 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData and Model Dependencies of Membership Inference Attack
Paper and Code
Feb 17, 2020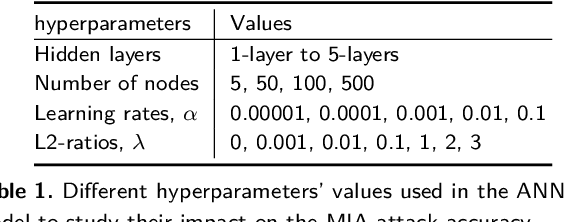
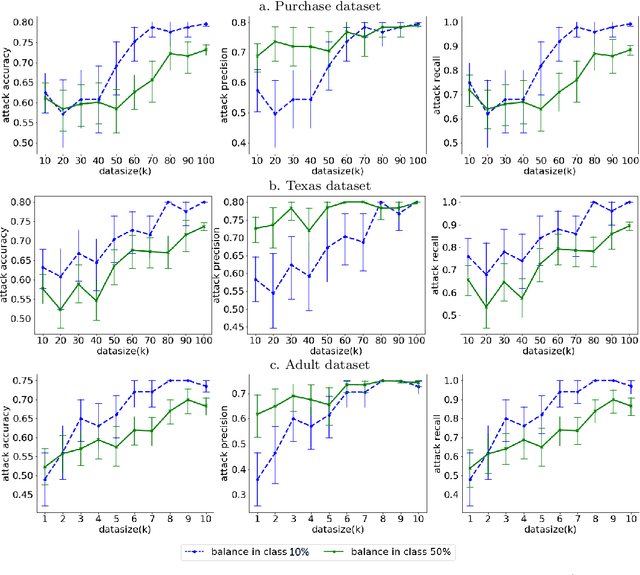
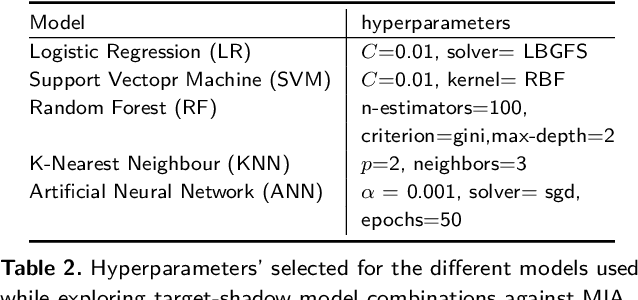
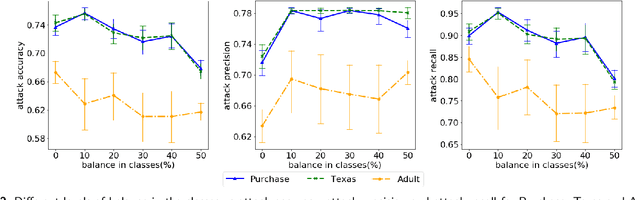
Machine Learning (ML) techniques are used by most data-driven organisations to extract insights. Machine-learning-as-a-service (MLaaS), where models are trained on potentially sensitive user data and then queried by external parties are becoming a reality. However, recently, these systems have been shown to be vulnerable to Membership Inference Attacks (MIA), where a target's data can be inferred to belong or not to the training data. While the key factors for the success of MIA have not been fully understood, existing defence mechanisms only consider the model-specific properties. We investigate the impact of both the data and ML model properties on the vulnerability of ML techniques to MIA. Our analysis indicates a strong relationship between the MIA success and the properties of the data in use, such as the data size and balance between the classes as well as the model properties including the fairness in prediction and the mutual information between the records and the model's parameters. We then propose new approaches to protect ML models from MIA by using several properties, e.g. the model's fairness and mutual information between the records and the model's parameters as regularizers, which reduces the attack accuracy by 25%, while yielding a fairer and a better performing ML model.