 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Model Purified Semi-Supervised Semantic Segmentation for Remote Sensing Images
Jan 30, 2026The semi-supervised semantic segmentation (S4) can learn rich visual knowledge from low-cost unlabeled images. However, traditional S4 architectures all face the challenge of low-quality pseudo-labels, especially for the teacher-student framework.We propose a novel SemiEarth model that introduces vision-language models (VLMs) to address the S4 issues for the remote sensing (RS) domain. Specifically, we invent a VLM pseudo-label purifying (VLM-PP) structure to purify the teacher network's pseudo-labels, achieving substantial improvements. Especially in multi-class boundary regions of RS images, the VLM-PP module can significantly improve the quality of pseudo-labels generated by the teacher, thereby correctly guiding the student model's learning. Moreover, since VLM-PP equips VLMs with open-world capabilities and is independent of the S4 architecture, it can correct mispredicted categories in low-confidence pseudo-labels whenever a discrepancy arises between its prediction and the pseudo-label. We conducted extensive experiments on multiple RS datasets, which demonstrate that our SemiEarth achieves SOTA performance. More importantly, unlike previous SOTA RS S4 methods, our model not only achieves excellent performance but also offers good interpretability. The code is released at https://github.com/wangshanwen001/SemiEarth.
A probabilistic foundation model for crystal structure denoising, phase classification, and order parameters
Dec 21, 2025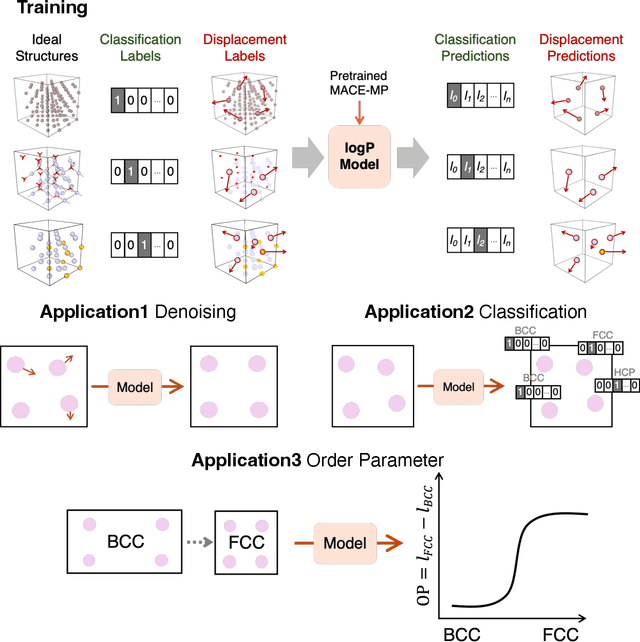
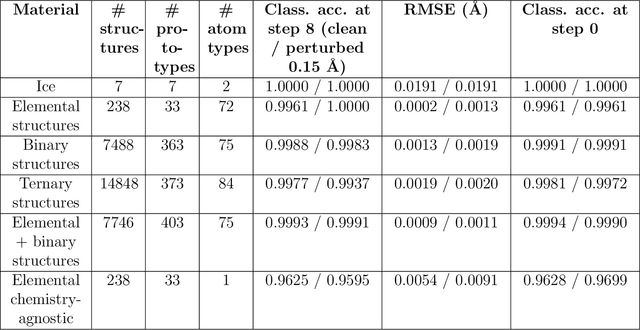
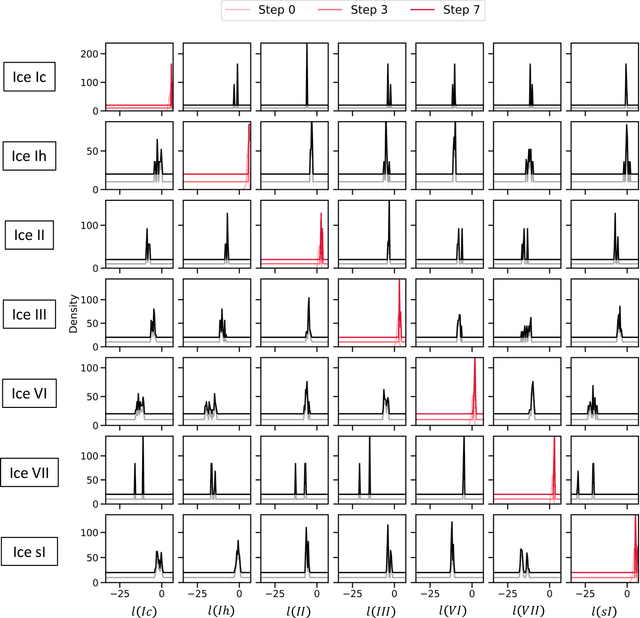
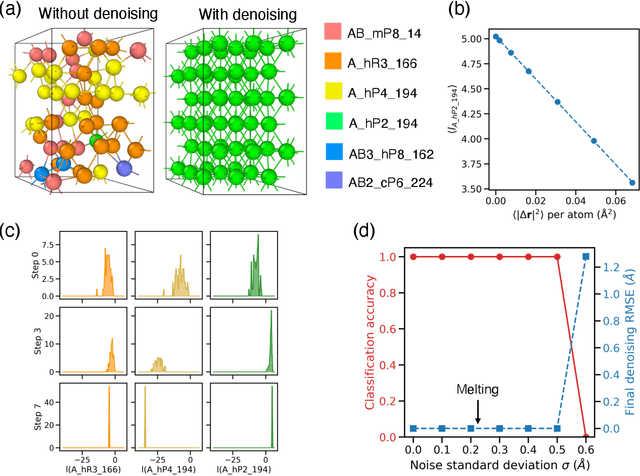
Atomistic simulations generate large volumes of noisy structural data, but extracting phase labels, order parameters (OPs), and defect information in a way that is universal, robust, and interpretable remains challenging. Existing tools such as PTM and CNA are restricted to a small set of hand-crafted lattices (e.g.\ FCC/BCC/HCP), degrade under strong thermal disorder or defects, and produce hard, template-based labels without per-atom probability or confidence scores. Here we introduce a log-probability foundation model that unifies denoising, phase classification, and OP extraction within a single probabilistic framework. We reuse the MACE-MP foundation interatomic potential on crystal structures mapped to AFLOW prototypes, training it to predict per-atom, per-phase logits $l$ and to aggregate them into a global log-density $\log \hat{P}_θ(\boldsymbol{r})$ whose gradient defines a conservative score field. Denoising corresponds to gradient ascent on this learned log-density, phase labels follow from $\arg\max_c l_{ac}$, and the $l$ values act as continuous, defect-sensitive and interpretable OPs quantifying the Euclidean distance to ideal phases. We demonstrate universality across hundreds of prototypes, robustness under strong thermal and defect-induced disorder, and accurate treatment of complex systems such as ice polymorphs, ice--water interfaces, and shock-compressed Ti.
Transformer-Based Dual-Optical Attention Fusion Crowd Head Point Counting and Localization Network
May 11, 2025In this paper, the dual-optical attention fusion crowd head point counting model (TAPNet) is proposed to address the problem of the difficulty of accurate counting in complex scenes such as crowd dense occlusion and low light in crowd counting tasks under UAV view. The model designs a dual-optical attention fusion module (DAFP) by introducing complementary information from infrared images to improve the accuracy and robustness of all-day crowd counting. In order to fully utilize different modal information and solve the problem of inaccurate localization caused by systematic misalignment between image pairs, this paper also proposes an adaptive two-optical feature decomposition fusion module (AFDF). In addition, we optimize the training strategy to improve the model robustness through spatial random offset data augmentation. Experiments on two challenging public datasets, DroneRGBT and GAIIC2, show that the proposed method outperforms existing techniques in terms of performance, especially in challenging dense low-light scenes. Code is available at https://github.com/zz-zik/TAPNet
Towards Smart Point-and-Shoot Photography
May 06, 2025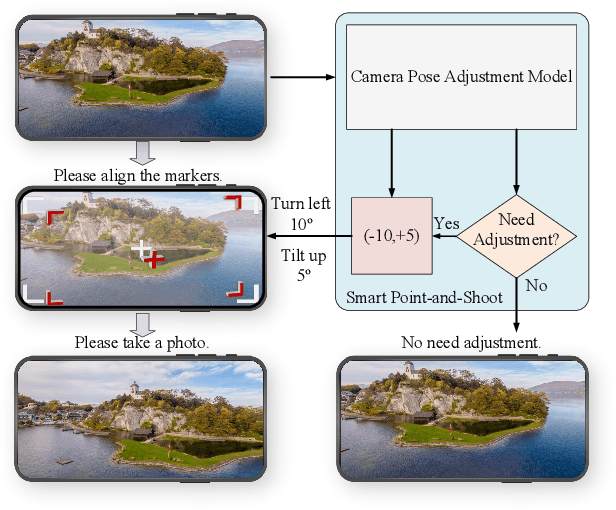



Hundreds of millions of people routinely take photos using their smartphones as point and shoot (PAS) cameras, yet very few would have the photography skills to compose a good shot of a scene. While traditional PAS cameras have built-in functions to ensure a photo is well focused and has the right brightness, they cannot tell the users how to compose the best shot of a scene. In this paper, we present a first of its kind smart point and shoot (SPAS) system to help users to take good photos. Our SPAS proposes to help users to compose a good shot of a scene by automatically guiding the users to adjust the camera pose live on the scene. We first constructed a large dataset containing 320K images with camera pose information from 4000 scenes. We then developed an innovative CLIP-based Composition Quality Assessment (CCQA) model to assign pseudo labels to these images. The CCQA introduces a unique learnable text embedding technique to learn continuous word embeddings capable of discerning subtle visual quality differences in the range covered by five levels of quality description words {bad, poor, fair, good, perfect}. And finally we have developed a camera pose adjustment model (CPAM) which first determines if the current view can be further improved and if so it outputs the adjust suggestion in the form of two camera pose adjustment angles. The two tasks of CPAM make decisions in a sequential manner and each involves different sets of training samples, we have developed a mixture-of-experts model with a gated loss function to train the CPAM in an end-to-end manner. We will present extensive results to demonstrate the performances of our SPAS system using publicly available image composition datasets.
Rethinking the Upsampling Layer in Hyperspectral Image Super Resolution
Jan 30, 2025



Deep learning has achieved significant success in single hyperspectral image super-resolution (SHSR); however, the high spectral dimensionality leads to a heavy computational burden, thus making it difficult to deploy in real-time scenarios. To address this issue, this paper proposes a novel lightweight SHSR network, i.e., LKCA-Net, that incorporates channel attention to calibrate multi-scale channel features of hyperspectral images. Furthermore, we demonstrate, for the first time, that the low-rank property of the learnable upsampling layer is a key bottleneck in lightweight SHSR methods. To address this, we employ the low-rank approximation strategy to optimize the parameter redundancy of the learnable upsampling layer. Additionally, we introduce a knowledge distillation-based feature alignment technique to ensure the low-rank approximated network retains the same feature representation capacity as the original. We conducted extensive experiments on the Chikusei, Houston 2018, and Pavia Center datasets compared to some SOTAs. The results demonstrate that our method is competitive in performance while achieving speedups of several dozen to even hundreds of times compared to other well-performing SHSR methods.
ADV2E: Bridging the Gap Between Analogue Circuit and Discrete Frames in the Video-to-Events Simulator
Nov 19, 2024



Event cameras operate fundamentally differently from traditional Active Pixel Sensor (APS) cameras, offering significant advantages. Recent research has developed simulators to convert video frames into events, addressing the shortage of real event datasets. Current simulators primarily focus on the logical behavior of event cameras. However, the fundamental analogue properties of pixel circuits are seldom considered in simulator design. The gap between analogue pixel circuit and discrete video frames causes the degeneration of synthetic events, particularly in high-contrast scenes. In this paper, we propose a novel method of generating reliable event data based on a detailed analysis of the pixel circuitry in event cameras. We incorporate the analogue properties of event camera pixel circuits into the simulator design: (1) analogue filtering of signals from light intensity to events, and (2) a cutoff frequency that is independent of video frame rate. Experimental results on two relevant tasks, including semantic segmentation and image reconstruction, validate the reliability of simulated event data, even in high-contrast scenes. This demonstrates that deep neural networks exhibit strong generalization from simulated to real event data, confirming that the synthetic events generated by the proposed method are both realistic and well-suited for effective training.
Meta-Exploiting Frequency Prior for Cross-Domain Few-Shot Learning
Nov 03, 2024



Meta-learning offers a promising avenue for few-shot learning (FSL), enabling models to glean a generalizable feature embedding through episodic training on synthetic FSL tasks in a source domain. Yet, in practical scenarios where the target task diverges from that in the source domain, meta-learning based method is susceptible to over-fitting. To overcome this, we introduce a novel framework, Meta-Exploiting Frequency Prior for Cross-Domain Few-Shot Learning, which is crafted to comprehensively exploit the cross-domain transferable image prior that each image can be decomposed into complementary low-frequency content details and high-frequency robust structural characteristics. Motivated by this insight, we propose to decompose each query image into its high-frequency and low-frequency components, and parallel incorporate them into the feature embedding network to enhance the final category prediction. More importantly, we introduce a feature reconstruction prior and a prediction consistency prior to separately encourage the consistency of the intermediate feature as well as the final category prediction between the original query image and its decomposed frequency components. This allows for collectively guiding the network's meta-learning process with the aim of learning generalizable image feature embeddings, while not introducing any extra computational cost in the inference phase. Our framework establishes new state-of-the-art results on multiple cross-domain few-shot learning benchmarks.
Grand canonical generative diffusion model for crystalline phases and grain boundaries
Aug 28, 2024The diffusion model has emerged as a powerful tool for generating atomic structures for materials science. This work calls attention to the deficiency of current particle-based diffusion models, which represent atoms as a point cloud, in generating even the simplest ordered crystalline structures. The problem is attributed to particles being trapped in local minima during the score-driven simulated annealing of the diffusion process, similar to the physical process of force-driven simulated annealing. We develop a solution, the grand canonical diffusion model, which adopts an alternative voxel-based representation with continuous rather than fixed number of particles. The method is applied towards generation of several common crystalline phases as well as the technologically important and challenging problem of grain boundary structures.
Sparse Prior Is Not All You Need: When Differential Directionality Meets Saliency Coherence for Infrared Small Target Detection
Jul 22, 2024Infrared small target detection is crucial for the efficacy of infrared search and tracking systems. Current tensor decomposition methods emphasize representing small targets with sparsity but struggle to separate targets from complex backgrounds due to insufficient use of intrinsic directional information and reduced target visibility during decomposition. To address these challenges, this study introduces a Sparse Differential Directionality prior (SDD) framework. SDD leverages the distinct directional characteristics of targets to differentiate them from the background, applying mixed sparse constraints on the differential directional images and continuity difference matrix of the temporal component, both derived from Tucker decomposition. We further enhance target detectability with a saliency coherence strategy that intensifies target contrast against the background during hierarchical decomposition. A Proximal Alternating Minimization-based (PAM) algorithm efficiently solves our proposed model. Experimental results on several real-world datasets validate our method's effectiveness, outperforming ten state-of-the-art methods in target detection and clutter suppression. Our code is available at https://github.com/GrokCV/SDD.
Geometric Distortion Guided Transformer for Omnidirectional Image Super-Resolution
Jun 16, 2024



As virtual and augmented reality applications gain popularity, omnidirectional image (ODI) super-resolution has become increasingly important. Unlike 2D plain images that are formed on a plane, ODIs are projected onto spherical surfaces. Applying established image super-resolution methods to ODIs, therefore, requires performing equirectangular projection (ERP) to map the ODIs onto a plane. ODI super-resolution needs to take into account geometric distortion resulting from ERP. However, without considering such geometric distortion of ERP images, previous deep-learning-based methods only utilize a limited range of pixels and may easily miss self-similar textures for reconstruction. In this paper, we introduce a novel Geometric Distortion Guided Transformer for Omnidirectional image Super-Resolution (GDGT-OSR). Specifically, a distortion modulated rectangle-window self-attention mechanism, integrated with deformable self-attention, is proposed to better perceive the distortion and thus involve more self-similar textures. Distortion modulation is achieved through a newly devised distortion guidance generator that produces guidance by exploiting the variability of distortion across latitudes. Furthermore, we propose a dynamic feature aggregation scheme to adaptively fuse the features from different self-attention modules. We present extensive experimental results on public datasets and show that the new GDGT-OSR outperforms methods in existing literature.