 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing DPSGD via Per-Sample Momentum and Low-Pass Filtering
Nov 11, 2025



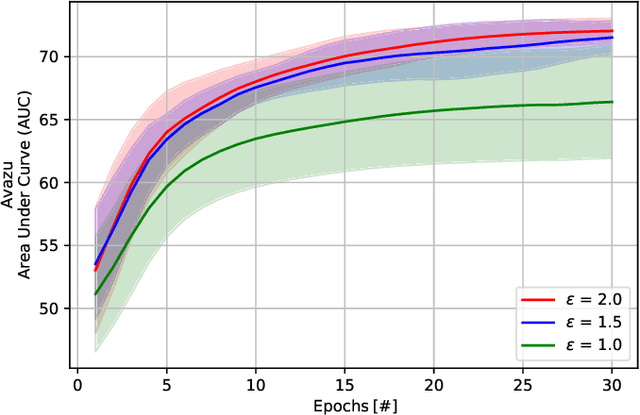
Differentially Private Stochastic Gradient Descent (DPSGD) is widely used to train deep neural networks with formal privacy guarantees. However, the addition of differential privacy (DP) often degrades model accuracy by introducing both noise and bias. Existing techniques typically address only one of these issues, as reducing DP noise can exacerbate clipping bias and vice-versa. In this paper, we propose a novel method, \emph{DP-PMLF}, which integrates per-sample momentum with a low-pass filtering strategy to simultaneously mitigate DP noise and clipping bias. Our approach uses per-sample momentum to smooth gradient estimates prior to clipping, thereby reducing sampling variance. It further employs a post-processing low-pass filter to attenuate high-frequency DP noise without consuming additional privacy budget. We provide a theoretical analysis demonstrating an improved convergence rate under rigorous DP guarantees, and our empirical evaluations reveal that DP-PMLF significantly enhances the privacy-utility trade-off compared to several state-of-the-art DPSGD variants.
From Detection to Correction: Backdoor-Resilient Face Recognition via Vision-Language Trigger Detection and Noise-Based Neutralization
Aug 07, 2025Biometric systems, such as face recognition systems powered by deep neural networks (DNNs), rely on large and highly sensitive datasets. Backdoor attacks can subvert these systems by manipulating the training process. By inserting a small trigger, such as a sticker, make-up, or patterned mask, into a few training images, an adversary can later present the same trigger during authentication to be falsely recognized as another individual, thereby gaining unauthorized access. Existing defense mechanisms against backdoor attacks still face challenges in precisely identifying and mitigating poisoned images without compromising data utility, which undermines the overall reliability of the system. We propose a novel and generalizable approach, TrueBiometric: Trustworthy Biometrics, which accurately detects poisoned images using a majority voting mechanism leveraging multiple state-of-the-art large vision language models. Once identified, poisoned samples are corrected using targeted and calibrated corrective noise. Our extensive empirical results demonstrate that TrueBiometric detects and corrects poisoned images with 100\% accuracy without compromising accuracy on clean images. Compared to existing state-of-the-art approaches, TrueBiometric offers a more practical, accurate, and effective solution for mitigating backdoor attacks in face recognition systems.
Private Knowledge Sharing in Distributed Learning: A Survey
Feb 08, 2024



The rise of Artificial Intelligence (AI) has revolutionized numerous industries and transformed the way society operates. Its widespread use has led to the distribution of AI and its underlying data across many intelligent systems. In this light, it is crucial to utilize information in learning processes that are either distributed or owned by different entities. As a result, modern data-driven services have been developed to integrate distributed knowledge entities into their outcomes. In line with this goal, the latest AI models are frequently trained in a decentralized manner. Distributed learning involves multiple entities working together to make collective predictions and decisions. However, this collaboration can also bring about security vulnerabilities and challenges. This paper provides an in-depth survey on private knowledge sharing in distributed learning, examining various knowledge components utilized in leading distributed learning architectures. Our analysis sheds light on the most critical vulnerabilities that may arise when using these components in a distributed setting. We further identify and examine defensive strategies for preserving the privacy of these knowledge components and preventing malicious parties from manipulating or accessing the knowledge information. Finally, we highlight several key limitations of knowledge sharing in distributed learning and explore potential avenues for future research.
Differentially Private Vertical Federated Learning
Nov 13, 2022
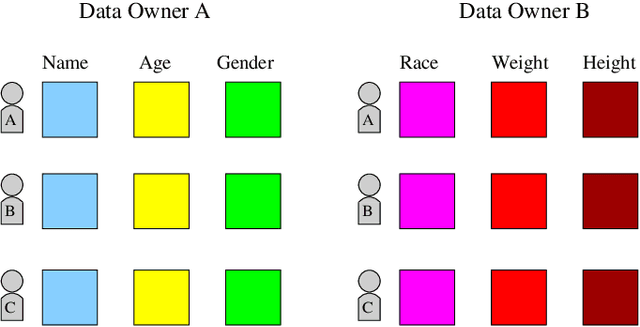


A successful machine learning (ML) algorithm often relies on a large amount of high-quality data to train well-performed models. Supervised learning approaches, such as deep learning techniques, generate high-quality ML functions for real-life applications, however with large costs and human efforts to label training data. Recent advancements in federated learning (FL) allow multiple data owners or organisations to collaboratively train a machine learning model without sharing raw data. In this light, vertical FL allows organisations to build a global model when the participating organisations have vertically partitioned data. Further, in the vertical FL setting the participating organisation generally requires fewer resources compared to sharing data directly, enabling lightweight and scalable distributed training solutions. However, privacy protection in vertical FL is challenging due to the communication of intermediate outputs and the gradients of model update. This invites adversary entities to infer other organisations underlying data. Thus, in this paper, we aim to explore how to protect the privacy of individual organisation data in a differential privacy (DP) setting. We run experiments with different real-world datasets and DP budgets. Our experimental results show that a trade-off point needs to be found to achieve a balance between the vertical FL performance and privacy protection in terms of the amount of perturbation noise.
Privacy-preserving Deep Learning based Record Linkage
Nov 03, 2022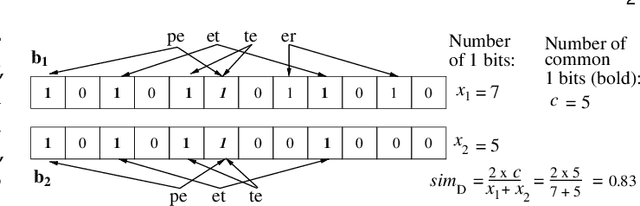



Deep learning-based linkage of records across different databases is becoming increasingly useful in data integration and mining applications to discover new insights from multiple sources of data. However, due to privacy and confidentiality concerns, organisations often are not willing or allowed to share their sensitive data with any external parties, thus making it challenging to build/train deep learning models for record linkage across different organizations' databases. To overcome this limitation, we propose the first deep learning-based multi-party privacy-preserving record linkage (PPRL) protocol that can be used to link sensitive databases held by multiple different organisations. In our approach, each database owner first trains a local deep learning model, which is then uploaded to a secure environment and securely aggregated to create a global model. The global model is then used by a linkage unit to distinguish unlabelled record pairs as matches and non-matches. We utilise differential privacy to achieve provable privacy protection against re-identification attacks. We evaluate the linkage quality and scalability of our approach using several large real-world databases, showing that it can achieve high linkage quality while providing sufficient privacy protection against existing attacks.
Vertical Federated Learning: Challenges, Methodologies and Experiments
Feb 09, 2022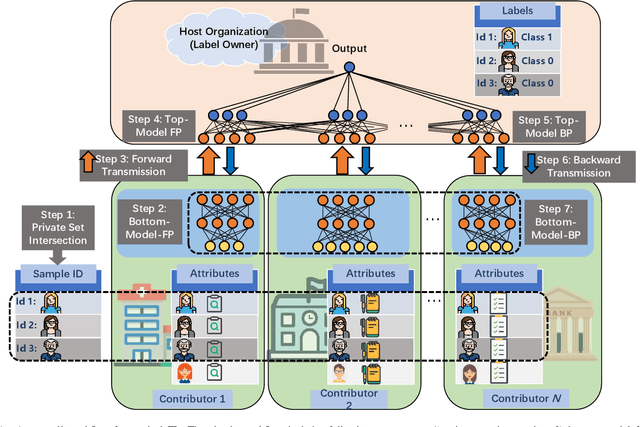
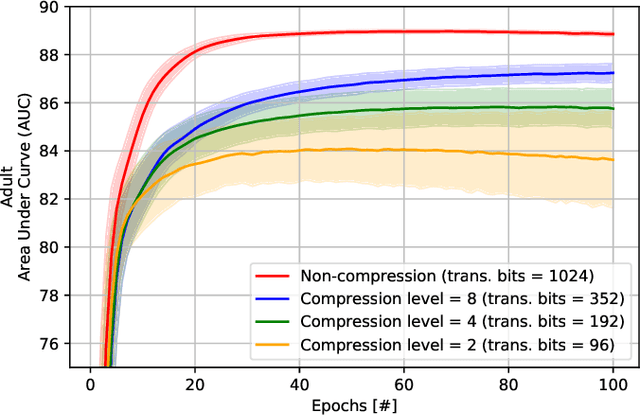
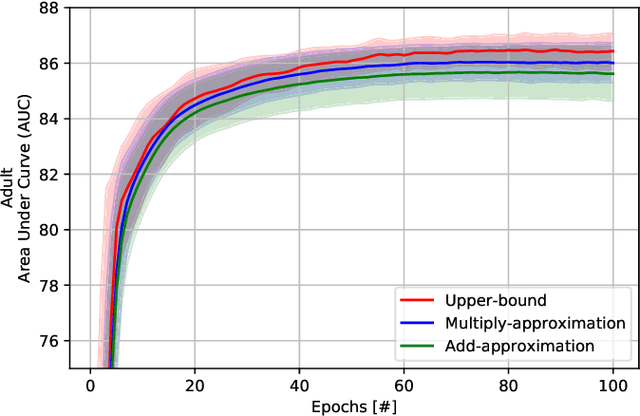
Recently, federated learning (FL) has emerged as a promising distributed machine learning (ML) technology, owing to the advancing computational and sensing capacities of end-user devices, however with the increasing concerns on users' privacy. As a special architecture in FL, vertical FL (VFL) is capable of constructing a hyper ML model by embracing sub-models from different clients. These sub-models are trained locally by vertically partitioned data with distinct attributes. Therefore, the design of VFL is fundamentally different from that of conventional FL, raising new and unique research issues. In this paper, we aim to discuss key challenges in VFL with effective solutions, and conduct experiments on real-life datasets to shed light on these issues. Specifically, we first propose a general framework on VFL, and highlight the key differences between VFL and conventional FL. Then, we discuss research challenges rooted in VFL systems under four aspects, i.e., security and privacy risks, expensive computation and communication costs, possible structural damage caused by model splitting, and system heterogeneity. Afterwards, we develop solutions to addressing the aforementioned challenges, and conduct extensive experiments to showcase the effectiveness of our proposed solutions.
Large Scale Record Linkage in the Presence of Missing Data
Apr 19, 2021
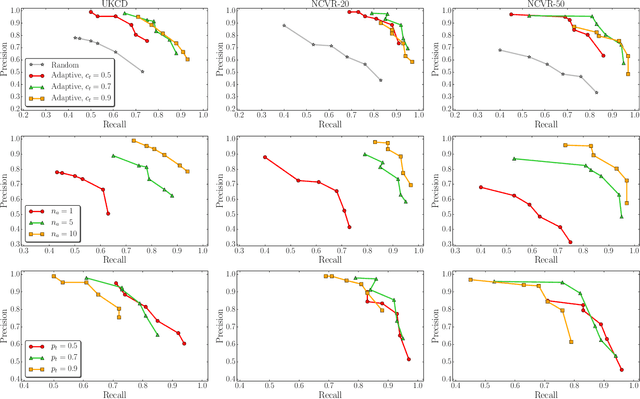


Record linkage is aimed at the accurate and efficient identification of records that represent the same entity within or across disparate databases. It is a fundamental task in data integration and increasingly required for accurate decision making in application domains ranging from health analytics to national security. Traditional record linkage techniques calculate string similarities between quasi-identifying (QID) values, such as the names and addresses of people. Errors, variations, and missing QID values can however lead to low linkage quality because the similarities between records cannot be calculated accurately. To overcome this challenge, we propose a novel technique that can accurately link records even when QID values contain errors or variations, or are missing. We first generate attribute signatures (concatenated QID values) using an Apriori based selection of suitable QID attributes, and then relational signatures that encapsulate relationship information between records. Combined, these signatures can uniquely identify individual records and facilitate fast and high quality linking of very large databases through accurate similarity calculations between records. We evaluate the linkage quality and scalability of our approach using large real-world databases, showing that it can achieve high linkage quality even when the databases being linked contain substantial amounts of missing values and errors.
Temporal graph-based clustering for historical record linkage
Jul 06, 2018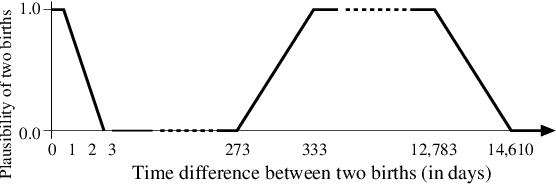

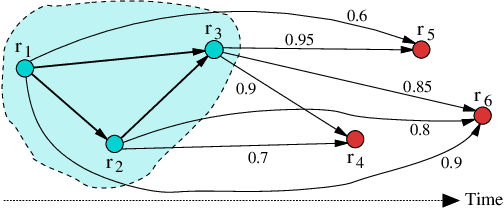

Research in the social sciences is increasingly based on large and complex data collections, where individual data sets from different domains are linked and integrated to allow advanced analytics. A popular type of data used in such a context are historical censuses, as well as birth, death, and marriage certificates. Individually, such data sets however limit the types of studies that can be conducted. Specifically, it is impossible to track individuals, families, or households over time. Once such data sets are linked and family trees spanning several decades are available it is possible to, for example, investigate how education, health, mobility, employment, and social status influence each other and the lives of people over two or even more generations. A major challenge is however the accurate linkage of historical data sets which is due to data quality and commonly also the lack of ground truth data being available. Unsupervised techniques need to be employed, which can be based on similarity graphs generated by comparing individual records. In this paper we present initial results from clustering birth records from Scotland where we aim to identify all births of the same mother and group siblings into clusters. We extend an existing clustering technique for record linkage by incorporating temporal constraints that must hold between births by the same mother, and propose a novel greedy temporal clustering technique. Experimental results show improvements over non-temporary approaches, however further work is needed to obtain links of high quality.