 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouting End User Queries to Enterprise Databases
Jan 27, 2026We address the task of routing natural language queries in multi-database enterprise environments. We construct realistic benchmarks by extending existing NL-to-SQL datasets. Our study shows that routing becomes increasingly challenging with larger, domain-overlapping DB repositories and ambiguous queries, motivating the need for more structured and robust reasoning-based solutions. By explicitly modelling schema coverage, structural connectivity, and fine-grained semantic alignment, the proposed modular, reasoning-driven reranking strategy consistently outperforms embedding-only and direct LLM-prompting baselines across all the metrics.
Engineering Scientific Assistants using Interactive Structured Induction of Programs
Mar 18, 2025We are interested in the construction of software that can act as scientific assistants to domain specialists. It is expected that such assistants will be needed to accelerate the identification of ways to address complex problems requiring urgent solutions. In this paper, our focus is not on a specific scientific problem, but on the software-engineering of such 'science accelerators'. Recent developments in 'No Code' techniques would seem to suggest that scientist can simply hypothesise solutions simply by conversing with a large language model (LLM). However, for complex scientific problems, this seems unlikely given the current state of LLM technology. What does appear feasible is that a software engineer can use LLMs to rapidly construct programs for use by a domain-specialist, including the specialist's requirements expressed in natural language. We propose the design of an interactive form of 'structured' inductive programming in which a software-engineer and an LLM collaboratively construct an 'assistant' for a scientific data analysis. The paper describes a simple implementation called iStrucInd that adapts a '2-way Intelligibility' protocol to implement the interaction between the software engineer and the LLM. We test the tool on two different non-trivial scientific data analysis tasks. Specifically, we compare the system constructed by iStrucInd against systems constructed manually and by Low Code/No Code methods along dimensions of: (a) program performance; (b) program quality; and (c) programming effort. The results show iStrucInd allows a software engineer to develop better programs faster suggesting interactive structured induction can play a useful role in the rapid construction of scientific assistants.
Implementation and Application of an Intelligibility Protocol for Interaction with an LLM
Oct 27, 2024Our interest is in constructing interactive systems involving a human-expert interacting with a machine learning engine on data analysis tasks. This is of relevance when addressing complex problems arising in areas of science, the environment, medicine and so on, which are not immediately amenable to the usual methods of statistical or mathematical modelling. In such situations, it is possible that harnessing human expertise and creativity to modern machine-learning capabilities of identifying patterns by constructing new internal representations of the data may provide some insight to possible solutions. In this paper, we examine the implementation of an abstract protocol developed for interaction between agents, each capable of constructing predictions and explanations. The \PXP protocol, described in [12] is motivated by the notion of ''two-way intelligibility'' and is specified using a pair of communicating finite-state machines. While the formalisation allows the authors to prove several properties about the protocol, no implementation was presented. Here, we address this shortcoming for the case in which one of the agents acts as a ''generator'' using a large language model (LLM) and the other is an agent that acts as a ''tester'' using either a human-expert, or a proxy for a human-expert (for example, a database compiled using human-expertise). We believe these use-cases will be a widely applicable form of interaction for problems of the kind mentioned above. We present an algorithmic description of general-purpose implementation, and conduct preliminary experiments on its use in two different areas (radiology and drug-discovery). The experimental results provide early evidence in support of the protocol's capability of capturing one- and two-way intelligibility in human-LLM in the manner proposed in [12].
Concept Distillation from Strong to Weak Models via Hypotheses-to-Theories Prompting
Aug 18, 2024



Hand-crafting high quality prompts to optimize the performance of language models is a complicated and labor-intensive process. Furthermore, when migrating to newer, smaller, or weaker models (possibly due to latency or cost gains), prompts need to be updated to re-optimize the task performance. We propose Concept Distillation (CD), an automatic prompt optimization technique for enhancing weaker models on complex tasks. CD involves: (1) collecting mistakes made by weak models with a base prompt (initialization), (2) using a strong model to generate reasons for these mistakes and create rules/concepts for weak models (induction), and (3) filtering these rules based on validation set performance and integrating them into the base prompt (deduction/verification). We evaluated CD on NL2Code and mathematical reasoning tasks, observing significant performance boosts for small and weaker language models. Notably, Mistral-7B's accuracy on Multi-Arith increased by 20%, and Phi-3-mini-3.8B's accuracy on HumanEval rose by 34%. Compared to other automated methods, CD offers an effective, cost-efficient strategy for improving weak models' performance on complex tasks and enables seamless workload migration across different language models without compromising performance.
IKD+: Reliable Low Complexity Deep Models For Retinopathy Classification
Mar 04, 2023



Deep neural network (DNN) models for retinopathy have estimated predictive accuracies in the mid-to-high 90%. However, the following aspects remain unaddressed: State-of-the-art models are complex and require substantial computational infrastructure to train and deploy; The reliability of predictions can vary widely. In this paper, we focus on these aspects and propose a form of iterative knowledge distillation(IKD), called IKD+ that incorporates a tradeoff between size, accuracy and reliability. We investigate the functioning of IKD+ using two widely used techniques for estimating model calibration (Platt-scaling and temperature-scaling), using the best-performing model available, which is an ensemble of EfficientNets with approximately 100M parameters. We demonstrate that IKD+ equipped with temperature-scaling results in models that show up to approximately 500-fold decreases in the number of parameters than the original ensemble without a significant loss in accuracy. In addition, calibration scores (reliability) for the IKD+ models are as good as or better than the base mode
Domain-Specific Pretraining Improves Confidence in Whole Slide Image Classification
Feb 20, 2023Whole Slide Images (WSIs) or histopathology images are used in digital pathology. WSIs pose great challenges to deep learning models for clinical diagnosis, owing to their size and lack of pixel-level annotations. With the recent advancements in computational pathology, newer multiple-instance learning-based models have been proposed. Multiple-instance learning for WSIs necessitates creating patches and uses the encoding of these patches for diagnosis. These models use generic pre-trained models (ResNet-50 pre-trained on ImageNet) for patch encoding. The recently proposed KimiaNet, a DenseNet121 model pre-trained on TCGA slides, is a domain-specific pre-trained model. This paper shows the effect of domain-specific pre-training on WSI classification. To investigate the impact of domain-specific pre-training, we considered the current state-of-the-art multiple-instance learning models, 1) CLAM, an attention-based model, and 2) TransMIL, a self-attention-based model, and evaluated the models' confidence and predictive performance in detecting primary brain tumors - gliomas. Domain-specific pre-training improves the confidence of the models and also achieves a new state-of-the-art performance of WSI-based glioma subtype classification, showing a high clinical applicability in assisting glioma diagnosis.
A Protocol for Intelligible Interaction Between Agents That Learn and Explain
Jan 04, 2023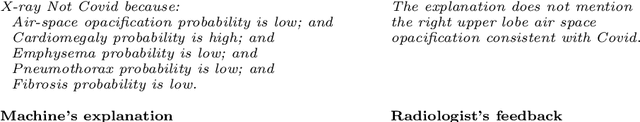

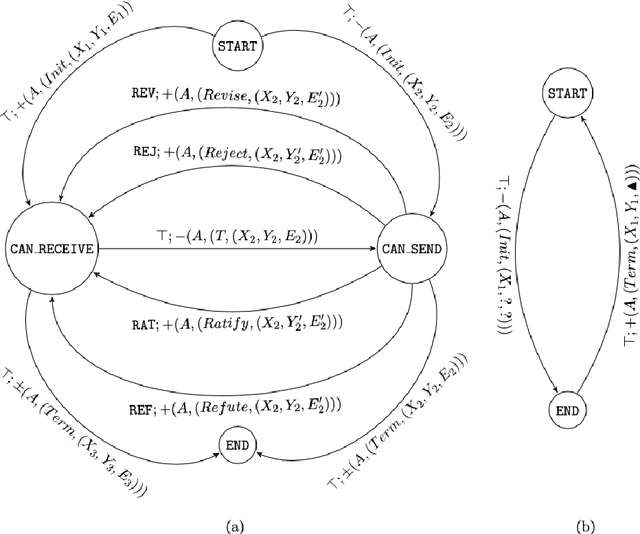

Recent engineering developments have seen the emergence of Machine Learning (ML) as a powerful form of data analysis with widespread applicability beyond its historical roots in the design of autonomous agents. However, relatively little attention has been paid to the interaction between people and ML systems. Recent developments on Explainable ML address this by providing visual and textual information on how the ML system arrived at a conclusion. In this paper we view the interaction between humans and ML systems within the broader context of interaction between agents capable of learning and explanation. Within this setting, we argue that it is more helpful to view the interaction as characterised by two-way intelligibility of information rather than once-off explanation of a prediction. We formulate two-way intelligibility as a property of a communication protocol. Development of the protocol is motivated by a set of `Intelligibility Axioms' for decision-support systems that use ML with a human-in-the-loop. The axioms are intended as sufficient criteria to claim that: (a) information provided by a human is intelligible to an ML system; and (b) information provided by an ML system is intelligible to a human. The axioms inform the design of a general synchronous interaction model between agents capable of learning and explanation. We identify conditions of compatibility between agents that result in bounded communication, and define Weak and Strong Two-Way Intelligibility between agents as properties of the communication protocol.
Neural Feature-Adaptation for Symbolic Predictions Using Pre-Training and Semantic Loss
Nov 29, 2022



We are interested in neurosymbolic systems consisting of a high-level symbolic layer for explainable prediction in terms of human-intelligible concepts; and a low-level neural layer for extracting symbols required to generate the symbolic explanation. Real data is often imperfect meaning that even if the symbolic theory remains unchanged, we may still need to address the problem of mapping raw data to high-level symbols, each time there is a change in the data acquisition environment or equipment. Manual (re-)annotation of the raw data each time this happens is laborious and expensive; and automated labelling methods are often imperfect, especially for complex problems. NEUROLOG proposed the use of a semantic loss function that allows an existing feature-based symbolic model to guide the extraction of feature-values from raw data, using `abduction'. However, the experiments demonstrating the use of semantic loss through abduction appear to rely heavily on a domain-specific pre-processing step that enables a prior delineation of feature locations in the raw data. We examine the use of semantic loss in domains where such pre-processing is not possible, or is not obvious. We show that without any prior information about the features, the NEUROLOG approach can continue to predict accurately even with substantially incorrect feature predictions. We show also that prior information about the features in the form of even imperfect pre-training can help correct this situation. These findings are replicated on the original problem considered by NEUROLOG, without the use of feature-delineation. This suggests that symbolic explanations constructed for data in a domain could be re-used in a related domain, by `feature-adaptation' of pre-trained neural extractors using the semantic loss function constrained by abductive feedback.
Knowledge-based Analogical Reasoning in Neuro-symbolic Latent Spaces
Sep 19, 2022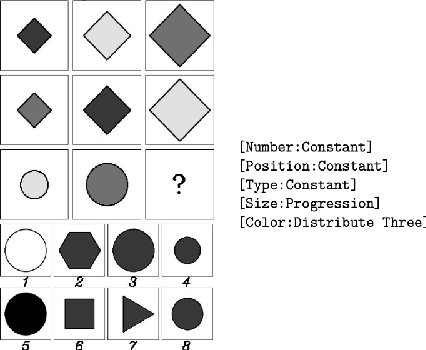
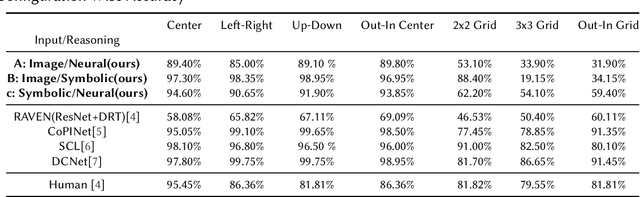
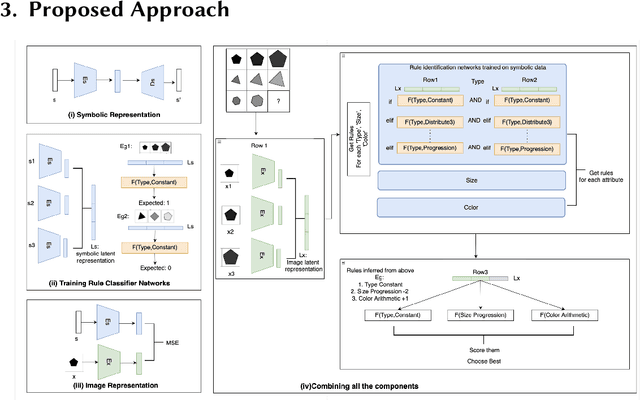
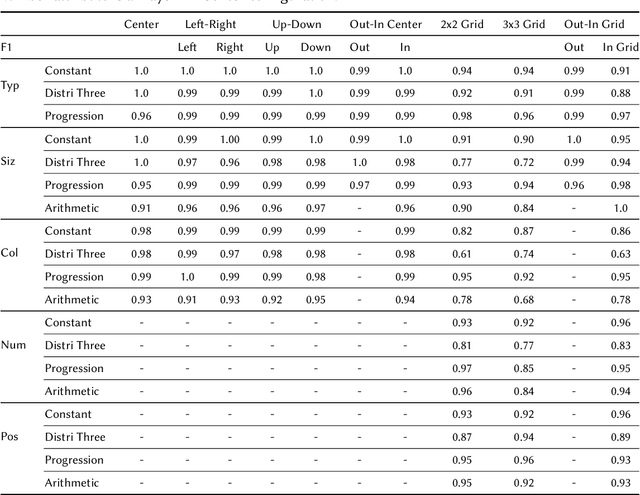
Analogical Reasoning problems challenge both connectionist and symbolic AI systems as these entail a combination of background knowledge, reasoning and pattern recognition. While symbolic systems ingest explicit domain knowledge and perform deductive reasoning, they are sensitive to noise and require inputs be mapped to preset symbolic features. Connectionist systems on the other hand can directly ingest rich input spaces such as images, text or speech and recognize pattern even with noisy inputs. However, connectionist models struggle to include explicit domain knowledge for deductive reasoning. In this paper, we propose a framework that combines the pattern recognition abilities of neural networks with symbolic reasoning and background knowledge for solving a class of Analogical Reasoning problems where the set of attributes and possible relations across them are known apriori. We take inspiration from the 'neural algorithmic reasoning' approach [DeepMind 2020] and use problem-specific background knowledge by (i) learning a distributed representation based on a symbolic model of the problem (ii) training neural-network transformations reflective of the relations involved in the problem and finally (iii) training a neural network encoder from images to the distributed representation in (i). These three elements enable us to perform search-based reasoning using neural networks as elementary functions manipulating distributed representations. We test this on visual analogy problems in RAVENs Progressive Matrices, and achieve accuracy competitive with human performance and, in certain cases, superior to initial end-to-end neural-network based approaches. While recent neural models trained at scale yield SOTA, our novel neuro-symbolic reasoning approach is a promising direction for this problem, and is arguably more general, especially for problems where domain knowledge is available.
Composition of Relational Features with an Application to Explaining Black-Box Predictors
Jun 01, 2022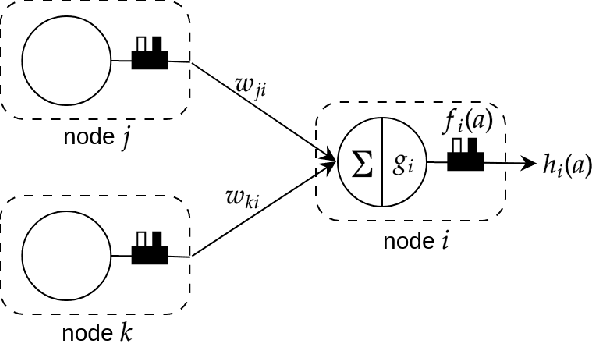
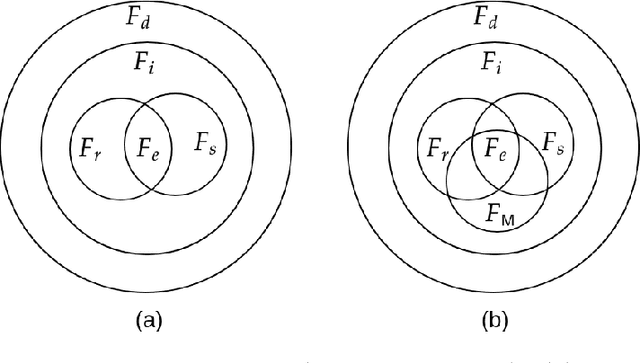


Relational machine learning programs like those developed in Inductive Logic Programming (ILP) offer several advantages: (1) The ability to model complex relationships amongst data instances; (2) The use of domain-specific relations during model construction; and (3) The models constructed are human-readable, which is often one step closer to being human-understandable. However, these ILP-like methods have not been able to capitalise fully on the rapid hardware, software and algorithmic developments fuelling current developments in deep neural networks. In this paper, we treat relational features as functions and use the notion of generalised composition of functions to derive complex functions from simpler ones. We formulate the notion of a set of $\text{M}$-simple features in a mode language $\text{M}$ and identify two composition operators ($\rho_1$ and $\rho_2$) from which all possible complex features can be derived. We use these results to implement a form of "explainable neural network" called Compositional Relational Machines, or CRMs, which are labelled directed-acyclic graphs. The vertex-label for any vertex $j$ in the CRM contains a feature-function $f_j$ and a continuous activation function $g_j$. If $j$ is a "non-input" vertex, then $f_j$ is the composition of features associated with vertices in the direct predecessors of $j$. Our focus is on CRMs in which input vertices (those without any direct predecessors) all have $\text{M}$-simple features in their vertex-labels. We provide a randomised procedure for constructing and learning such CRMs. Using a notion of explanations based on the compositional structure of features in a CRM, we provide empirical evidence on synthetic data of the ability to identify appropriate explanations; and demonstrate the use of CRMs as 'explanation machines' for black-box models that do not provide explanations for their predictions.