 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuspiciousness of Adversarial Texts to Human
Oct 06, 2024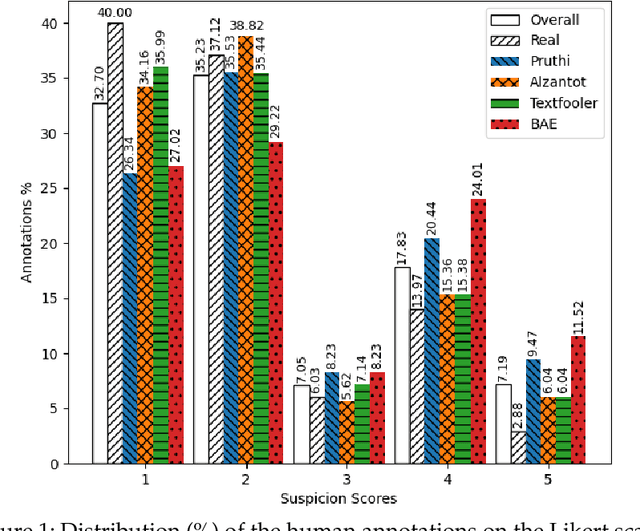
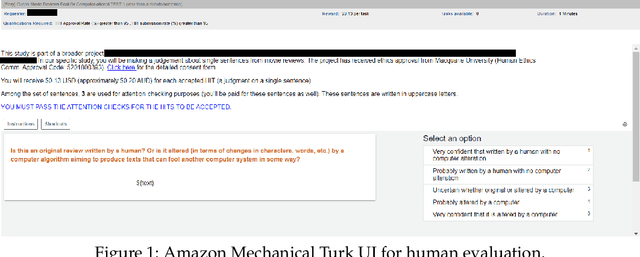


Adversarial examples pose a significant challenge to deep neural networks (DNNs) across both image and text domains, with the intent to degrade model performance through meticulously altered inputs. Adversarial texts, however, are distinct from adversarial images due to their requirement for semantic similarity and the discrete nature of the textual contents. This study delves into the concept of human suspiciousness, a quality distinct from the traditional focus on imperceptibility found in image-based adversarial examples. Unlike images, where adversarial changes are meant to be indistinguishable to the human eye, textual adversarial content must often remain undetected or non-suspicious to human readers, even when the text's purpose is to deceive NLP systems or bypass filters. In this research, we expand the study of human suspiciousness by analyzing how individuals perceive adversarial texts. We gather and publish a novel dataset of Likert-scale human evaluations on the suspiciousness of adversarial sentences, crafted by four widely used adversarial attack methods and assess their correlation with the human ability to detect machine-generated alterations. Additionally, we develop a regression-based model to quantify suspiciousness and establish a baseline for future research in reducing the suspiciousness in adversarial text generation. We also demonstrate how the regressor-generated suspicious scores can be incorporated into adversarial generation methods to produce texts that are less likely to be perceived as computer-generated. We make our human suspiciousness annotated data and our code available.
IDT: Dual-Task Adversarial Attacks for Privacy Protection
Jun 28, 2024



Natural language processing (NLP) models may leak private information in different ways, including membership inference, reconstruction or attribute inference attacks. Sensitive information may not be explicit in the text, but hidden in underlying writing characteristics. Methods to protect privacy can involve using representations inside models that are demonstrated not to detect sensitive attributes or -- for instance, in cases where users might not trust a model, the sort of scenario of interest here -- changing the raw text before models can have access to it. The goal is to rewrite text to prevent someone from inferring a sensitive attribute (e.g. the gender of the author, or their location by the writing style) whilst keeping the text useful for its original intention (e.g. the sentiment of a product review). The few works tackling this have focused on generative techniques. However, these often create extensively different texts from the original ones or face problems such as mode collapse. This paper explores a novel adaptation of adversarial attack techniques to manipulate a text to deceive a classifier w.r.t one task (privacy) whilst keeping the predictions of another classifier trained for another task (utility) unchanged. We propose IDT, a method that analyses predictions made by auxiliary and interpretable models to identify which tokens are important to change for the privacy task, and which ones should be kept for the utility task. We evaluate different datasets for NLP suitable for different tasks. Automatic and human evaluations show that IDT retains the utility of text, while also outperforming existing methods when deceiving a classifier w.r.t privacy task.
What Learned Representations and Influence Functions Can Tell Us About Adversarial Examples
Sep 21, 2023



Adversarial examples, deliberately crafted using small perturbations to fool deep neural networks, were first studied in image processing and more recently in NLP. While approaches to detecting adversarial examples in NLP have largely relied on search over input perturbations, image processing has seen a range of techniques that aim to characterise adversarial subspaces over the learned representations. In this paper, we adapt two such approaches to NLP, one based on nearest neighbors and influence functions and one on Mahalanobis distances. The former in particular produces a state-of-the-art detector when compared against several strong baselines; moreover, the novel use of influence functions provides insight into how the nature of adversarial example subspaces in NLP relate to those in image processing, and also how they differ depending on the kind of NLP task.
Data and Model Dependencies of Membership Inference Attack
Feb 17, 2020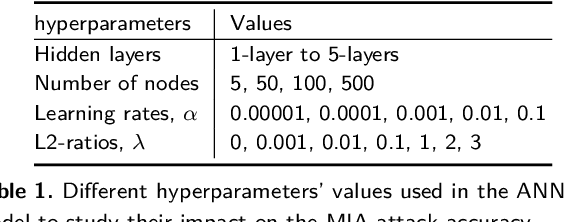
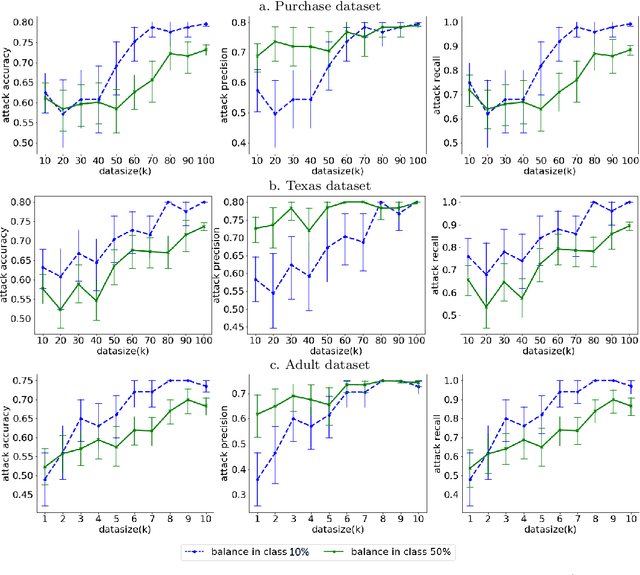
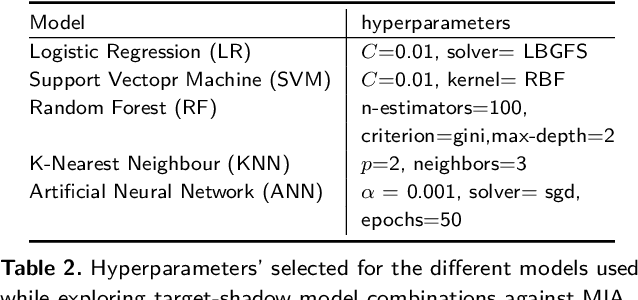
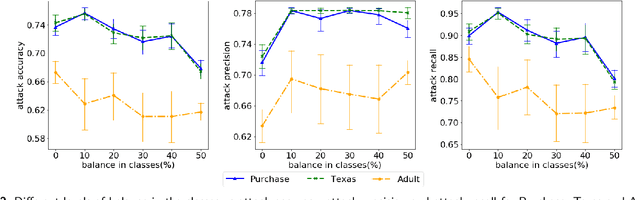
Machine Learning (ML) techniques are used by most data-driven organisations to extract insights. Machine-learning-as-a-service (MLaaS), where models are trained on potentially sensitive user data and then queried by external parties are becoming a reality. However, recently, these systems have been shown to be vulnerable to Membership Inference Attacks (MIA), where a target's data can be inferred to belong or not to the training data. While the key factors for the success of MIA have not been fully understood, existing defence mechanisms only consider the model-specific properties. We investigate the impact of both the data and ML model properties on the vulnerability of ML techniques to MIA. Our analysis indicates a strong relationship between the MIA success and the properties of the data in use, such as the data size and balance between the classes as well as the model properties including the fairness in prediction and the mutual information between the records and the model's parameters. We then propose new approaches to protect ML models from MIA by using several properties, e.g. the model's fairness and mutual information between the records and the model's parameters as regularizers, which reduces the attack accuracy by 25%, while yielding a fairer and a better performing ML model.