significantly better group fairness measured under a variety of standard metrics than a global model trained within a classical FL template. Theoretical justifications for the applicability are provided, as well as experimental validation on real-world datasets to illustrate the working of the proposed method.
Group privacy for personalized federated learning
Jun 07, 2022
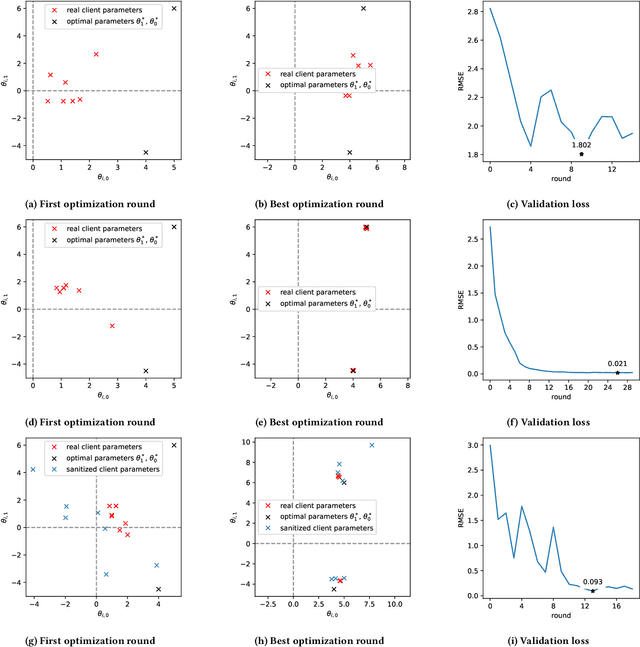

Federated learning is a type of collaborative machine learning, where participating clients process their data locally, sharing only updates to the collaborative model. This enables to build privacy-aware distributed machine learning models, among others. The goal is the optimization of a statistical model's parameters by minimizing a cost function of a collection of datasets which are stored locally by a set of clients. This process exposes the clients to two issues: leakage of private information and lack of personalization of the model. On the other hand, with the recent advancements in techniques to analyze data, there is a surge of concern for the privacy violation of the participating clients. To mitigate this, differential privacy and its variants serve as a standard for providing formal privacy guarantees. Often the clients represent very heterogeneous communities and hold data which are very diverse. Therefore, aligned with the recent focus of the FL community to build a framework of personalized models for the users representing their diversity, it is also of utmost importance to protect against potential threats against the sensitive and personal information of the clients. $d$-privacy, which is a generalization of geo-indistinguishability, the lately popularized paradigm of location privacy, uses a metric-based obfuscation technique that preserves the spatial distribution of the original data. To address the issue of protecting the privacy of the clients and allowing for personalized model training to enhance the fairness and utility of the system, we propose a method to provide group privacy guarantees exploiting some key properties of $d$-privacy which enables personalized models under the framework of FL. We provide with theoretical justifications to the applicability and experimental validation on real-world datasets to illustrate the working of the proposed method.
Predictive Auto-scaling with OpenStack Monasca
Nov 03, 2021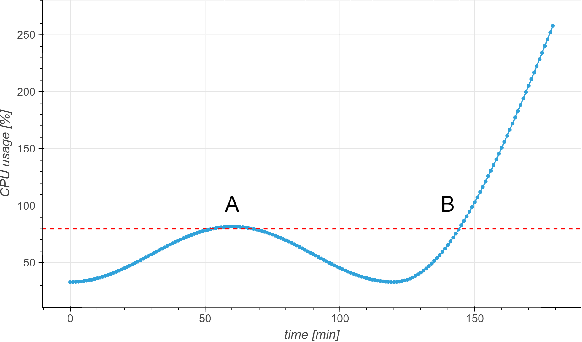
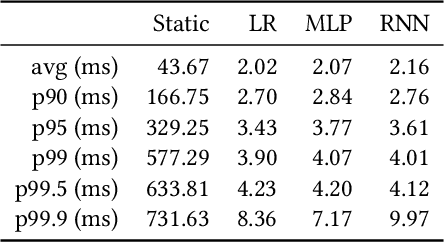

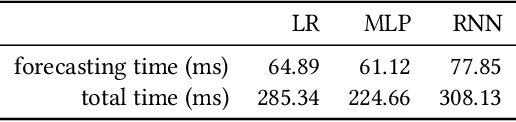
Cloud auto-scaling mechanisms are typically based on reactive automation rules that scale a cluster whenever some metric, e.g., the average CPU usage among instances, exceeds a predefined threshold. Tuning these rules becomes particularly cumbersome when scaling-up a cluster involves non-negligible times to bootstrap new instances, as it happens frequently in production cloud services. To deal with this problem, we propose an architecture for auto-scaling cloud services based on the status in which the system is expected to evolve in the near future. Our approach leverages on time-series forecasting techniques, like those based on machine learning and artificial neural networks, to predict the future dynamics of key metrics, e.g., resource consumption metrics, and apply a threshold-based scaling policy on them. The result is a predictive automation policy that is able, for instance, to automatically anticipate peaks in the load of a cloud application and trigger ahead of time appropriate scaling actions to accommodate the expected increase in traffic. We prototyped our approach as an open-source OpenStack component, which relies on, and extends, the monitoring capabilities offered by Monasca, resulting in the addition of predictive metrics that can be leveraged by orchestration components like Heat or Senlin. We show experimental results using a recurrent neural network and a multi-layer perceptron as predictor, which are compared with a simple linear regression and a traditional non-predictive auto-scaling policy. However, the proposed framework allows for the easy customization of the prediction policy as needed.