 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Auto-scaling with OpenStack Monasca
Paper and Code
Nov 03, 2021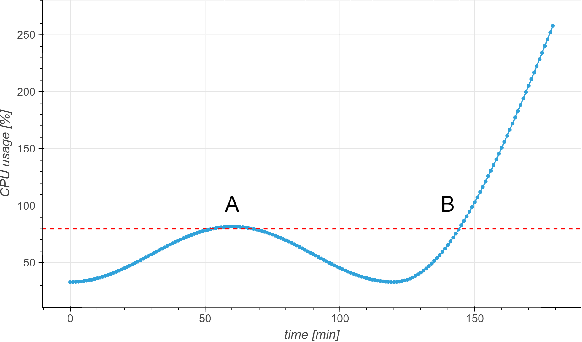
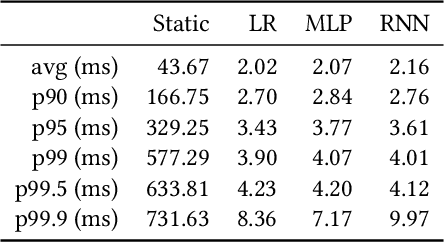

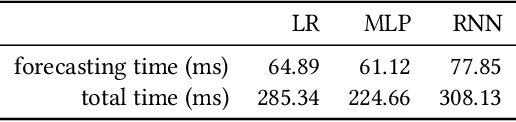
Cloud auto-scaling mechanisms are typically based on reactive automation rules that scale a cluster whenever some metric, e.g., the average CPU usage among instances, exceeds a predefined threshold. Tuning these rules becomes particularly cumbersome when scaling-up a cluster involves non-negligible times to bootstrap new instances, as it happens frequently in production cloud services. To deal with this problem, we propose an architecture for auto-scaling cloud services based on the status in which the system is expected to evolve in the near future. Our approach leverages on time-series forecasting techniques, like those based on machine learning and artificial neural networks, to predict the future dynamics of key metrics, e.g., resource consumption metrics, and apply a threshold-based scaling policy on them. The result is a predictive automation policy that is able, for instance, to automatically anticipate peaks in the load of a cloud application and trigger ahead of time appropriate scaling actions to accommodate the expected increase in traffic. We prototyped our approach as an open-source OpenStack component, which relies on, and extends, the monitoring capabilities offered by Monasca, resulting in the addition of predictive metrics that can be leveraged by orchestration components like Heat or Senlin. We show experimental results using a recurrent neural network and a multi-layer perceptron as predictor, which are compared with a simple linear regression and a traditional non-predictive auto-scaling policy. However, the proposed framework allows for the easy customization of the prediction policy as needed.