 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplementation and Application of an Intelligibility Protocol for Interaction with an LLM
Oct 27, 2024Our interest is in constructing interactive systems involving a human-expert interacting with a machine learning engine on data analysis tasks. This is of relevance when addressing complex problems arising in areas of science, the environment, medicine and so on, which are not immediately amenable to the usual methods of statistical or mathematical modelling. In such situations, it is possible that harnessing human expertise and creativity to modern machine-learning capabilities of identifying patterns by constructing new internal representations of the data may provide some insight to possible solutions. In this paper, we examine the implementation of an abstract protocol developed for interaction between agents, each capable of constructing predictions and explanations. The \PXP protocol, described in [12] is motivated by the notion of ''two-way intelligibility'' and is specified using a pair of communicating finite-state machines. While the formalisation allows the authors to prove several properties about the protocol, no implementation was presented. Here, we address this shortcoming for the case in which one of the agents acts as a ''generator'' using a large language model (LLM) and the other is an agent that acts as a ''tester'' using either a human-expert, or a proxy for a human-expert (for example, a database compiled using human-expertise). We believe these use-cases will be a widely applicable form of interaction for problems of the kind mentioned above. We present an algorithmic description of general-purpose implementation, and conduct preliminary experiments on its use in two different areas (radiology and drug-discovery). The experimental results provide early evidence in support of the protocol's capability of capturing one- and two-way intelligibility in human-LLM in the manner proposed in [12].
Open-Source Molecular Processing Pipeline for Generating Molecules
Aug 12, 2024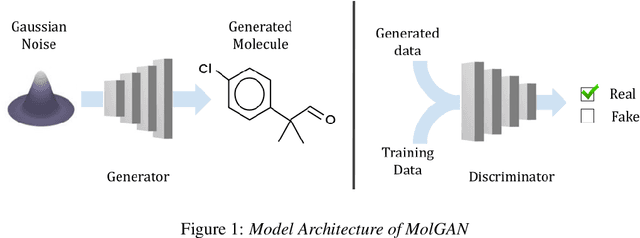
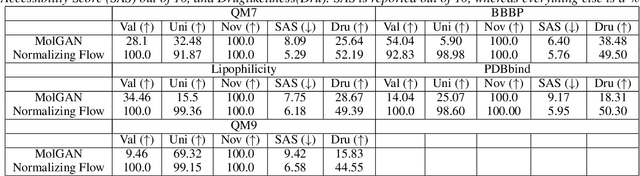
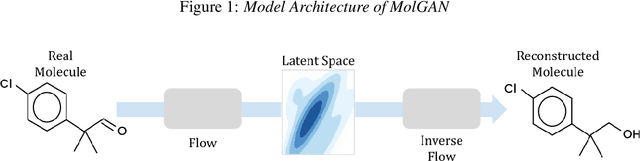

Generative models for molecules have shown considerable promise for use in computational chemistry, but remain difficult to use for non-experts. For this reason, we introduce open-source infrastructure for easily building generative molecular models into the widely used DeepChem [Ramsundar et al., 2019] library with the aim of creating a robust and reusable molecular generation pipeline. In particular, we add high quality PyTorch [Paszke et al., 2019] implementations of the Molecular Generative Adversarial Networks (MolGAN) [Cao and Kipf, 2022] and Normalizing Flows [Papamakarios et al., 2021]. Our implementations show strong performance comparable with past work [Kuznetsov and Polykovskiy, 2021, Cao and Kipf, 2022].
CountCLIP -- Teaching CLIP to Count to Ten
Jun 05, 2024



Large vision-language models (VLMs) are shown to learn rich joint image-text representations enabling high performances in relevant downstream tasks. However, they fail to showcase their quantitative understanding of objects, and they lack good counting-aware representation. This paper conducts a reproducibility study of 'Teaching CLIP to Count to Ten' (Paiss et al., 2023), which presents a method to finetune a CLIP model (Radford et al., 2021) to improve zero-shot counting accuracy in an image while maintaining the performance for zero-shot classification by introducing a counting-contrastive loss term. We improve the model's performance on a smaller subset of their training data with lower computational resources. We verify these claims by reproducing their study with our own code. The implementation can be found at https://github.com/SforAiDl/CountCLIP.
Predicting ATP binding sites in protein sequences using Deep Learning and Natural Language Processing
Feb 02, 2024Predicting ATP-Protein Binding sites in genes is of great significance in the field of Biology and Medicine. The majority of research in this field has been conducted through time- and resource-intensive 'wet experiments' in laboratories. Over the years, researchers have been investigating computational methods computational methods to accomplish the same goals, utilising the strength of advanced Deep Learning and NLP algorithms. In this paper, we propose to develop methods to classify ATP-Protein binding sites. We conducted various experiments mainly using PSSMs and several word embeddings as features. We used 2D CNNs and LightGBM classifiers as our chief Deep Learning Algorithms. The MP3Vec and BERT models have also been subjected to testing in our study. The outcomes of our experiments demonstrated improvement over the state-of-the-art benchmarks.