 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear normalised hash function for clustering gene sequences and identifying reference sequences from multiple sequence alignments
Nov 29, 2023The aim of this study was to develop a method that would identify the cluster centroids and the optimal number of clusters for a given sensitivity level and could work equally well for the different sequence datasets. A novel method that combines the linear mapping hash function and multiple sequence alignment (MSA) was developed. This method takes advantage of the already sorted by similarity sequences from the MSA output, and identifies the optimal number of clusters, clusters cut-offs, and clusters centroids that can represent reference gene vouchers for the different species. The linear mapping hash function can map an already ordered by similarity distance matrix to indices to reveal gaps in the values around which the optimal cut-offs of the different clusters can be identified. The method was evaluated using sets of closely related (16S rRNA gene sequences of Nocardia species) and highly variable (VP1 genomic region of Enterovirus 71) sequences and outperformed existing unsupervised machine learning clustering methods and dimensionality reduction methods. This method does not require prior knowledge of the number of clusters or the distance between clusters, handles clusters of different sizes and shapes, and scales linearly with the dataset. The combination of MSA with the linear mapping hash function is a computationally efficient way of gene sequence clustering and can be a valuable tool for the assessment of similarity, clustering of different microbial genomes, identifying reference sequences, and for the study of evolution of bacteria and viruses.
Defining Reference Sequences for Nocardia Species by Similarity and Clustering Analyses of 16S rRNA Gene Sequence Data
Nov 29, 2023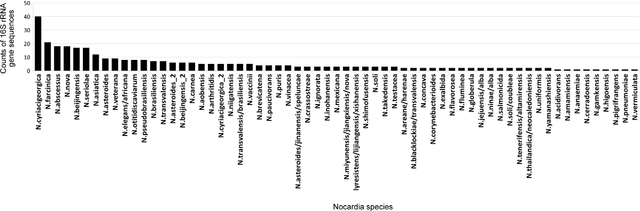
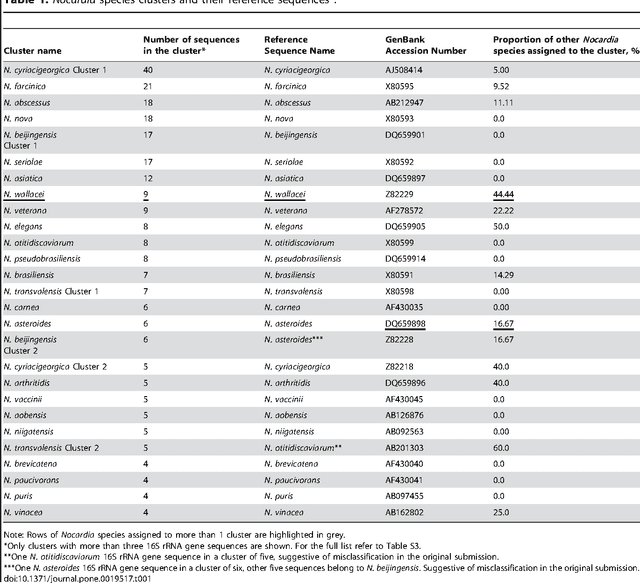
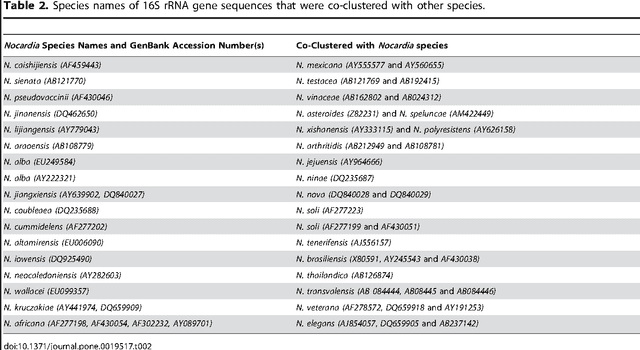
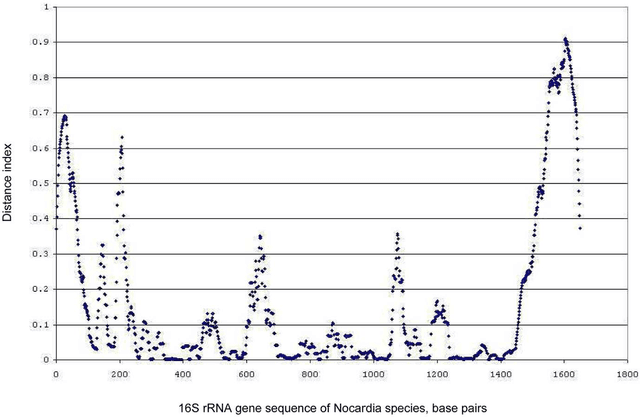
The intra- and inter-species genetic diversity of bacteria and the absence of 'reference', or the most representative, sequences of individual species present a significant challenge for sequence-based identification. The aims of this study were to determine the utility, and compare the performance of several clustering and classification algorithms to identify the species of 364 sequences of 16S rRNA gene with a defined species in GenBank, and 110 sequences of 16S rRNA gene with no defined species, all within the genus Nocardia. A total of 364 16S rRNA gene sequences of Nocardia species were studied. In addition, 110 16S rRNA gene sequences assigned only to the Nocardia genus level at the time of submission to GenBank were used for machine learning classification experiments. Different clustering algorithms were compared with a novel algorithm or the linear mapping (LM) of the distance matrix. Principal Components Analysis was used for the dimensionality reduction and visualization. Results: The LM algorithm achieved the highest performance and classified the set of 364 16S rRNA sequences into 80 clusters, the majority of which (83.52%) corresponded with the original species. The most representative 16S rRNA sequences for individual Nocardia species have been identified as 'centroids' in respective clusters from which the distances to all other sequences were minimized; 110 16S rRNA gene sequences with identifications recorded only at the genus level were classified using machine learning methods. Simple kNN machine learning demonstrated the highest performance and classified Nocardia species sequences with an accuracy of 92.7% and a mean frequency of 0.578.
Chat Failures and Troubles: Reasons and Solutions
Sep 07, 2023This paper examines some common problems in Human-Robot Interaction (HRI) causing failures and troubles in Chat. A given use case's design decisions start with the suitable robot, the suitable chatting model, identifying common problems that cause failures, identifying potential solutions, and planning continuous improvement. In conclusion, it is recommended to use a closed-loop control algorithm that guides the use of trained Artificial Intelligence (AI) pre-trained models and provides vocabulary filtering, re-train batched models on new datasets, learn online from data streams, and/or use reinforcement learning models to self-update the trained models and reduce errors.
* 4 pages
Enhancing Deep Learning Models through Tensorization: A Comprehensive Survey and Framework
Sep 07, 2023The burgeoning growth of public domain data and the increasing complexity of deep learning model architectures have underscored the need for more efficient data representation and analysis techniques. This paper is motivated by the work of Helal (2023) and aims to present a comprehensive overview of tensorization. This transformative approach bridges the gap between the inherently multidimensional nature of data and the simplified 2-dimensional matrices commonly used in linear algebra-based machine learning algorithms. This paper explores the steps involved in tensorization, multidimensional data sources, various multiway analysis methods employed, and the benefits of these approaches. A small example of Blind Source Separation (BSS) is presented comparing 2-dimensional algorithms and a multiway algorithm in Python. Results indicate that multiway analysis is more expressive. Contrary to the intuition of the dimensionality curse, utilising multidimensional datasets in their native form and applying multiway analysis methods grounded in multilinear algebra reveal a profound capacity to capture intricate interrelationships among various dimensions while, surprisingly, reducing the number of model parameters and accelerating processing. A survey of the multi-away analysis methods and integration with various Deep Neural Networks models is presented using case studies in different domains.