 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-level distortion-aware deformable network for omnidirectional image super-resolution
Dec 19, 2025As augmented reality and virtual reality applications gain popularity, image processing for OmniDirectional Images (ODIs) has attracted increasing attention. OmniDirectional Image Super-Resolution (ODISR) is a promising technique for enhancing the visual quality of ODIs. Before performing super-resolution, ODIs are typically projected from a spherical surface onto a plane using EquiRectangular Projection (ERP). This projection introduces latitude-dependent geometric distortion in ERP images: distortion is minimal near the equator but becomes severe toward the poles, where image content is stretched across a wider area. However, existing ODISR methods have limited sampling ranges and feature extraction capabilities, which hinder their ability to capture distorted patterns over large areas. To address this issue, we propose a novel Multi-level Distortion-aware Deformable Network (MDDN) for ODISR, designed to expand the sampling range and receptive field. Specifically, the feature extractor in MDDN comprises three parallel branches: a deformable attention mechanism (serving as the dilation=1 path) and two dilated deformable convolutions with dilation rates of 2 and 3. This architecture expands the sampling range to include more distorted patterns across wider areas, generating dense and comprehensive features that effectively capture geometric distortions in ERP images. The representations extracted from these deformable feature extractors are adaptively fused in a multi-level feature fusion module. Furthermore, to reduce computational cost, a low-rank decomposition strategy is applied to dilated deformable convolutions. Extensive experiments on publicly available datasets demonstrate that MDDN outperforms state-of-the-art methods, underscoring its effectiveness and superiority in ODISR.
Towards Smart Point-and-Shoot Photography
May 06, 2025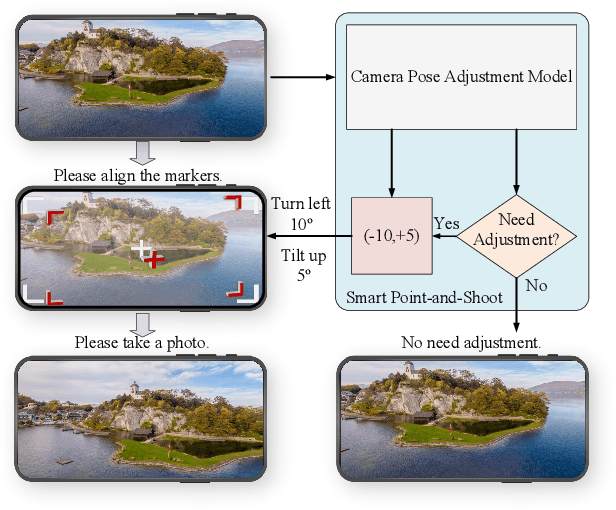



Hundreds of millions of people routinely take photos using their smartphones as point and shoot (PAS) cameras, yet very few would have the photography skills to compose a good shot of a scene. While traditional PAS cameras have built-in functions to ensure a photo is well focused and has the right brightness, they cannot tell the users how to compose the best shot of a scene. In this paper, we present a first of its kind smart point and shoot (SPAS) system to help users to take good photos. Our SPAS proposes to help users to compose a good shot of a scene by automatically guiding the users to adjust the camera pose live on the scene. We first constructed a large dataset containing 320K images with camera pose information from 4000 scenes. We then developed an innovative CLIP-based Composition Quality Assessment (CCQA) model to assign pseudo labels to these images. The CCQA introduces a unique learnable text embedding technique to learn continuous word embeddings capable of discerning subtle visual quality differences in the range covered by five levels of quality description words {bad, poor, fair, good, perfect}. And finally we have developed a camera pose adjustment model (CPAM) which first determines if the current view can be further improved and if so it outputs the adjust suggestion in the form of two camera pose adjustment angles. The two tasks of CPAM make decisions in a sequential manner and each involves different sets of training samples, we have developed a mixture-of-experts model with a gated loss function to train the CPAM in an end-to-end manner. We will present extensive results to demonstrate the performances of our SPAS system using publicly available image composition datasets.
MO-CTranS: A unified multi-organ segmentation model learning from multiple heterogeneously labelled datasets
Mar 28, 2025


Multi-organ segmentation holds paramount significance in many clinical tasks. In practice, compared to large fully annotated datasets, multiple small datasets are often more accessible and organs are not labelled consistently. Normally, an individual model is trained for each of these datasets, which is not an effective way of using data for model learning. It remains challenging to train a single model that can robustly learn from several partially labelled datasets due to label conflict and data imbalance problems. We propose MO-CTranS: a single model that can overcome such problems. MO-CTranS contains a CNN-based encoder and a Transformer-based decoder, which are connected in a multi-resolution manner. Task-specific tokens are introduced in the decoder to help differentiate label discrepancies. Our method was evaluated and compared to several baseline models and state-of-the-art (SOTA) solutions on abdominal MRI datasets that were acquired in different views (i.e. axial and coronal) and annotated for different organs (i.e. liver, kidney, spleen). Our method achieved better performance (most were statistically significant) than the compared methods. Github link: https://github.com/naisops/MO-CTranS.
HySurvPred: Multimodal Hyperbolic Embedding with Angle-Aware Hierarchical Contrastive Learning and Uncertainty Constraints for Survival Prediction
Mar 18, 2025Multimodal learning that integrates histopathology images and genomic data holds great promise for cancer survival prediction. However, existing methods face key limitations: 1) They rely on multimodal mapping and metrics in Euclidean space, which cannot fully capture the hierarchical structures in histopathology (among patches from different resolutions) and genomics data (from genes to pathways). 2) They discretize survival time into independent risk intervals, which ignores its continuous and ordinal nature and fails to achieve effective optimization. 3) They treat censorship as a binary indicator, excluding censored samples from model optimization and not making full use of them. To address these challenges, we propose HySurvPred, a novel framework for survival prediction that integrates three key modules: Multimodal Hyperbolic Mapping (MHM), Angle-aware Ranking-based Contrastive Loss (ARCL) and Censor-Conditioned Uncertainty Constraint (CUC). Instead of relying on Euclidean space, we design the MHM module to explore the inherent hierarchical structures within each modality in hyperbolic space. To better integrate multimodal features in hyperbolic space, we introduce the ARCL module, which uses ranking-based contrastive learning to preserve the ordinal nature of survival time, along with the CUC module to fully explore the censored data. Extensive experiments demonstrate that our method outperforms state-of-the-art methods on five benchmark datasets. The source code is to be released.
SPC-GS: Gaussian Splatting with Semantic-Prompt Consistency for Indoor Open-World Free-view Synthesis from Sparse Inputs
Mar 16, 20253D Gaussian Splatting-based indoor open-world free-view synthesis approaches have shown significant performance with dense input images. However, they exhibit poor performance when confronted with sparse inputs, primarily due to the sparse distribution of Gaussian points and insufficient view supervision. To relieve these challenges, we propose SPC-GS, leveraging Scene-layout-based Gaussian Initialization (SGI) and Semantic-Prompt Consistency (SPC) Regularization for open-world free view synthesis with sparse inputs. Specifically, SGI provides a dense, scene-layout-based Gaussian distribution by utilizing view-changed images generated from the video generation model and view-constraint Gaussian points densification. Additionally, SPC mitigates limited view supervision by employing semantic-prompt-based consistency constraints developed by SAM2. This approach leverages available semantics from training views, serving as instructive prompts, to optimize visually overlapping regions in novel views with 2D and 3D consistency constraints. Extensive experiments demonstrate the superior performance of SPC-GS across Replica and ScanNet benchmarks. Notably, our SPC-GS achieves a 3.06 dB gain in PSNR for reconstruction quality and a 7.3% improvement in mIoU for open-world semantic segmentation.
CFFormer: Cross CNN-Transformer Channel Attention and Spatial Feature Fusion for Improved Segmentation of Low Quality Medical Images
Jan 07, 2025Hybrid CNN-Transformer models are designed to combine the advantages of Convolutional Neural Networks (CNNs) and Transformers to efficiently model both local information and long-range dependencies. However, most research tends to focus on integrating the spatial features of CNNs and Transformers, while overlooking the critical importance of channel features. This is particularly significant for model performance in low-quality medical image segmentation. Effective channel feature extraction can significantly enhance the model's ability to capture contextual information and improve its representation capabilities. To address this issue, we propose a hybrid CNN-Transformer model, CFFormer, and introduce two modules: the Cross Feature Channel Attention (CFCA) module and the X-Spatial Feature Fusion (XFF) module. The model incorporates dual encoders, with the CNN encoder focusing on capturing local features and the Transformer encoder modeling global features. The CFCA module filters and facilitates interactions between the channel features from the two encoders, while the XFF module effectively reduces the significant semantic information differences in spatial features, enabling a smooth and cohesive spatial feature fusion. We evaluate our model across eight datasets covering five modalities to test its generalization capability. Experimental results demonstrate that our model outperforms current state-of-the-art (SOTA) methods, with particularly superior performance on datasets characterized by blurry boundaries and low contrast.
TAVP: Task-Adaptive Visual Prompt for Cross-domain Few-shot Segmentation
Sep 09, 2024



Under the backdrop of large-scale pre-training, large visual models (LVM) have demonstrated significant potential in image understanding. The recent emergence of the Segment Anything Model (SAM) has brought a qualitative shift in the field of image segmentation, supporting flexible interactive cues and strong learning capabilities. However, its performance often falls short in cross-domain and few-shot applications. Transferring prior knowledge from foundation models to new applications while preserving learning capabilities is worth exploring. This work proposes a task-adaptive prompt framework based on SAM, a new paradigm for Cross-dominan few-shot segmentation (CD-FSS). First, a Multi-level Feature Fusion (MFF) was used for integrated feature extraction. Besides, an additional Class Domain Task-Adaptive Auto-Prompt (CDTAP) module was combined with the segmentation branch for class-domain agnostic feature extraction and high-quality learnable prompt production. This significant advancement uses a unique generative approach to prompts alongside a comprehensive model structure and specialized prototype computation. While ensuring that the prior knowledge of SAM is not discarded, the new branch disentangles category and domain information through prototypes, guiding it in adapting the CD-FSS. We have achieved the best results on three benchmarks compared to the recent state-of-the-art (SOTA) methods. Comprehensive experiments showed that after task-specific and weighted guidance, the abundant feature information of SAM can be better learned for CD-FSS.
LoopSparseGS: Loop Based Sparse-View Friendly Gaussian Splatting
Aug 01, 2024



Despite the photorealistic novel view synthesis (NVS) performance achieved by the original 3D Gaussian splatting (3DGS), its rendering quality significantly degrades with sparse input views. This performance drop is mainly caused by the limited number of initial points generated from the sparse input, insufficient supervision during the training process, and inadequate regularization of the oversized Gaussian ellipsoids. To handle these issues, we propose the LoopSparseGS, a loop-based 3DGS framework for the sparse novel view synthesis task. In specific, we propose a loop-based Progressive Gaussian Initialization (PGI) strategy that could iteratively densify the initialized point cloud using the rendered pseudo images during the training process. Then, the sparse and reliable depth from the Structure from Motion, and the window-based dense monocular depth are leveraged to provide precise geometric supervision via the proposed Depth-alignment Regularization (DAR). Additionally, we introduce a novel Sparse-friendly Sampling (SFS) strategy to handle oversized Gaussian ellipsoids leading to large pixel errors. Comprehensive experiments on four datasets demonstrate that LoopSparseGS outperforms existing state-of-the-art methods for sparse-input novel view synthesis, across indoor, outdoor, and object-level scenes with various image resolutions.
Geometric Distortion Guided Transformer for Omnidirectional Image Super-Resolution
Jun 16, 2024



As virtual and augmented reality applications gain popularity, omnidirectional image (ODI) super-resolution has become increasingly important. Unlike 2D plain images that are formed on a plane, ODIs are projected onto spherical surfaces. Applying established image super-resolution methods to ODIs, therefore, requires performing equirectangular projection (ERP) to map the ODIs onto a plane. ODI super-resolution needs to take into account geometric distortion resulting from ERP. However, without considering such geometric distortion of ERP images, previous deep-learning-based methods only utilize a limited range of pixels and may easily miss self-similar textures for reconstruction. In this paper, we introduce a novel Geometric Distortion Guided Transformer for Omnidirectional image Super-Resolution (GDGT-OSR). Specifically, a distortion modulated rectangle-window self-attention mechanism, integrated with deformable self-attention, is proposed to better perceive the distortion and thus involve more self-similar textures. Distortion modulation is achieved through a newly devised distortion guidance generator that produces guidance by exploiting the variability of distortion across latitudes. Furthermore, we propose a dynamic feature aggregation scheme to adaptively fuse the features from different self-attention modules. We present extensive experimental results on public datasets and show that the new GDGT-OSR outperforms methods in existing literature.
Vision Language Modeling of Content, Distortion and Appearance for Image Quality Assessment
Jun 14, 2024The visual quality of an image is confounded by a number of intertwined factors including its semantic content, distortion characteristics and appearance properties such as brightness, contrast, sharpness, and colourfulness. Distilling high level knowledge about all these quality bearing attributes is crucial for developing objective Image Quality Assessment (IQA).While existing solutions have modeled some of these aspects, a comprehensive solution that involves all these important quality related attributes has not yet been developed. In this paper, we present a new blind IQA (BIQA) model termed Self-supervision and Vision-Language supervision Image QUality Evaluator (SLIQUE) that features a joint vision-language and visual contrastive representation learning framework for acquiring high level knowledge about the images semantic contents, distortion characteristics and appearance properties for IQA. For training SLIQUE, we have developed a systematic approach to constructing a first of its kind large image database annotated with all three categories of quality relevant texts. The Text Annotated Distortion, Appearance and Content (TADAC) database has over 1.6 million images annotated with textual descriptions of their semantic contents, distortion characteristics and appearance properties. The method for constructing TADAC and the database itself will be particularly useful for exploiting vision-language modeling for advanced IQA applications. Extensive experimental results show that SLIQUE has superior performances over state of the art, demonstrating the soundness of its design principle and the effectiveness of its implementation.