 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTIGuardian: A Few-Shot Framework for Mitigating Privacy Leakage in Fine-Tuned LLMs
Dec 15, 2025Large Language Models (LLMs) are often fine-tuned to adapt their general-purpose knowledge to specific tasks and domains such as cyber threat intelligence (CTI). Fine-tuning is mostly done through proprietary datasets that may contain sensitive information. Owners expect their fine-tuned model to not inadvertently leak this information to potentially adversarial end users. Using CTI as a use case, we demonstrate that data-extraction attacks can recover sensitive information from fine-tuned models on CTI reports, underscoring the need for mitigation. Retraining the full model to eliminate this leakage is computationally expensive and impractical. We propose an alternative approach, which we call privacy alignment, inspired by safety alignment in LLMs. Just like safety alignment teaches the model to abide by safety constraints through a few examples, we enforce privacy alignment through few-shot supervision, integrating a privacy classifier and a privacy redactor, both handled by the same underlying LLM. We evaluate our system, called CTIGuardian, using GPT-4o mini and Mistral-7B Instruct models, benchmarking against Presidio, a named entity recognition (NER) baseline. Results show that CTIGuardian provides a better privacy-utility trade-off than NER based models. While we demonstrate its effectiveness on a CTI use case, the framework is generic enough to be applicable to other sensitive domains.
Privacy-Preserving Record Linkage for Cardinality Counting
Jan 09, 2023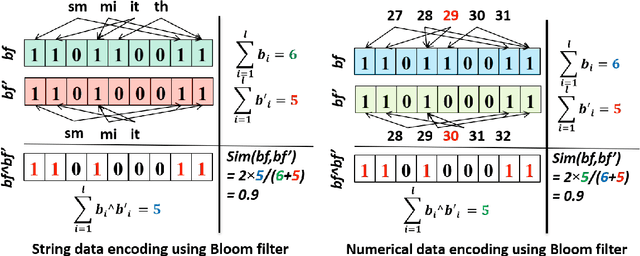
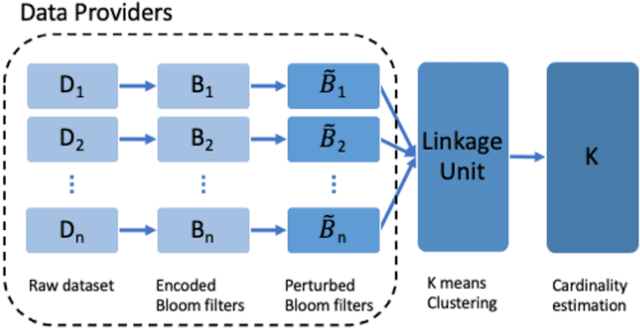
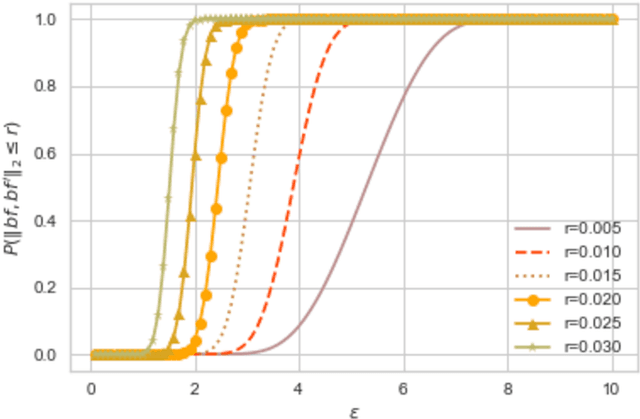
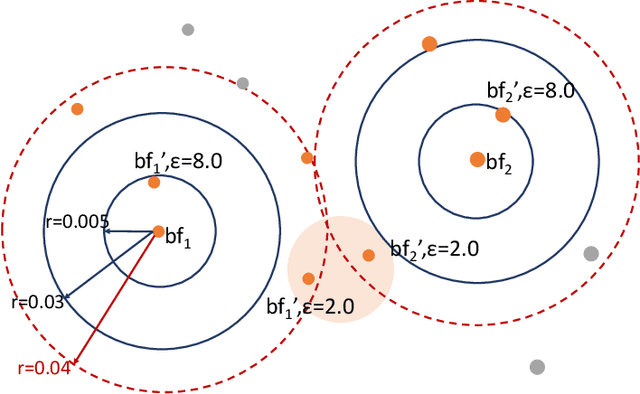
Several applications require counting the number of distinct items in the data, which is known as the cardinality counting problem. Example applications include health applications such as rare disease patients counting for adequate awareness and funding, and counting the number of cases of a new disease for outbreak detection, marketing applications such as counting the visibility reached for a new product, and cybersecurity applications such as tracking the number of unique views of social media posts. The data needed for the counting is however often personal and sensitive, and need to be processed using privacy-preserving techniques. The quality of data in different databases, for example typos, errors and variations, poses additional challenges for accurate cardinality estimation. While privacy-preserving cardinality counting has gained much attention in the recent times and a few privacy-preserving algorithms have been developed for cardinality estimation, no work has so far been done on privacy-preserving cardinality counting using record linkage techniques with fuzzy matching and provable privacy guarantees. We propose a novel privacy-preserving record linkage algorithm using unsupervised clustering techniques to link and count the cardinality of individuals in multiple datasets without compromising their privacy or identity. In addition, existing Elbow methods to find the optimal number of clusters as the cardinality are far from accurate as they do not take into account the purity and completeness of generated clusters. We propose a novel method to find the optimal number of clusters in unsupervised learning. Our experimental results on real and synthetic datasets are highly promising in terms of significantly smaller error rate of less than 0.1 with a privacy budget {\epsilon} = 1.0 compared to the state-of-the-art fuzzy matching and clustering method.
Privacy-preserving Deep Learning based Record Linkage
Nov 03, 2022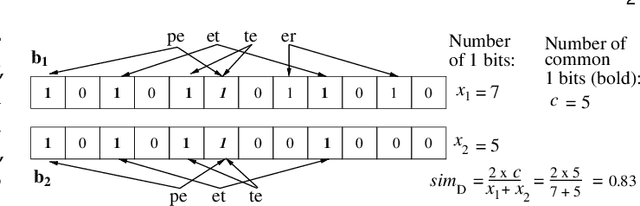



Deep learning-based linkage of records across different databases is becoming increasingly useful in data integration and mining applications to discover new insights from multiple sources of data. However, due to privacy and confidentiality concerns, organisations often are not willing or allowed to share their sensitive data with any external parties, thus making it challenging to build/train deep learning models for record linkage across different organizations' databases. To overcome this limitation, we propose the first deep learning-based multi-party privacy-preserving record linkage (PPRL) protocol that can be used to link sensitive databases held by multiple different organisations. In our approach, each database owner first trains a local deep learning model, which is then uploaded to a secure environment and securely aggregated to create a global model. The global model is then used by a linkage unit to distinguish unlabelled record pairs as matches and non-matches. We utilise differential privacy to achieve provable privacy protection against re-identification attacks. We evaluate the linkage quality and scalability of our approach using several large real-world databases, showing that it can achieve high linkage quality while providing sufficient privacy protection against existing attacks.
Data and Model Dependencies of Membership Inference Attack
Feb 17, 2020
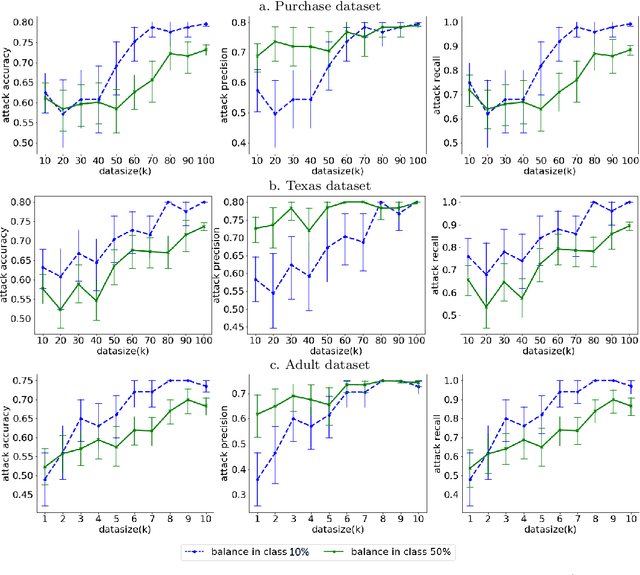
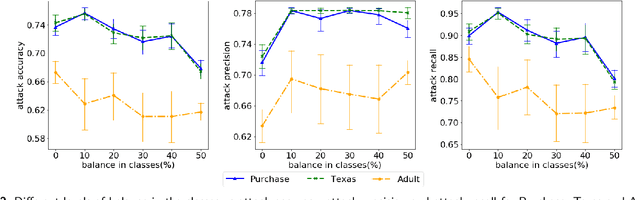
Machine Learning (ML) techniques are used by most data-driven organisations to extract insights. Machine-learning-as-a-service (MLaaS), where models are trained on potentially sensitive user data and then queried by external parties are becoming a reality. However, recently, these systems have been shown to be vulnerable to Membership Inference Attacks (MIA), where a target's data can be inferred to belong or not to the training data. While the key factors for the success of MIA have not been fully understood, existing defence mechanisms only consider the model-specific properties. We investigate the impact of both the data and ML model properties on the vulnerability of ML techniques to MIA. Our analysis indicates a strong relationship between the MIA success and the properties of the data in use, such as the data size and balance between the classes as well as the model properties including the fairness in prediction and the mutual information between the records and the model's parameters. We then propose new approaches to protect ML models from MIA by using several properties, e.g. the model's fairness and mutual information between the records and the model's parameters as regularizers, which reduces the attack accuracy by 25%, while yielding a fairer and a better performing ML model.