 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCogMem: A Cognitive Memory Architecture for Sustained Multi-Turn Reasoning in Large Language Models
Dec 16, 2025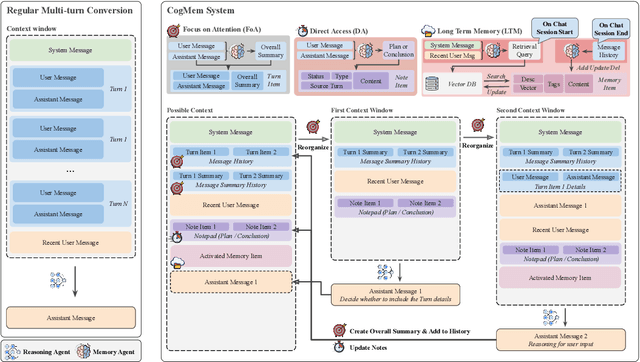
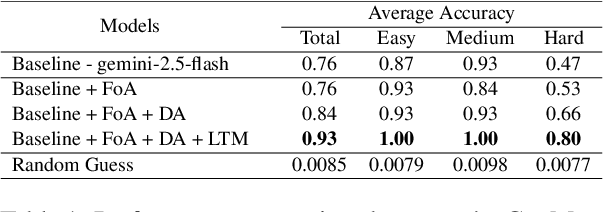
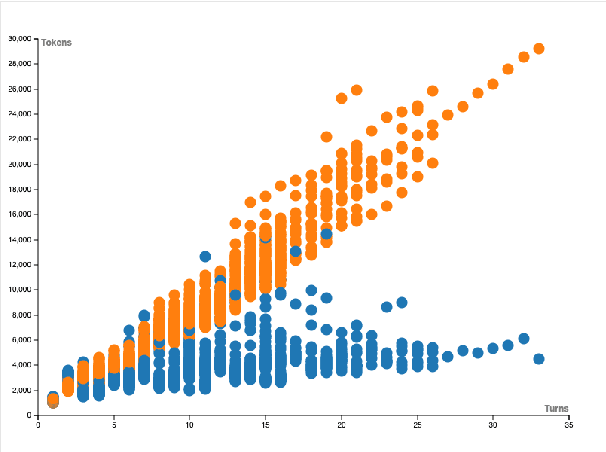
Large language models (LLMs) excel at single-turn reasoning but often lose accuracy and coherence over extended, multi-turn interactions. Recent evaluations such as TurnBench highlight recurring failure modes-reasoning bias, task drift, hallucination, overconfidence, and memory decay. Current approaches typically append full conversational histories, causing unbounded context growth, higher computational costs, and degraded reasoning efficiency. We introduce CogMem, a cognitively inspired, memory-augmented LLM architecture that supports sustained iterative reasoning through structured, persistent memory. CogMem incorporates three layers: a Long-Term Memory (LTM) that consolidates cross-session reasoning strategies; a Direct Access (DA) memory that maintains session-level notes and retrieves relevant long-term memories; and a Focus of Attention (FoA) mechanism that dynamically reconstructs concise, task-relevant context at each turn. Experiments on TurnBench show that this layered design mitigates reasoning failures, controls context growth, and improves consistency across extended reasoning chains, moving toward more reliable, human-like reasoning in LLMs.
Beyond the Black Box: Demystifying Multi-Turn LLM Reasoning with VISTA
Nov 13, 2025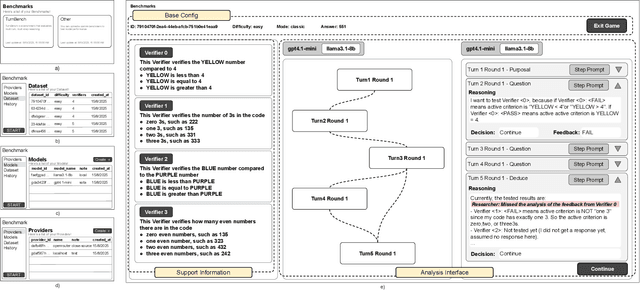
Recent research has increasingly focused on the reasoning capabilities of Large Language Models (LLMs) in multi-turn interactions, as these scenarios more closely mirror real-world problem-solving. However, analyzing the intricate reasoning processes within these interactions presents a significant challenge due to complex contextual dependencies and a lack of specialized visualization tools, leading to a high cognitive load for researchers. To address this gap, we present VISTA, an web-based Visual Interactive System for Textual Analytics in multi-turn reasoning tasks. VISTA allows users to visualize the influence of context on model decisions and interactively modify conversation histories to conduct "what-if" analyses across different models. Furthermore, the platform can automatically parse a session and generate a reasoning dependency tree, offering a transparent view of the model's step-by-step logical path. By providing a unified and interactive framework, VISTA significantly reduces the complexity of analyzing reasoning chains, thereby facilitating a deeper understanding of the capabilities and limitations of current LLMs. The platform is open-source and supports easy integration of custom benchmarks and local models.
We Think, Therefore We Align LLMs to Helpful, Harmless and Honest Before They Go Wrong
Sep 26, 2025



Alignment of Large Language Models (LLMs) along multiple objectives-helpfulness, harmlessness, and honesty (HHH)-is critical for safe and reliable deployment. Prior work has used steering vector-small control signals injected into hidden states-to guide LLM outputs, typically via one-to-one (1-to-1) Transformer decoders. In this setting, optimizing a single alignment objective can inadvertently overwrite representations learned for other objectives, leading to catastrophic forgetting. More recent approaches extend steering vectors via one-to-many (1-to-N) Transformer decoders. While this alleviates catastrophic forgetting, naive multi-branch designs optimize each objective independently, which can cause inference fragmentation-outputs across HHH objectives may become inconsistent. We propose Adaptive Multi-Branch Steering (AMBS), a two-stage 1-to-N framework for unified and efficient multi-objective alignment. In Stage I, post-attention hidden states of the Transformer layer are computed once to form a shared representation. In Stage II, this representation is cloned into parallel branches and steered via a policy-reference mechanism, enabling objective-specific control while maintaining cross-objective consistency. Empirical evaluations on Alpaca, BeaverTails, and TruthfulQA show that AMBS consistently improves HHH alignment across multiple 7B LLM backbones. For example, on DeepSeek-7B, AMBS improves average alignment scores by +32.4% and reduces unsafe outputs by 11.0% compared to a naive 1-to-N baseline, while remaining competitive with state-of-the-art methods.
Too Helpful, Too Harmless, Too Honest or Just Right?
Sep 10, 2025Large Language Models (LLMs) exhibit strong performance across a wide range of NLP tasks, yet aligning their outputs with the principles of Helpfulness, Harmlessness, and Honesty (HHH) remains a persistent challenge. Existing methods often optimize for individual alignment dimensions in isolation, leading to trade-offs and inconsistent behavior. While Mixture-of-Experts (MoE) architectures offer modularity, they suffer from poorly calibrated routing, limiting their effectiveness in alignment tasks. We propose TrinityX, a modular alignment framework that incorporates a Mixture of Calibrated Experts (MoCaE) within the Transformer architecture. TrinityX leverages separately trained experts for each HHH dimension, integrating their outputs through a calibrated, task-adaptive routing mechanism that combines expert signals into a unified, alignment-aware representation. Extensive experiments on three standard alignment benchmarks-Alpaca (Helpfulness), BeaverTails (Harmlessness), and TruthfulQA (Honesty)-demonstrate that TrinityX outperforms strong baselines, achieving relative improvements of 32.5% in win rate, 33.9% in safety score, and 28.4% in truthfulness. In addition, TrinityX reduces memory usage and inference latency by over 40% compared to prior MoE-based approaches. Ablation studies highlight the importance of calibrated routing, and cross-model evaluations confirm TrinityX's generalization across diverse LLM backbones.
Steering Towards Fairness: Mitigating Political Bias in LLMs
Aug 12, 2025Recent advancements in large language models (LLMs) have enabled their widespread use across diverse real-world applications. However, concerns remain about their tendency to encode and reproduce ideological biases, particularly along political and economic dimensions. In this paper, we propose a framework for probing and mitigating such biases in decoder-based LLMs through analysis of internal model representations. Grounded in the Political Compass Test (PCT), our method uses contrastive pairs to extract and compare hidden layer activations from models like Mistral and DeepSeek. We introduce a comprehensive activation extraction pipeline capable of layer-wise analysis across multiple ideological axes, revealing meaningful disparities linked to political framing. Our results show that decoder LLMs systematically encode representational bias across layers, which can be leveraged for effective steering vector-based mitigation. This work provides new insights into how political bias is encoded in LLMs and offers a principled approach to debiasing beyond surface-level output interventions.
Seeing the Threat: Vulnerabilities in Vision-Language Models to Adversarial Attack
May 28, 2025Large Vision-Language Models (LVLMs) have shown remarkable capabilities across a wide range of multimodal tasks. However, their integration of visual inputs introduces expanded attack surfaces, thereby exposing them to novel security vulnerabilities. In this work, we conduct a systematic representational analysis to uncover why conventional adversarial attacks can circumvent the safety mechanisms embedded in LVLMs. We further propose a novel two stage evaluation framework for adversarial attacks on LVLMs. The first stage differentiates among instruction non compliance, outright refusal, and successful adversarial exploitation. The second stage quantifies the degree to which the model's output fulfills the harmful intent of the adversarial prompt, while categorizing refusal behavior into direct refusals, soft refusals, and partial refusals that remain inadvertently helpful. Finally, we introduce a normative schema that defines idealized model behavior when confronted with harmful prompts, offering a principled target for safety alignment in multimodal systems.
A Survey on Progress in LLM Alignment from the Perspective of Reward Design
May 05, 2025The alignment of large language models (LLMs) with human values and intentions represents a core challenge in current AI research, where reward mechanism design has become a critical factor in shaping model behavior. This study conducts a comprehensive investigation of reward mechanisms in LLM alignment through a systematic theoretical framework, categorizing their development into three key phases: (1) feedback (diagnosis), (2) reward design (prescription), and (3) optimization (treatment). Through a four-dimensional analysis encompassing construction basis, format, expression, and granularity, this research establishes a systematic classification framework that reveals evolutionary trends in reward modeling. The field of LLM alignment faces several persistent challenges, while recent advances in reward design are driving significant paradigm shifts. Notable developments include the transition from reinforcement learning-based frameworks to novel optimization paradigms, as well as enhanced capabilities to address complex alignment scenarios involving multimodal integration and concurrent task coordination. Finally, this survey outlines promising future research directions for LLM alignment through innovative reward design strategies.
Bi-directional Model Cascading with Proxy Confidence
Apr 27, 2025Model Cascading, recently applied successfully to LLMs, is a simple but powerful technique that improves the efficiency of inference by selectively applying models of varying sizes. Models are used in sequence from smallest to largest, only deferring samples to large, costly models when smaller models are not sufficiently confident. Existing approaches to deferral use only limited small model confidence estimates because of the inaccessibility of the large model, although large model confidence is known to be important. We therefore propose a bi-directional approach to deferral that considers the confidence of small and large models in the cascade simultaneously through the use of a proxy for the large model. This requires a richer representation of model confidence to enable comparative calibration: we use an analysis of hidden states to improve post-invocation confidence of the small model, which in itself improves cascading results over prior approaches. We then combine this with a tiny proxy model to estimate pre-invocation confidence of the large model. We examine the proposed cascading system over challenging, multiple-choice datasets, finding improvements over standard cascading baselines reflected in reductions in deferrals to more costly models.
Myanmar XNLI: Building a Dataset and Exploring Low-resource Approaches to Natural Language Inference with Myanmar
Apr 13, 2025Despite dramatic recent progress in NLP, it is still a major challenge to apply Large Language Models (LLM) to low-resource languages. This is made visible in benchmarks such as Cross-Lingual Natural Language Inference (XNLI), a key task that demonstrates cross-lingual capabilities of NLP systems across a set of 15 languages. In this paper, we extend the XNLI task for one additional low-resource language, Myanmar, as a proxy challenge for broader low-resource languages, and make three core contributions. First, we build a dataset called Myanmar XNLI (myXNLI) using community crowd-sourced methods, as an extension to the existing XNLI corpus. This involves a two-stage process of community-based construction followed by expert verification; through an analysis, we demonstrate and quantify the value of the expert verification stage in the context of community-based construction for low-resource languages. We make the myXNLI dataset available to the community for future research. Second, we carry out evaluations of recent multilingual language models on the myXNLI benchmark, as well as explore data-augmentation methods to improve model performance. Our data-augmentation methods improve model accuracy by up to 2 percentage points for Myanmar, while uplifting other languages at the same time. Third, we investigate how well these data-augmentation methods generalise to other low-resource languages in the XNLI dataset.
Defending Deep Neural Networks against Backdoor Attacks via Module Switching
Apr 08, 2025The exponential increase in the parameters of Deep Neural Networks (DNNs) has significantly raised the cost of independent training, particularly for resource-constrained entities. As a result, there is a growing reliance on open-source models. However, the opacity of training processes exacerbates security risks, making these models more vulnerable to malicious threats, such as backdoor attacks, while simultaneously complicating defense mechanisms. Merging homogeneous models has gained attention as a cost-effective post-training defense. However, we notice that existing strategies, such as weight averaging, only partially mitigate the influence of poisoned parameters and remain ineffective in disrupting the pervasive spurious correlations embedded across model parameters. We propose a novel module-switching strategy to break such spurious correlations within the model's propagation path. By leveraging evolutionary algorithms to optimize fusion strategies, we validate our approach against backdoor attacks targeting text and vision domains. Our method achieves effective backdoor mitigation even when incorporating a couple of compromised models, e.g., reducing the average attack success rate (ASR) to 22% compared to 31.9% with the best-performing baseline on SST-2.