 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Anonymized and Incomplete Tabular Data
Feb 01, 2026User-driven privacy allows individuals to control whether and at what granularity their data is shared, leading to datasets that mix original, generalized, and missing values within the same records and attributes. While such representations are intuitive for privacy, they pose challenges for machine learning, which typically treats non-original values as new categories or as missing, thereby discarding generalization semantics. For learning from such tabular data, we propose novel data transformation strategies that account for heterogeneous anonymization and evaluate them alongside standard imputation and LLM-based approaches. We employ multiple datasets, privacy configurations, and deployment scenarios, demonstrating that our method reliably regains utility. Our results show that generalized values are preferable to pure suppression, that the best data preparation strategy depends on the scenario, and that consistent data representations are crucial for maintaining downstream utility. Overall, our findings highlight that effective learning is tied to the appropriate handling of anonymized values.
Anomaly Detection and Classification in Knowledge Graphs
Dec 06, 2024Anomalies such as redundant, inconsistent, contradictory, and deficient values in a Knowledge Graph (KG) are unavoidable, as these graphs are often curated manually, or extracted using machine learning and natural language processing techniques. Therefore, anomaly detection is a task that can enhance the quality of KGs. In this paper, we propose SEKA (SEeking Knowledge graph Anomalies), an unsupervised approach for the detection of abnormal triples and entities in KGs. SEKA can help improve the correctness of a KG whilst retaining its coverage. We propose an adaption of the Path Rank Algorithm (PRA), named the Corroborative Path Rank Algorithm (CPRA), which is an efficient adaptation of PRA that is customized to detect anomalies in KGs. Furthermore, we also present TAXO (TAXOnomy of anomaly types in KGs), a taxonomy of possible anomaly types that can occur in a KG. This taxonomy provides a classification of the anomalies discovered by SEKA with an extensive discussion of possible data quality issues in a KG. We evaluate both approaches using the four real-world KGs YAGO-1, KBpedia, Wikidata, and DSKG to demonstrate the ability of SEKA and TAXO to outperform the baselines.
A Critical Re-evaluation of Benchmark Datasets for (Deep) Learning-Based Matching Algorithms
Jul 03, 2023Entity resolution (ER) is the process of identifying records that refer to the same entities within one or across multiple databases. Numerous techniques have been developed to tackle ER challenges over the years, with recent emphasis placed on machine and deep learning methods for the matching phase. However, the quality of the benchmark datasets typically used in the experimental evaluations of learning-based matching algorithms has not been examined in the literature. To cover this gap, we propose four different approaches to assessing the difficulty and appropriateness of 13 established datasets: two theoretical approaches, which involve new measures of linearity and existing measures of complexity, and two practical approaches: the difference between the best non-linear and linear matchers, as well as the difference between the best learning-based matcher and the perfect oracle. Our analysis demonstrates that most of the popular datasets pose rather easy classification tasks. As a result, they are not suitable for properly evaluating learning-based matching algorithms. To address this issue, we propose a new methodology for yielding benchmark datasets. We put it into practice by creating four new matching tasks, and we verify that these new benchmarks are more challenging and therefore more suitable for further advancements in the field.
Common Misconceptions about Population Data
Jan 03, 2022

Databases covering all individuals of a population are increasingly used for research studies in domains ranging from public health to the social sciences. There is also growing interest by governments and businesses to use population data to support data-driven decision making. The massive size of such databases is often mistaken as a guarantee for valid inferences on the population of interest. However, population data have characteristics that make them challenging to use, including various assumptions being made how such data were collected and what types of processing have been applied to them. Furthermore, the full potential of population data can often only be unlocked when such data are linked to other databases, a process that adds fresh challenges. This article discusses a diverse range of misconceptions about population data that we believe anybody who works with such data needs to be aware of. Many of these misconceptions are not well documented in scientific publications but only discussed anecdotally among researchers and practitioners. We conclude with a set of recommendations for inference when using population data.
Large Scale Record Linkage in the Presence of Missing Data
Apr 19, 2021


Record linkage is aimed at the accurate and efficient identification of records that represent the same entity within or across disparate databases. It is a fundamental task in data integration and increasingly required for accurate decision making in application domains ranging from health analytics to national security. Traditional record linkage techniques calculate string similarities between quasi-identifying (QID) values, such as the names and addresses of people. Errors, variations, and missing QID values can however lead to low linkage quality because the similarities between records cannot be calculated accurately. To overcome this challenge, we propose a novel technique that can accurately link records even when QID values contain errors or variations, or are missing. We first generate attribute signatures (concatenated QID values) using an Apriori based selection of suitable QID attributes, and then relational signatures that encapsulate relationship information between records. Combined, these signatures can uniquely identify individual records and facilitate fast and high quality linking of very large databases through accurate similarity calculations between records. We evaluate the linkage quality and scalability of our approach using large real-world databases, showing that it can achieve high linkage quality even when the databases being linked contain substantial amounts of missing values and errors.
F*: An Interpretable Transformation of the F-measure
Jul 31, 2020
The F-measure is widely used to assess the performance of classification algorithms. However, some researchers find it lacking in intuitive interpretation, questioning the appropriateness of combining two aspects of performance as conceptually distinct as precision and recall, and also questioning whether the harmonic mean is the best way to combine them. To ease this concern, we describe a simple transformation of the F-measure, which we call F* (F-star), which has an immediate practical interpretation.
Temporal graph-based clustering for historical record linkage
Jul 06, 2018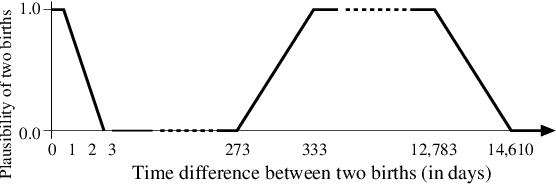


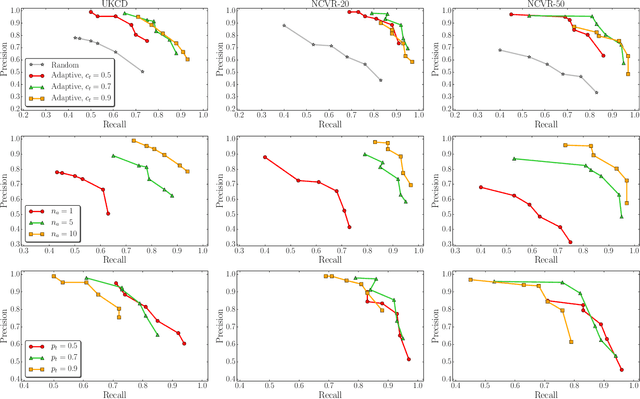
Research in the social sciences is increasingly based on large and complex data collections, where individual data sets from different domains are linked and integrated to allow advanced analytics. A popular type of data used in such a context are historical censuses, as well as birth, death, and marriage certificates. Individually, such data sets however limit the types of studies that can be conducted. Specifically, it is impossible to track individuals, families, or households over time. Once such data sets are linked and family trees spanning several decades are available it is possible to, for example, investigate how education, health, mobility, employment, and social status influence each other and the lives of people over two or even more generations. A major challenge is however the accurate linkage of historical data sets which is due to data quality and commonly also the lack of ground truth data being available. Unsupervised techniques need to be employed, which can be based on similarity graphs generated by comparing individual records. In this paper we present initial results from clustering birth records from Scotland where we aim to identify all births of the same mother and group siblings into clusters. We extend an existing clustering technique for record linkage by incorporating temporal constraints that must hold between births by the same mother, and propose a novel greedy temporal clustering technique. Experimental results show improvements over non-temporary approaches, however further work is needed to obtain links of high quality.
A Decision Tree Approach to Predicting Recidivism in Domestic Violence
Mar 27, 2018
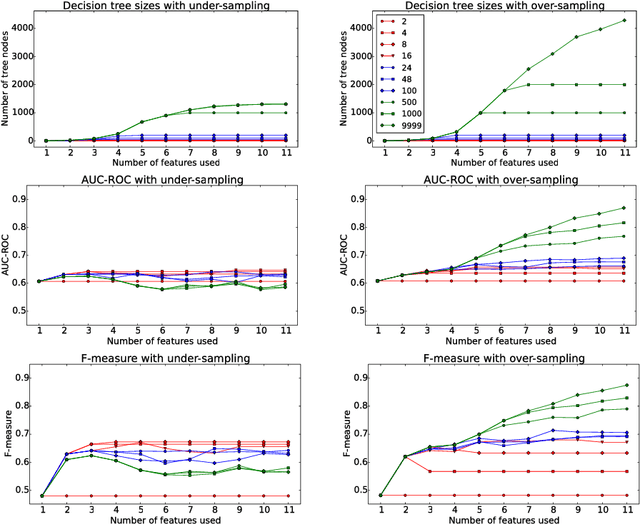


Domestic violence (DV) is a global social and public health issue that is highly gendered. Being able to accurately predict DV recidivism, i.e., re-offending of a previously convicted offender, can speed up and improve risk assessment procedures for police and front-line agencies, better protect victims of DV, and potentially prevent future re-occurrences of DV. Previous work in DV recidivism has employed different classification techniques, including decision tree (DT) induction and logistic regression, where the main focus was on achieving high prediction accuracy. As a result, even the diagrams of trained DTs were often too difficult to interpret due to their size and complexity, making decision-making challenging. Given there is often a trade-off between model accuracy and interpretability, in this work our aim is to employ DT induction to obtain both interpretable trees as well as high prediction accuracy. Specifically, we implement and evaluate different approaches to deal with class imbalance as well as feature selection. Compared to previous work in DV recidivism prediction that employed logistic regression, our approach can achieve comparable area under the ROC curve results by using only 3 of 11 available features and generating understandable decision trees that contain only 4 leaf nodes.
Application of Advanced Record Linkage Techniques for Complex Population Reconstruction
Dec 13, 2016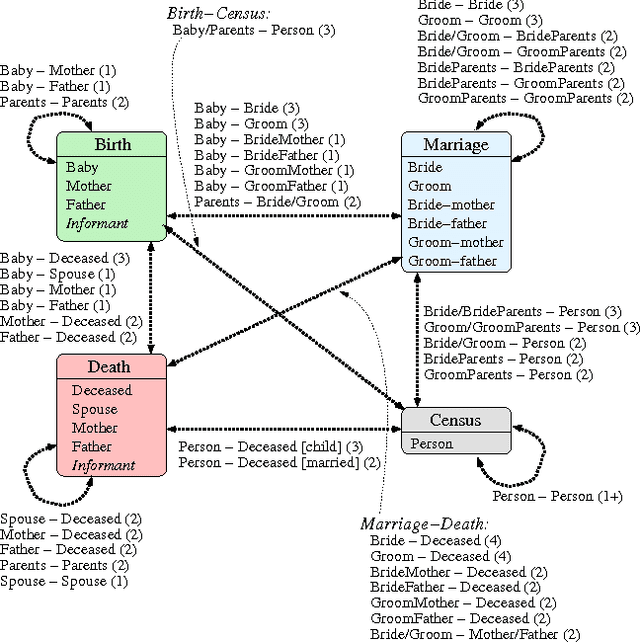
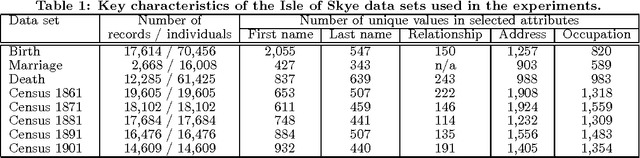

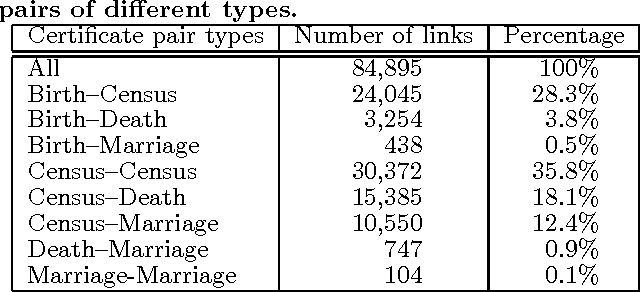
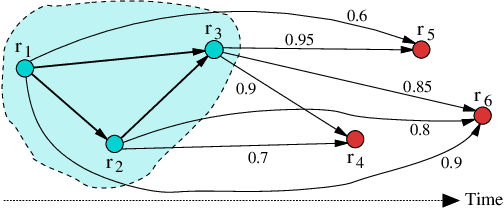
Record linkage is the process of identifying records that refer to the same entities from several databases. This process is challenging because commonly no unique entity identifiers are available. Linkage therefore has to rely on partially identifying attributes, such as names and addresses of people. Recent years have seen the development of novel techniques for linking data from diverse application areas, where a major focus has been on linking complex data that contain records about different types of entities. Advanced approaches that exploit both the similarities between record attributes as well as the relationships between entities to identify clusters of matching records have been developed. In this application paper we study the novel problem where rather than different types of entities we have databases where the same entity can have different roles, and where these roles change over time. We specifically develop novel techniques for linking historical birth, death, marriage and census records with the aim to reconstruct the population covered by these records over a period of several decades. Our experimental evaluation on real Scottish data shows that even with advanced linkage techniques that consider group, relationship, and temporal aspects it is challenging to achieve high quality linkage from such complex data.