 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefining Reference Sequences for Nocardia Species by Similarity and Clustering Analyses of 16S rRNA Gene Sequence Data
Nov 29, 2023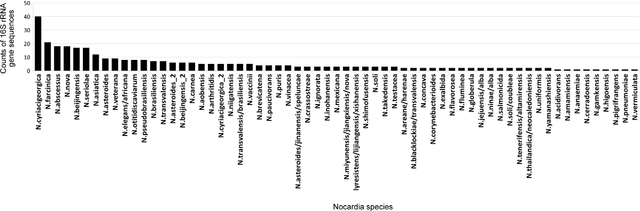
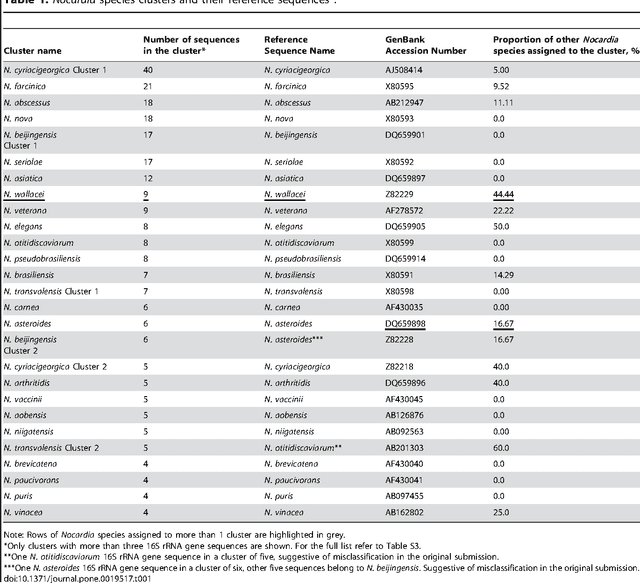
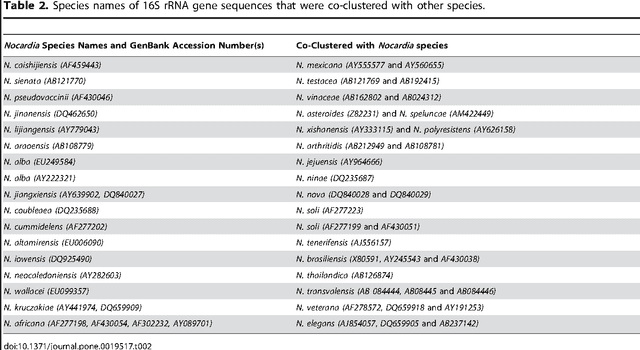
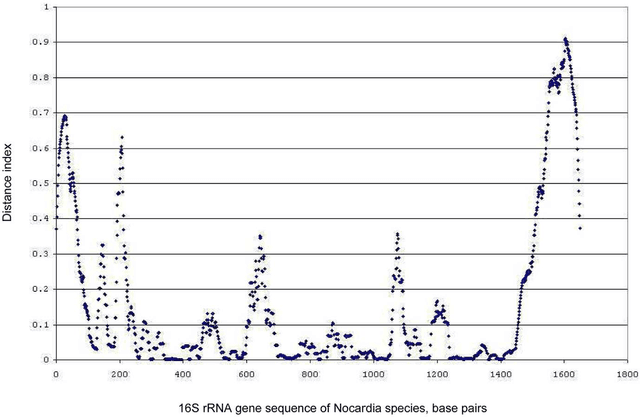
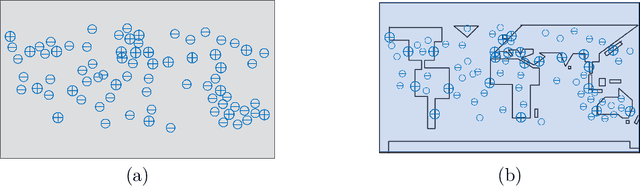
The intra- and inter-species genetic diversity of bacteria and the absence of 'reference', or the most representative, sequences of individual species present a significant challenge for sequence-based identification. The aims of this study were to determine the utility, and compare the performance of several clustering and classification algorithms to identify the species of 364 sequences of 16S rRNA gene with a defined species in GenBank, and 110 sequences of 16S rRNA gene with no defined species, all within the genus Nocardia. A total of 364 16S rRNA gene sequences of Nocardia species were studied. In addition, 110 16S rRNA gene sequences assigned only to the Nocardia genus level at the time of submission to GenBank were used for machine learning classification experiments. Different clustering algorithms were compared with a novel algorithm or the linear mapping (LM) of the distance matrix. Principal Components Analysis was used for the dimensionality reduction and visualization. Results: The LM algorithm achieved the highest performance and classified the set of 364 16S rRNA sequences into 80 clusters, the majority of which (83.52%) corresponded with the original species. The most representative 16S rRNA sequences for individual Nocardia species have been identified as 'centroids' in respective clusters from which the distances to all other sequences were minimized; 110 16S rRNA gene sequences with identifications recorded only at the genus level were classified using machine learning methods. Simple kNN machine learning demonstrated the highest performance and classified Nocardia species sequences with an accuracy of 92.7% and a mean frequency of 0.578.
A Protocol for Intelligible Interaction Between Agents That Learn and Explain
Jan 04, 2023

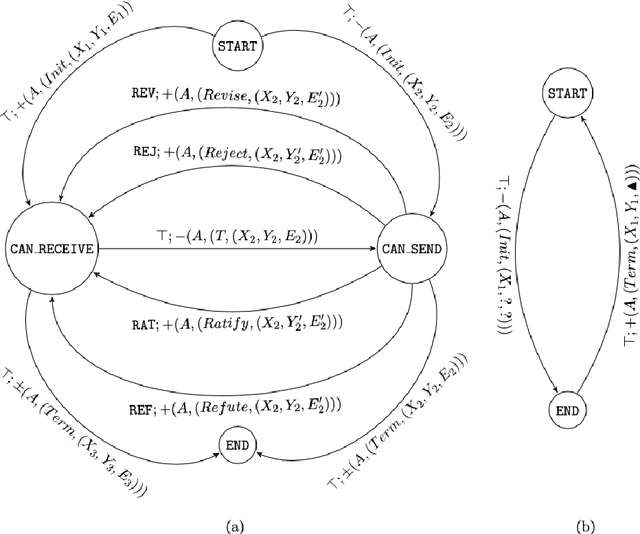

Recent engineering developments have seen the emergence of Machine Learning (ML) as a powerful form of data analysis with widespread applicability beyond its historical roots in the design of autonomous agents. However, relatively little attention has been paid to the interaction between people and ML systems. Recent developments on Explainable ML address this by providing visual and textual information on how the ML system arrived at a conclusion. In this paper we view the interaction between humans and ML systems within the broader context of interaction between agents capable of learning and explanation. Within this setting, we argue that it is more helpful to view the interaction as characterised by two-way intelligibility of information rather than once-off explanation of a prediction. We formulate two-way intelligibility as a property of a communication protocol. Development of the protocol is motivated by a set of `Intelligibility Axioms' for decision-support systems that use ML with a human-in-the-loop. The axioms are intended as sufficient criteria to claim that: (a) information provided by a human is intelligible to an ML system; and (b) information provided by an ML system is intelligible to a human. The axioms inform the design of a general synchronous interaction model between agents capable of learning and explanation. We identify conditions of compatibility between agents that result in bounded communication, and define Weak and Strong Two-Way Intelligibility between agents as properties of the communication protocol.
One-way Explainability Isn't The Message
May 05, 2022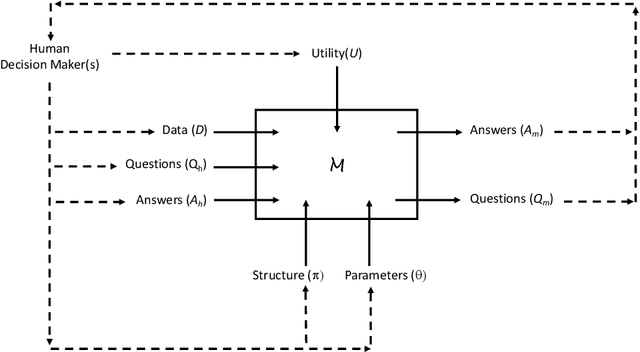

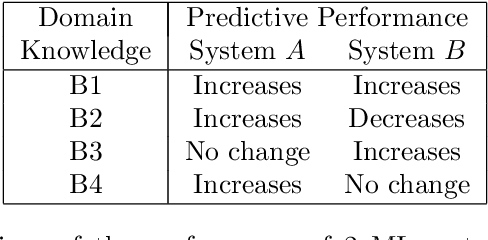
Recent engineering developments in specialised computational hardware, data-acquisition and storage technology have seen the emergence of Machine Learning (ML) as a powerful form of data analysis with widespread applicability beyond its historical roots in the design of autonomous agents. However -- possibly because of its origins in the development of agents capable of self-discovery -- relatively little attention has been paid to the interaction between people and ML. In this paper we are concerned with the use of ML in automated or semi-automated tools that assist one or more human decision makers. We argue that requirements on both human and machine in this context are significantly different to the use of ML either as part of autonomous agents for self-discovery or as part statistical data analysis. Our principal position is that the design of such human-machine systems should be driven by repeated, two-way intelligibility of information rather than one-way explainability of the ML-system's recommendations. Iterated rounds of intelligible information exchange, we think, will characterise the kinds of collaboration that will be needed to understand complex phenomena for which neither man or machine have complete answers. We propose operational principles -- we call them Intelligibility Axioms -- to guide the design of a collaborative decision-support system. The principles are concerned with: (a) what it means for information provided by the human to be intelligible to the ML system; and (b) what it means for an explanation provided by an ML system to be intelligible to a human. Using examples from the literature on the use of ML for drug-design and in medicine, we demonstrate cases where the conditions of the axioms are met. We describe some additional requirements needed for the design of a truly collaborative decision-support system.
Logical Explanations for Deep Relational Machines Using Relevance Information
Jul 02, 2018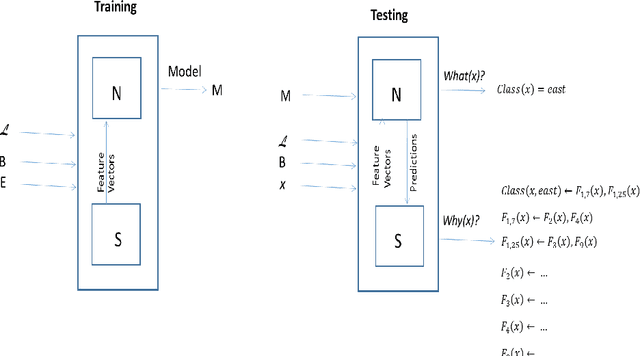
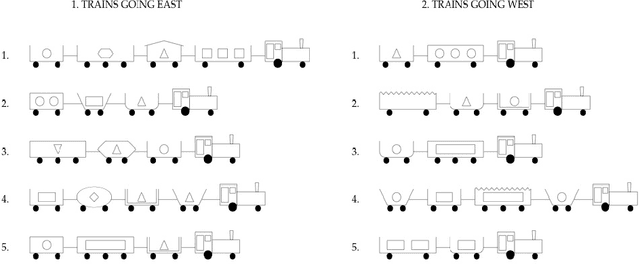
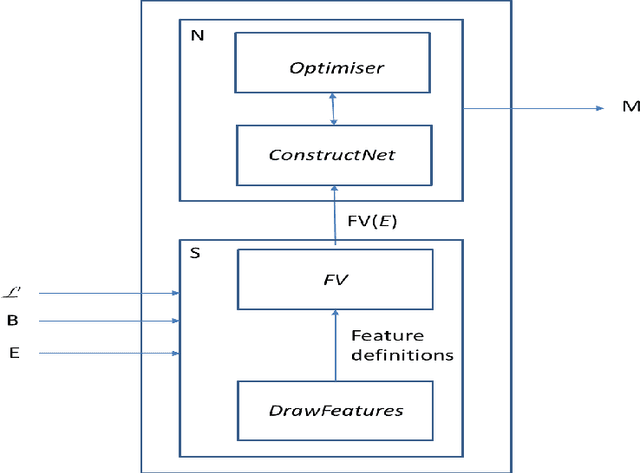
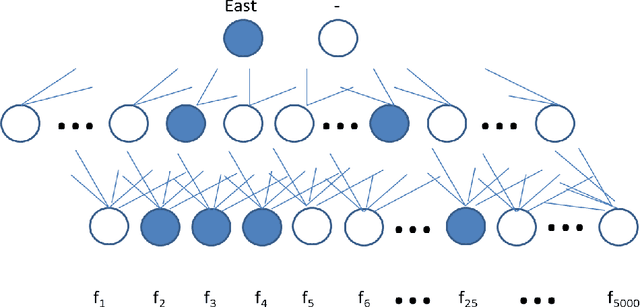
Our interest in this paper is in the construction of symbolic explanations for predictions made by a deep neural network. We will focus attention on deep relational machines (DRMs, first proposed by H. Lodhi). A DRM is a deep network in which the input layer consists of Boolean-valued functions (features) that are defined in terms of relations provided as domain, or background, knowledge. Our DRMs differ from those proposed by Lodhi, which use an Inductive Logic Programming (ILP) engine to first select features (we use random selections from a space of features that satisfies some approximate constraints on logical relevance and non-redundancy). But why do the DRMs predict what they do? One way of answering this is the LIME setting, in which readable proxies for a black-box predictor. The proxies are intended only to model the predictions of the black-box in local regions of the instance-space. But readability alone may not enough: to be understandable, the local models must use relevant concepts in an meaningful manner. We investigate the use of a Bayes-like approach to identify logical proxies for local predictions of a DRM. We show: (a) DRM's with our randomised propositionalization method achieve state-of-the-art predictive performance; (b) Models in first-order logic can approximate the DRM's prediction closely in a small local region; and (c) Expert-provided relevance information can play the role of a prior to distinguish between logical explanations that perform equivalently on prediction alone.
B-CNN: Branch Convolutional Neural Network for Hierarchical Classification
Oct 05, 2017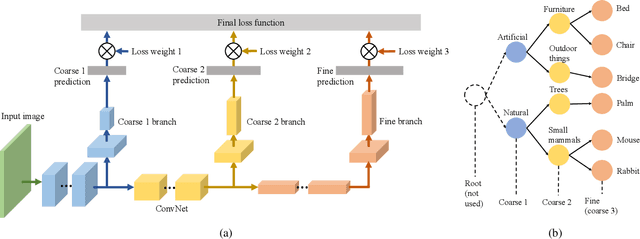
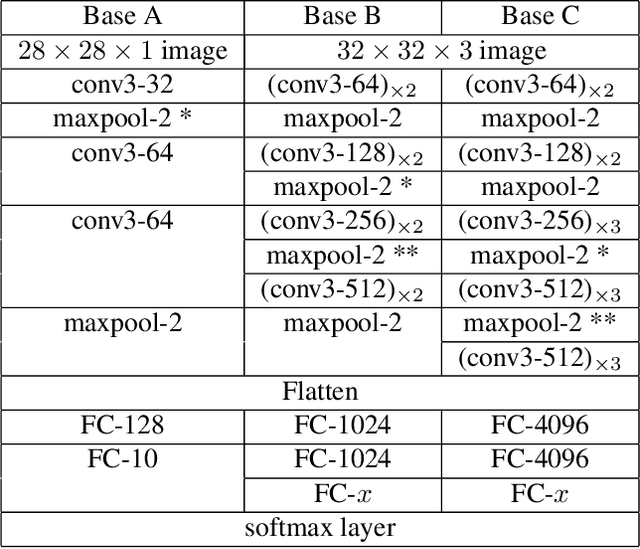
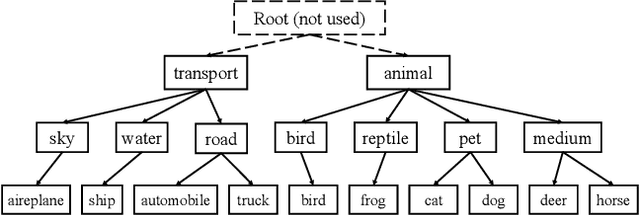
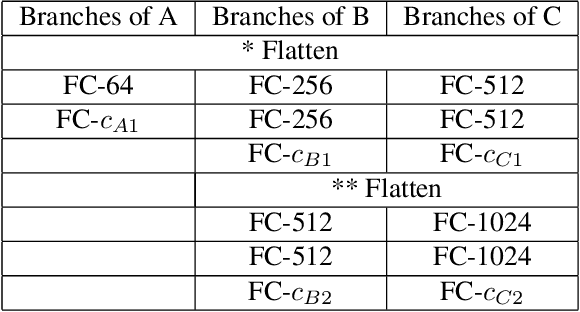
Convolutional Neural Network (CNN) image classifiers are traditionally designed to have sequential convolutional layers with a single output layer. This is based on the assumption that all target classes should be treated equally and exclusively. However, some classes can be more difficult to distinguish than others, and classes may be organized in a hierarchy of categories. At the same time, a CNN is designed to learn internal representations that abstract from the input data based on its hierarchical layered structure. So it is natural to ask if an inverse of this idea can be applied to learn a model that can predict over a classification hierarchy using multiple output layers in decreasing order of class abstraction. In this paper, we introduce a variant of the traditional CNN model named the Branch Convolutional Neural Network (B-CNN). A B-CNN model outputs multiple predictions ordered from coarse to fine along the concatenated convolutional layers corresponding to the hierarchical structure of the target classes, which can be regarded as a form of prior knowledge on the output. To learn with B-CNNs a novel training strategy, named the Branch Training strategy (BT-strategy), is introduced which balances the strictness of the prior with the freedom to adjust parameters on the output layers to minimize the loss. In this way we show that CNN based models can be forced to learn successively coarse to fine concepts in the internal layers at the output stage, and that hierarchical prior knowledge can be adopted to boost CNN models' classification performance. Our models are evaluated to show that the B-CNN extensions improve over the corresponding baseline CNN on the benchmark datasets MNIST, CIFAR-10 and CIFAR-100.
Word Vector Enrichment of Low Frequency Words in the Bag-of-Words Model for Short Text Multi-class Classification Problems
Sep 18, 2017
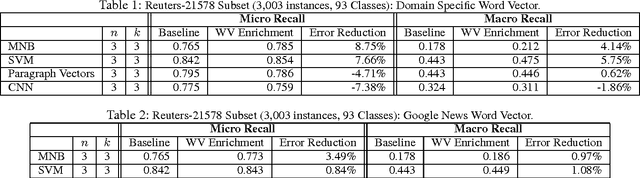
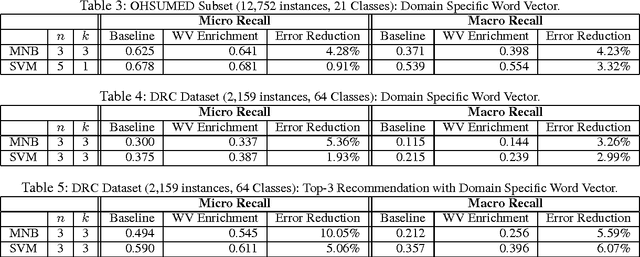
The bag-of-words model is a standard representation of text for many linear classifier learners. In many problem domains, linear classifiers are preferred over more complex models due to their efficiency, robustness and interpretability, and the bag-of-words text representation can capture sufficient information for linear classifiers to make highly accurate predictions. However in settings where there is a large vocabulary, large variance in the frequency of terms in the training corpus, many classes and very short text (e.g., single sentences or document titles) the bag-of-words representation becomes extremely sparse, and this can reduce the accuracy of classifiers. A particular issue in such settings is that short texts tend to contain infrequently occurring or rare terms which lack class-conditional evidence. In this work we introduce a method for enriching the bag-of-words model by complementing such rare term information with related terms from both general and domain-specific Word Vector models. By reducing sparseness in the bag-of-words models, our enrichment approach achieves improved classification over several baseline classifiers in a variety of text classification problems. Our approach is also efficient because it requires no change to the linear classifier before or during training, since bag-of-words enrichment applies only to text being classified.