 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Meta-Learning for Few-Shot Fault Diagnosis with Representation Encoding
Oct 13, 2023



Deep learning-based fault diagnosis (FD) approaches require a large amount of training data, which are difficult to obtain since they are located across different entities. Federated learning (FL) enables multiple clients to collaboratively train a shared model with data privacy guaranteed. However, the domain discrepancy and data scarcity problems among clients deteriorate the performance of the global FL model. To tackle these issues, we propose a novel framework called representation encoding-based federated meta-learning (REFML) for few-shot FD. First, a novel training strategy based on representation encoding and meta-learning is developed. It harnesses the inherent heterogeneity among training clients, effectively transforming it into an advantage for out-of-distribution generalization on unseen working conditions or equipment types. Additionally, an adaptive interpolation method that calculates the optimal combination of local and global models as the initialization of local training is proposed. This helps to further utilize local information to mitigate the negative effects of domain discrepancy. As a result, high diagnostic accuracy can be achieved on unseen working conditions or equipment types with limited training data. Compared with the state-of-the-art methods, such as FedProx, the proposed REFML framework achieves an increase in accuracy by 2.17%-6.50% when tested on unseen working conditions of the same equipment type and 13.44%-18.33% when tested on totally unseen equipment types, respectively.
Vertical Federated Learning: Challenges, Methodologies and Experiments
Feb 09, 2022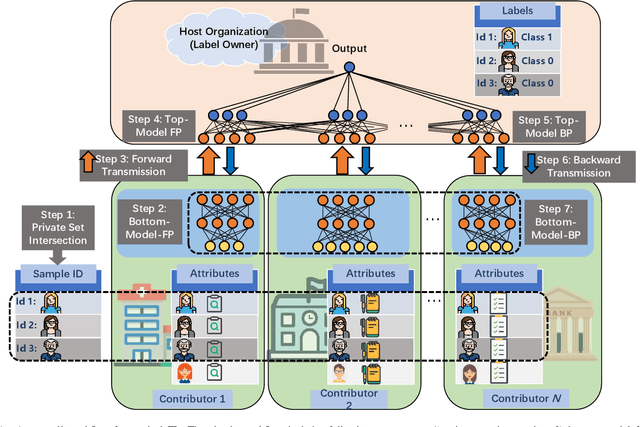
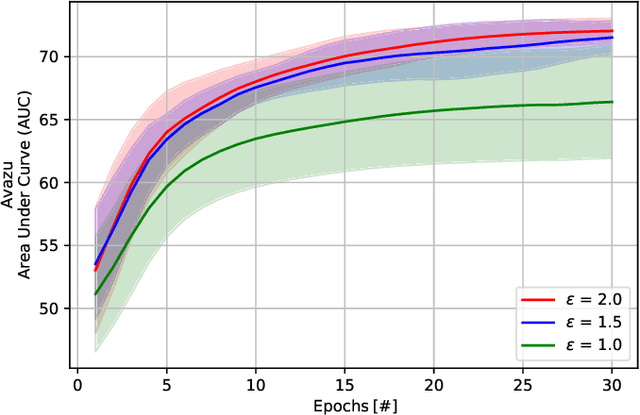
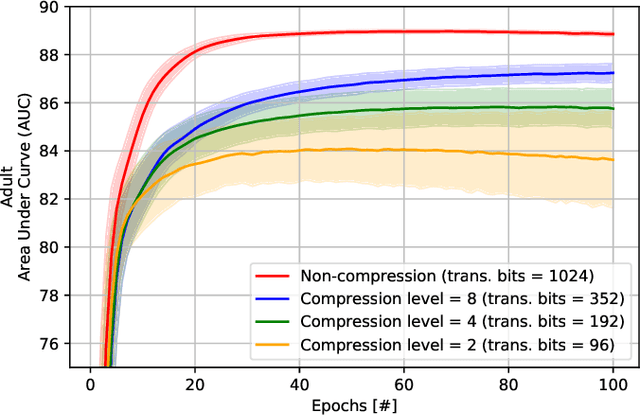
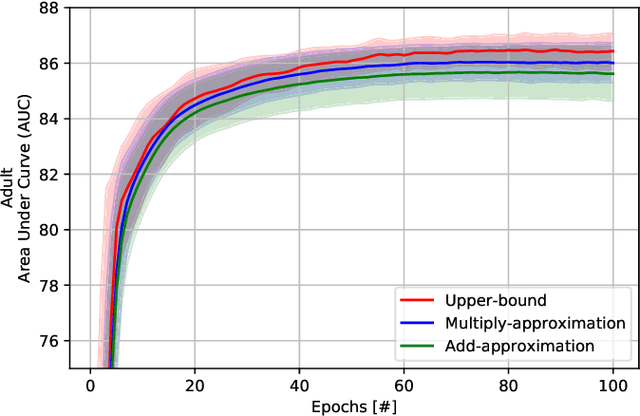
Recently, federated learning (FL) has emerged as a promising distributed machine learning (ML) technology, owing to the advancing computational and sensing capacities of end-user devices, however with the increasing concerns on users' privacy. As a special architecture in FL, vertical FL (VFL) is capable of constructing a hyper ML model by embracing sub-models from different clients. These sub-models are trained locally by vertically partitioned data with distinct attributes. Therefore, the design of VFL is fundamentally different from that of conventional FL, raising new and unique research issues. In this paper, we aim to discuss key challenges in VFL with effective solutions, and conduct experiments on real-life datasets to shed light on these issues. Specifically, we first propose a general framework on VFL, and highlight the key differences between VFL and conventional FL. Then, we discuss research challenges rooted in VFL systems under four aspects, i.e., security and privacy risks, expensive computation and communication costs, possible structural damage caused by model splitting, and system heterogeneity. Afterwards, we develop solutions to addressing the aforementioned challenges, and conduct extensive experiments to showcase the effectiveness of our proposed solutions.