 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommon Misconceptions about Population Data
Jan 03, 2022

Databases covering all individuals of a population are increasingly used for research studies in domains ranging from public health to the social sciences. There is also growing interest by governments and businesses to use population data to support data-driven decision making. The massive size of such databases is often mistaken as a guarantee for valid inferences on the population of interest. However, population data have characteristics that make them challenging to use, including various assumptions being made how such data were collected and what types of processing have been applied to them. Furthermore, the full potential of population data can often only be unlocked when such data are linked to other databases, a process that adds fresh challenges. This article discusses a diverse range of misconceptions about population data that we believe anybody who works with such data needs to be aware of. Many of these misconceptions are not well documented in scientific publications but only discussed anecdotally among researchers and practitioners. We conclude with a set of recommendations for inference when using population data.
Large Scale Record Linkage in the Presence of Missing Data
Apr 19, 2021
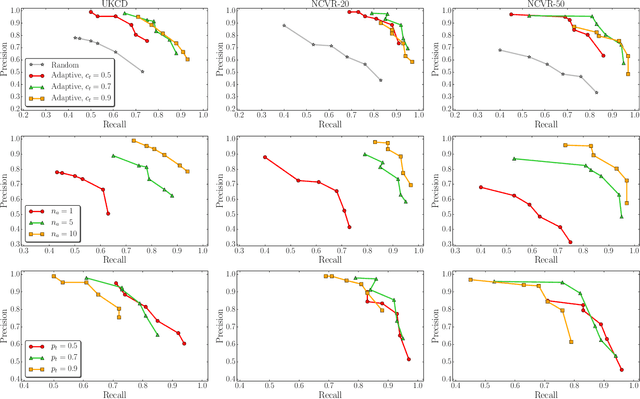


Record linkage is aimed at the accurate and efficient identification of records that represent the same entity within or across disparate databases. It is a fundamental task in data integration and increasingly required for accurate decision making in application domains ranging from health analytics to national security. Traditional record linkage techniques calculate string similarities between quasi-identifying (QID) values, such as the names and addresses of people. Errors, variations, and missing QID values can however lead to low linkage quality because the similarities between records cannot be calculated accurately. To overcome this challenge, we propose a novel technique that can accurately link records even when QID values contain errors or variations, or are missing. We first generate attribute signatures (concatenated QID values) using an Apriori based selection of suitable QID attributes, and then relational signatures that encapsulate relationship information between records. Combined, these signatures can uniquely identify individual records and facilitate fast and high quality linking of very large databases through accurate similarity calculations between records. We evaluate the linkage quality and scalability of our approach using large real-world databases, showing that it can achieve high linkage quality even when the databases being linked contain substantial amounts of missing values and errors.