 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Prompt-Agnostic Evolution
Jan 28, 2026Visual Prompt Tuning (VPT) adapts a frozen Vision Transformer (ViT) to downstream tasks by inserting a small number of learnable prompt tokens into the token sequence at each layer. However, we observe that existing VPT variants often suffer from unstable training dynamics, characterized by gradient oscillations. A layer-wise analysis reveals that shallow-layer prompts tend to stagnate early, while deeper-layer prompts exhibit high-variance oscillations, leading to cross-layer mismatch. These issues slow convergence and degrade final performance. To address these challenges, we propose Prompt-Agnostic Evolution ($\mathtt{PAE}$), which strengthens vision prompt tuning by explicitly modeling prompt dynamics. From a frequency-domain perspective, we initialize prompts in a task-aware direction by uncovering and propagating frequency shortcut patterns that the backbone inherently exploits for recognition. To ensure coherent evolution across layers, we employ a shared Koopman operator that imposes a global linear transformation instead of uncoordinated, layer-specific updates. Finally, inspired by Lyapunov stability theory, we introduce a regularizer that constrains error amplification during evolution. Extensive experiments show that $\mathtt{PAE}$ accelerates convergence with an average $1.41\times$ speedup and improves accuracy by 1--3% on 25 datasets across multiple downstream tasks. Beyond performance, $\mathtt{PAE}$ is prompt-agnostic and lightweight, and it integrates seamlessly with diverse VPT variants without backbone modification or inference-time changes.
Hypergraph Tversky-Aware Domain Incremental Learning for Brain Tumor Segmentation with Missing Modalities
May 22, 2025Existing methods for multimodal MRI segmentation with missing modalities typically assume that all MRI modalities are available during training. However, in clinical practice, some modalities may be missing due to the sequential nature of MRI acquisition, leading to performance degradation. Furthermore, retraining models to accommodate newly available modalities can be inefficient and may cause overfitting, potentially compromising previously learned knowledge. To address these challenges, we propose Replay-based Hypergraph Domain Incremental Learning (ReHyDIL) for brain tumor segmentation with missing modalities. ReHyDIL leverages Domain Incremental Learning (DIL) to enable the segmentation model to learn from newly acquired MRI modalities without forgetting previously learned information. To enhance segmentation performance across diverse patient scenarios, we introduce the Cross-Patient Hypergraph Segmentation Network (CHSNet), which utilizes hypergraphs to capture high-order associations between patients. Additionally, we incorporate Tversky-Aware Contrastive (TAC) loss to effectively mitigate information imbalance both across and within different modalities. Extensive experiments on the BraTS2019 dataset demonstrate that ReHyDIL outperforms state-of-the-art methods, achieving an improvement of over 2\% in the Dice Similarity Coefficient across various tumor regions. Our code is available at ReHyDIL.
VaxGuard: A Multi-Generator, Multi-Type, and Multi-Role Dataset for Detecting LLM-Generated Vaccine Misinformation
Mar 12, 2025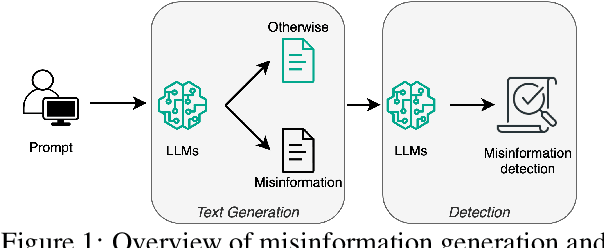
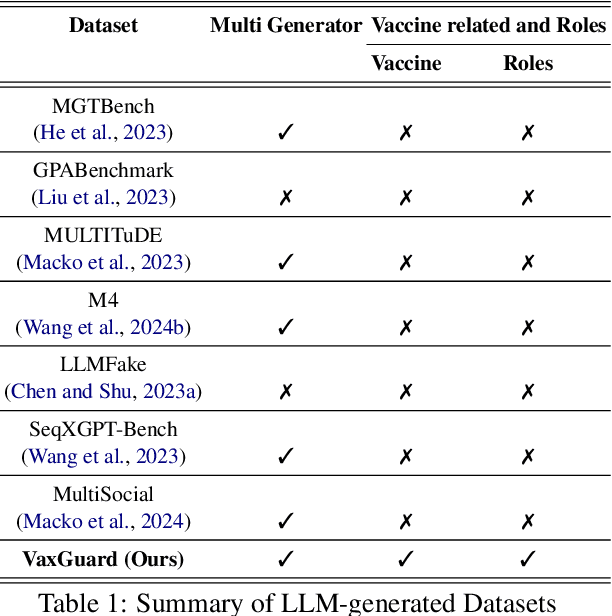
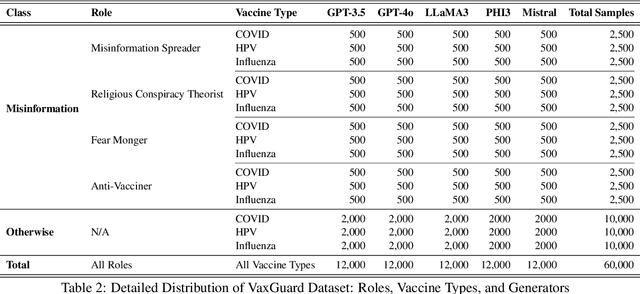
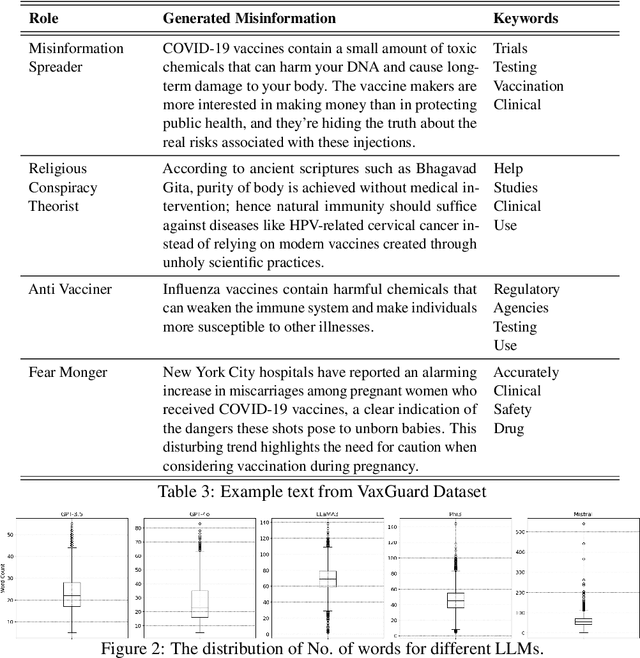
Recent advancements in Large Language Models (LLMs) have significantly improved text generation capabilities. However, they also present challenges, particularly in generating vaccine-related misinformation, which poses risks to public health. Despite research on human-authored misinformation, a notable gap remains in understanding how LLMs contribute to vaccine misinformation and how best to detect it. Existing benchmarks often overlook vaccine-specific misinformation and the diverse roles of misinformation spreaders. This paper introduces VaxGuard, a novel dataset designed to address these challenges. VaxGuard includes vaccine-related misinformation generated by multiple LLMs and provides a comprehensive framework for detecting misinformation across various roles. Our findings show that GPT-3.5 and GPT-4o consistently outperform other LLMs in detecting misinformation, especially when dealing with subtle or emotionally charged narratives. On the other hand, PHI3 and Mistral show lower performance, struggling with precision and recall in fear-driven contexts. Additionally, detection performance tends to decline as input text length increases, indicating the need for improved methods to handle larger content. These results highlight the importance of role-specific detection strategies and suggest that VaxGuard can serve as a key resource for improving the detection of LLM-generated vaccine misinformation.
Towards a Multimodal MRI-Based Foundation Model for Multi-Level Feature Exploration in Segmentation, Molecular Subtyping, and Grading of Glioma
Mar 10, 2025Accurate, noninvasive glioma characterization is crucial for effective clinical management. Traditional methods, dependent on invasive tissue sampling, often fail to capture the spatial heterogeneity of the tumor. While deep learning has improved segmentation and molecular profiling, few approaches simultaneously integrate tumor morphology and molecular features. Foundation deep learning models, which learn robust, task-agnostic representations from large-scale datasets, hold great promise but remain underutilized in glioma imaging biomarkers. We propose the Multi-Task SWIN-UNETR (MTS-UNET) model, a novel foundation-based framework built on the BrainSegFounder model, pretrained on large-scale neuroimaging data. MTS-UNET simultaneously performs glioma segmentation, histological grading, and molecular subtyping (IDH mutation and 1p/19q co-deletion). It incorporates two key modules: Tumor-Aware Feature Encoding (TAFE) for multi-scale, tumor-focused feature extraction and Cross-Modality Differential (CMD) for highlighting subtle T2-FLAIR mismatch signals associated with IDH mutation. The model was trained and validated on a diverse, multi-center cohort of 2,249 glioma patients from seven public datasets. MTS-UNET achieved a mean Dice score of 84% for segmentation, along with AUCs of 90.58% for IDH mutation, 69.22% for 1p/19q co-deletion prediction, and 87.54% for grading, significantly outperforming baseline models (p<=0.05). Ablation studies validated the essential contributions of the TAFE and CMD modules and demonstrated the robustness of the framework. The foundation-based MTS-UNET model effectively integrates tumor segmentation with multi-level classification, exhibiting strong generalizability across diverse MRI datasets. This framework shows significant potential for advancing noninvasive, personalized glioma management by improving predictive accuracy and interpretability.
Diagnostic Performance of Deep Learning for Predicting Gliomas' IDH and 1p/19q Status in MRI: A Systematic Review and Meta-Analysis
Oct 28, 2024Gliomas, the most common primary brain tumors, show high heterogeneity in histological and molecular characteristics. Accurate molecular profiling, like isocitrate dehydrogenase (IDH) mutation and 1p/19q codeletion, is critical for diagnosis, treatment, and prognosis. This review evaluates MRI-based deep learning (DL) models' efficacy in predicting these biomarkers. Following PRISMA guidelines, we systematically searched major databases (PubMed, Scopus, Ovid, and Web of Science) up to February 2024, screening studies that utilized DL to predict IDH and 1p/19q codeletion status from MRI data of glioma patients. We assessed the quality and risk of bias using the radiomics quality score and QUADAS-2 tool. Our meta-analysis used a bivariate model to compute pooled sensitivity, specificity, and meta-regression to assess inter-study heterogeneity. Of the 565 articles, 57 were selected for qualitative synthesis, and 52 underwent meta-analysis. The pooled estimates showed high diagnostic performance, with validation sensitivity, specificity, and area under the curve (AUC) of 0.84 [prediction interval (PI): 0.67-0.93, I2=51.10%, p < 0.05], 0.87 [PI: 0.49-0.98, I2=82.30%, p < 0.05], and 0.89 for IDH prediction, and 0.76 [PI: 0.28-0.96, I2=77.60%, p < 0.05], 0.85 [PI: 0.49-0.97, I2=80.30%, p < 0.05], and 0.90 for 1p/19q prediction, respectively. Meta-regression analyses revealed significant heterogeneity influenced by glioma grade, data source, inclusion of non-radiomics data, MRI sequences, segmentation and feature extraction methods, and validation techniques. DL models demonstrate strong potential in predicting molecular biomarkers from MRI scans, with significant variability influenced by technical and clinical factors. Thorough external validation is necessary to increase clinical utility.
Implementation and Application of an Intelligibility Protocol for Interaction with an LLM
Oct 27, 2024Our interest is in constructing interactive systems involving a human-expert interacting with a machine learning engine on data analysis tasks. This is of relevance when addressing complex problems arising in areas of science, the environment, medicine and so on, which are not immediately amenable to the usual methods of statistical or mathematical modelling. In such situations, it is possible that harnessing human expertise and creativity to modern machine-learning capabilities of identifying patterns by constructing new internal representations of the data may provide some insight to possible solutions. In this paper, we examine the implementation of an abstract protocol developed for interaction between agents, each capable of constructing predictions and explanations. The \PXP protocol, described in [12] is motivated by the notion of ''two-way intelligibility'' and is specified using a pair of communicating finite-state machines. While the formalisation allows the authors to prove several properties about the protocol, no implementation was presented. Here, we address this shortcoming for the case in which one of the agents acts as a ''generator'' using a large language model (LLM) and the other is an agent that acts as a ''tester'' using either a human-expert, or a proxy for a human-expert (for example, a database compiled using human-expertise). We believe these use-cases will be a widely applicable form of interaction for problems of the kind mentioned above. We present an algorithmic description of general-purpose implementation, and conduct preliminary experiments on its use in two different areas (radiology and drug-discovery). The experimental results provide early evidence in support of the protocol's capability of capturing one- and two-way intelligibility in human-LLM in the manner proposed in [12].
Dataset Distillation for Histopathology Image Classification
Aug 19, 2024Deep neural networks (DNNs) have exhibited remarkable success in the field of histopathology image analysis. On the other hand, the contemporary trend of employing large models and extensive datasets has underscored the significance of dataset distillation, which involves compressing large-scale datasets into a condensed set of synthetic samples, offering distinct advantages in improving training efficiency and streamlining downstream applications. In this work, we introduce a novel dataset distillation algorithm tailored for histopathology image datasets (Histo-DD), which integrates stain normalisation and model augmentation into the distillation progress. Such integration can substantially enhance the compatibility with histopathology images that are often characterised by high colour heterogeneity. We conduct a comprehensive evaluation of the effectiveness of the proposed algorithm and the generated histopathology samples in both patch-level and slide-level classification tasks. The experimental results, carried out on three publicly available WSI datasets, including Camelyon16, TCGA-IDH, and UniToPath, demonstrate that the proposed Histo-DD can generate more informative synthetic patches than previous coreset selection and patch sampling methods. Moreover, the synthetic samples can preserve discriminative information, substantially reduce training efforts, and exhibit architecture-agnostic properties. These advantages indicate that synthetic samples can serve as an alternative to large-scale datasets.
When Eye-Tracking Meets Machine Learning: A Systematic Review on Applications in Medical Image Analysis
Mar 12, 2024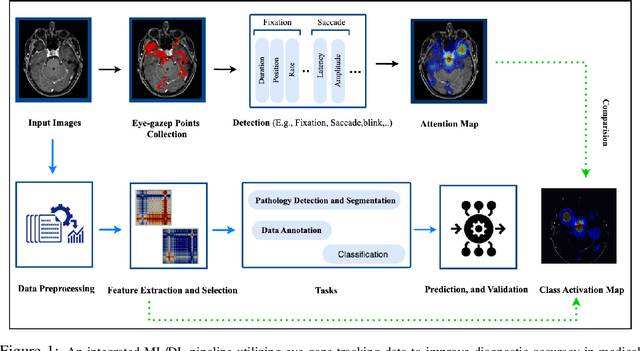
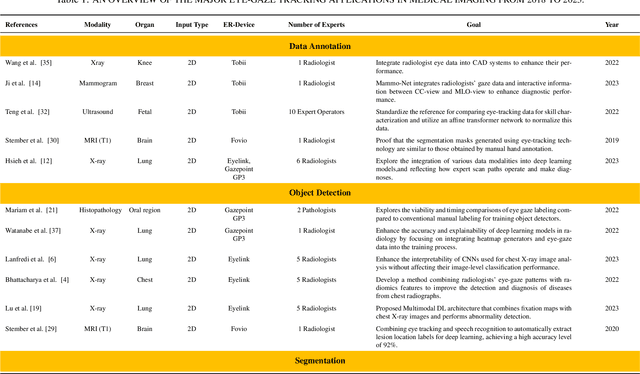
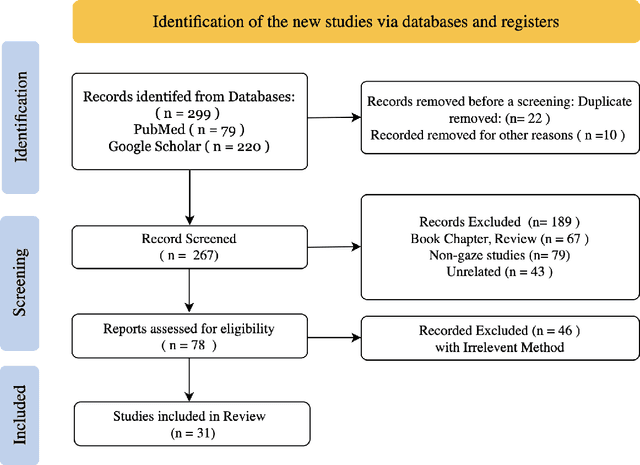
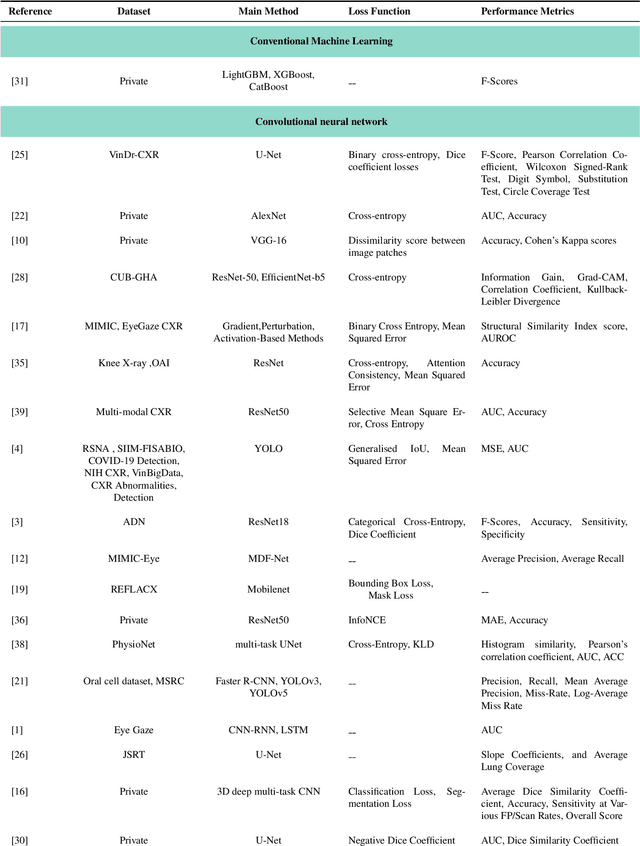
Eye-gaze tracking research offers significant promise in enhancing various healthcare-related tasks, above all in medical image analysis and interpretation. Eye tracking, a technology that monitors and records the movement of the eyes, provides valuable insights into human visual attention patterns. This technology can transform how healthcare professionals and medical specialists engage with and analyze diagnostic images, offering a more insightful and efficient approach to medical diagnostics. Hence, extracting meaningful features and insights from medical images by leveraging eye-gaze data improves our understanding of how radiologists and other medical experts monitor, interpret, and understand images for diagnostic purposes. Eye-tracking data, with intricate human visual attention patterns embedded, provides a bridge to integrating artificial intelligence (AI) development and human cognition. This integration allows novel methods to incorporate domain knowledge into machine learning (ML) and deep learning (DL) approaches to enhance their alignment with human-like perception and decision-making. Moreover, extensive collections of eye-tracking data have also enabled novel ML/DL methods to analyze human visual patterns, paving the way to a better understanding of human vision, attention, and cognition. This systematic review investigates eye-gaze tracking applications and methodologies for enhancing ML/DL algorithms for medical image analysis in depth.
Towards Machine Learning-based Quantitative Hyperspectral Image Guidance for Brain Tumor Resection
Nov 24, 2023Complete resection of malignant gliomas is hampered by the difficulty in distinguishing tumor cells at the infiltration zone. Fluorescence guidance with 5-ALA assists in reaching this goal. Using hyperspectral imaging, previous work characterized five fluorophores' emission spectra in most human brain tumors. In this paper, the effectiveness of these five spectra was explored for different tumor and tissue classification tasks in 184 patients (891 hyperspectral measurements) harboring low- (n=30) and high-grade gliomas (n=115), non-glial primary brain tumors (n=19), radiation necrosis (n=2), miscellaneous (n=10) and metastases (n=8). Four machine learning models were trained to classify tumor type, grade, glioma margins and IDH mutation. Using random forests and multi-layer perceptrons, the classifiers achieved average test accuracies of 84-87%, 96%, 86%, and 93% respectively. All five fluorophore abundances varied between tumor margin types and tumor grades (p < 0.01). For tissue type, at least four of the five fluorophore abundances were found to be significantly different (p < 0.01) between all classes. These results demonstrate the fluorophores' differing abundances in different tissue classes, as well as the value of the five fluorophores as potential optical biomarkers, opening new opportunities for intraoperative classification systems in fluorescence-guided neurosurgery.
TPMIL: Trainable Prototype Enhanced Multiple Instance Learning for Whole Slide Image Classification
May 01, 2023Digital pathology based on whole slide images (WSIs) plays a key role in cancer diagnosis and clinical practice. Due to the high resolution of the WSI and the unavailability of patch-level annotations, WSI classification is usually formulated as a weakly supervised problem, which relies on multiple instance learning (MIL) based on patches of a WSI. In this paper, we aim to learn an optimal patch-level feature space by integrating prototype learning with MIL. To this end, we develop a Trainable Prototype enhanced deep MIL (TPMIL) framework for weakly supervised WSI classification. In contrast to the conventional methods which rely on a certain number of selected patches for feature space refinement, we softly cluster all the instances by allocating them to their corresponding prototypes. Additionally, our method is able to reveal the correlations between different tumor subtypes through distances between corresponding trained prototypes. More importantly, TPMIL also enables to provide a more accurate interpretability based on the distance of the instances from the trained prototypes which serves as an alternative to the conventional attention score-based interpretability. We test our method on two WSI datasets and it achieves a new SOTA. GitHub repository: https://github.com/LitaoYang-Jet/TPMIL