 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Calibration and Metric Differential Privacy in Language Models
Paper and Code
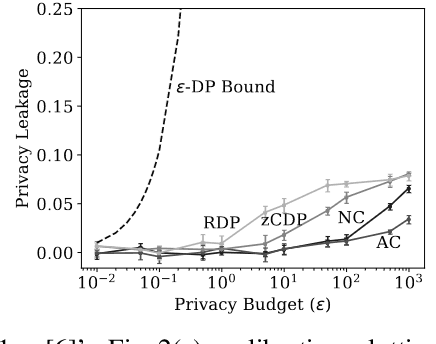
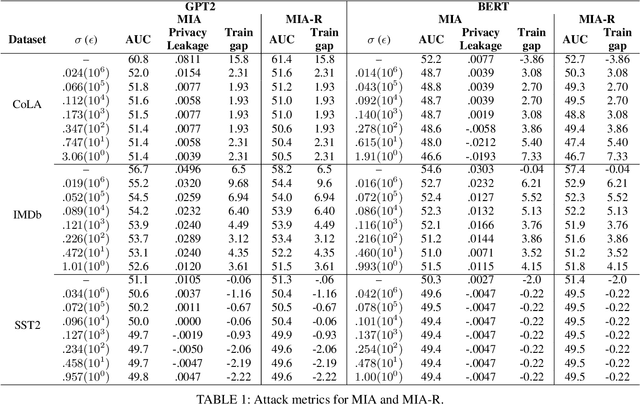
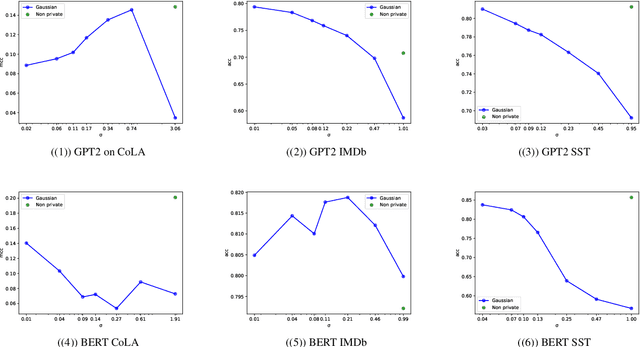

NLP models trained with differential privacy (DP) usually adopt the DP-SGD framework, and privacy guarantees are often reported in terms of the privacy budget $\epsilon$. However, $\epsilon$ does not have any intrinsic meaning, and it is generally not possible to compare across variants of the framework. Work in image processing has therefore explored how to empirically calibrate noise across frameworks using Membership Inference Attacks (MIAs). However, this kind of calibration has not been established for NLP. In this paper, we show that MIAs offer little help in calibrating privacy, whereas reconstruction attacks are more useful. As a use case, we define a novel kind of directional privacy based on the von Mises-Fisher (VMF) distribution, a metric DP mechanism that perturbs angular distance rather than adding (isotropic) Gaussian noise, and apply this to NLP architectures. We show that, even though formal guarantees are incomparable, empirical privacy calibration reveals that each mechanism has different areas of strength with respect to utility-privacy trade-offs.