 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity-Guided Multi-Task Learning for Infrared and Visible Image Fusion
Jan 05, 2026Existing text-driven infrared and visible image fusion approaches often rely on textual information at the sentence level, which can lead to semantic noise from redundant text and fail to fully exploit the deeper semantic value of textual information. To address these issues, we propose a novel fusion approach named Entity-Guided Multi-Task learning for infrared and visible image fusion (EGMT). Our approach includes three key innovative components: (i) A principled method is proposed to extract entity-level textual information from image captions generated by large vision-language models, eliminating semantic noise from raw text while preserving critical semantic information; (ii) A parallel multi-task learning architecture is constructed, which integrates image fusion with a multi-label classification task. By using entities as pseudo-labels, the multi-label classification task provides semantic supervision, enabling the model to achieve a deeper understanding of image content and significantly improving the quality and semantic density of the fused image; (iii) An entity-guided cross-modal interactive module is also developed to facilitate the fine-grained interaction between visual and entity-level textual features, which enhances feature representation by capturing cross-modal dependencies at both inter-visual and visual-entity levels. To promote the wide application of the entity-guided image fusion framework, we release the entity-annotated version of four public datasets (i.e., TNO, RoadScene, M3FD, and MSRS). Extensive experiments demonstrate that EGMT achieves superior performance in preserving salient targets, texture details, and semantic consistency, compared to the state-of-the-art methods. The code and dataset will be publicly available at https://github.com/wyshao-01/EGMT.
CFFormer: Cross CNN-Transformer Channel Attention and Spatial Feature Fusion for Improved Segmentation of Low Quality Medical Images
Jan 07, 2025Hybrid CNN-Transformer models are designed to combine the advantages of Convolutional Neural Networks (CNNs) and Transformers to efficiently model both local information and long-range dependencies. However, most research tends to focus on integrating the spatial features of CNNs and Transformers, while overlooking the critical importance of channel features. This is particularly significant for model performance in low-quality medical image segmentation. Effective channel feature extraction can significantly enhance the model's ability to capture contextual information and improve its representation capabilities. To address this issue, we propose a hybrid CNN-Transformer model, CFFormer, and introduce two modules: the Cross Feature Channel Attention (CFCA) module and the X-Spatial Feature Fusion (XFF) module. The model incorporates dual encoders, with the CNN encoder focusing on capturing local features and the Transformer encoder modeling global features. The CFCA module filters and facilitates interactions between the channel features from the two encoders, while the XFF module effectively reduces the significant semantic information differences in spatial features, enabling a smooth and cohesive spatial feature fusion. We evaluate our model across eight datasets covering five modalities to test its generalization capability. Experimental results demonstrate that our model outperforms current state-of-the-art (SOTA) methods, with particularly superior performance on datasets characterized by blurry boundaries and low contrast.
KUNPENG: An Embodied Large Model for Intelligent Maritime
Jul 12, 2024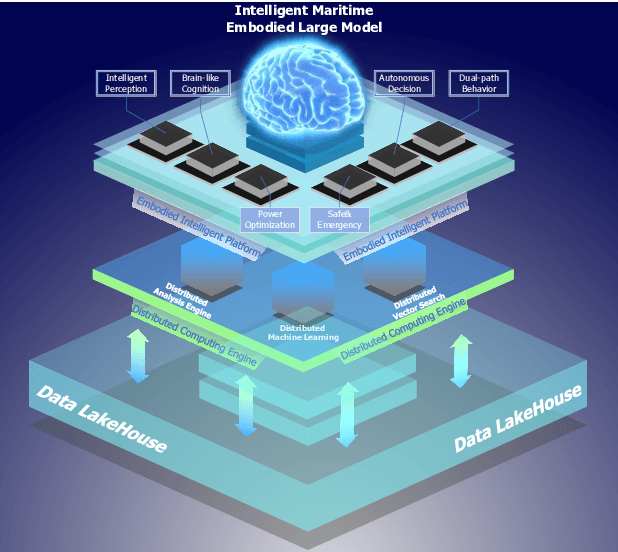
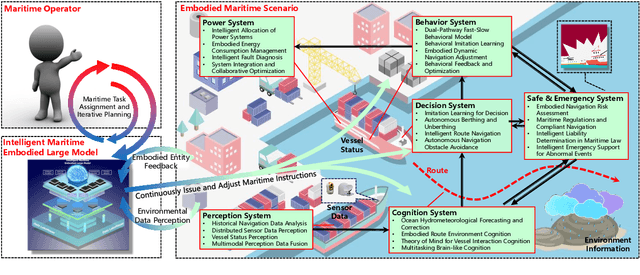
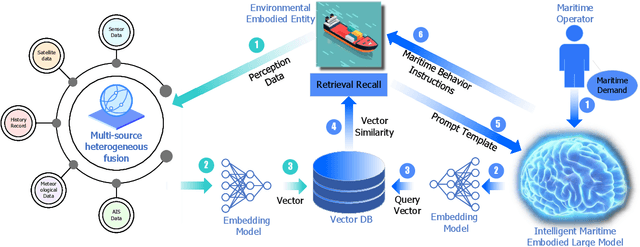
Intelligent maritime, as an essential component of smart ocean construction, deeply integrates advanced artificial intelligence technology and data analysis methods, which covers multiple aspects such as smart vessels, route optimization, safe navigation, aiming to enhance the efficiency of ocean resource utilization and the intelligence of transportation networks. However, the complex and dynamic maritime environment, along with diverse and heterogeneous large-scale data sources, present challenges for real-time decision-making in intelligent maritime. In this paper, We propose KUNPENG, the first-ever embodied large model for intelligent maritime in the smart ocean construction, which consists of six systems. The model perceives multi-source heterogeneous data for the cognition of environmental interaction and make autonomous decision strategies, which are used for intelligent vessels to perform navigation behaviors under safety and emergency guarantees and continuously optimize power to achieve embodied intelligence in maritime. In comprehensive maritime task evaluations, KUNPENG has demonstrated excellent performance.
CBPF: Filtering Poisoned Data Based on Composite Backdoor Attack
Jun 23, 2024



Backdoor attacks involve the injection of a limited quantity of poisoned examples containing triggers into the training dataset. During the inference stage, backdoor attacks can uphold a high level of accuracy for normal examples, yet when presented with trigger-containing instances, the model may erroneously predict them as the targeted class designated by the attacker. This paper explores strategies for mitigating the risks associated with backdoor attacks by examining the filtration of poisoned samples.We primarily leverage two key characteristics of backdoor attacks: the ability for multiple backdoors to exist simultaneously within a single model, and the discovery through Composite Backdoor Attack (CBA) that altering two triggers in a sample to new target labels does not compromise the original functionality of the triggers, yet enables the prediction of the data as a new target class when both triggers are present simultaneously.Therefore, a novel three-stage poisoning data filtering approach, known as Composite Backdoor Poison Filtering (CBPF), is proposed as an effective solution. Firstly, utilizing the identified distinctions in output between poisoned and clean samples, a subset of data is partitioned to include both poisoned and clean instances. Subsequently, benign triggers are incorporated and labels are adjusted to create new target and benign target classes, thereby prompting the poisoned and clean data to be classified as distinct entities during the inference stage. The experimental results indicate that CBPF is successful in filtering out malicious data produced by six advanced attacks on CIFAR10 and ImageNet-12. On average, CBPF attains a notable filtering success rate of 99.91% for the six attacks on CIFAR10. Additionally, the model trained on the uncontaminated samples exhibits sustained high accuracy levels.
PhasePerturbation: Speech Data Augmentation via Phase Perturbation for Automatic Speech Recognition
Dec 13, 2023Most of the current speech data augmentation methods operate on either the raw waveform or the amplitude spectrum of speech. In this paper, we propose a novel speech data augmentation method called PhasePerturbation that operates dynamically on the phase spectrum of speech. Instead of statically rotating a phase by a constant degree, PhasePerturbation utilizes three dynamic phase spectrum operations, i.e., a randomization operation, a frequency masking operation, and a temporal masking operation, to enhance the diversity of speech data. We conduct experiments on wav2vec2.0 pre-trained ASR models by fine-tuning them with the PhasePerturbation augmented TIMIT corpus. The experimental results demonstrate 10.9\% relative reduction in the word error rate (WER) compared with the baseline model fine-tuned without any augmentation operation. Furthermore, the proposed method achieves additional improvements (12.9\% and 15.9\%) in WER by complementing the Vocal Tract Length Perturbation (VTLP) and the SpecAug, which are both amplitude spectrum-based augmentation methods. The results highlight the capability of PhasePerturbation to improve the current amplitude spectrum-based augmentation methods.
Survey on deep learning in multimodal medical imaging for cancer detection
Dec 04, 2023The task of multimodal cancer detection is to determine the locations and categories of lesions by using different imaging techniques, which is one of the key research methods for cancer diagnosis. Recently, deep learning-based object detection has made significant developments due to its strength in semantic feature extraction and nonlinear function fitting. However, multimodal cancer detection remains challenging due to morphological differences in lesions, interpatient variability, difficulty in annotation, and imaging artifacts. In this survey, we mainly investigate over 150 papers in recent years with respect to multimodal cancer detection using deep learning, with a focus on datasets and solutions to various challenges such as data annotation, variance between classes, small-scale lesions, and occlusion. We also provide an overview of the advantages and drawbacks of each approach. Finally, we discuss the current scope of work and provide directions for the future development of multimodal cancer detection.
Video Infringement Detection via Feature Disentanglement and Mutual Information Maximization
Sep 13, 2023



The self-media era provides us tremendous high quality videos. Unfortunately, frequent video copyright infringements are now seriously damaging the interests and enthusiasm of video creators. Identifying infringing videos is therefore a compelling task. Current state-of-the-art methods tend to simply feed high-dimensional mixed video features into deep neural networks and count on the networks to extract useful representations. Despite its simplicity, this paradigm heavily relies on the original entangled features and lacks constraints guaranteeing that useful task-relevant semantics are extracted from the features. In this paper, we seek to tackle the above challenges from two aspects: (1) We propose to disentangle an original high-dimensional feature into multiple sub-features, explicitly disentangling the feature into exclusive lower-dimensional components. We expect the sub-features to encode non-overlapping semantics of the original feature and remove redundant information. (2) On top of the disentangled sub-features, we further learn an auxiliary feature to enhance the sub-features. We theoretically analyzed the mutual information between the label and the disentangled features, arriving at a loss that maximizes the extraction of task-relevant information from the original feature. Extensive experiments on two large-scale benchmark datasets (i.e., SVD and VCSL) demonstrate that our method achieves 90.1% TOP-100 mAP on the large-scale SVD dataset and also sets the new state-of-the-art on the VCSL benchmark dataset. Our code and model have been released at https://github.com/yyyooooo/DMI/, hoping to contribute to the community.
Multi-stage Factorized Spatio-Temporal Representation for RGB-D Action and Gesture Recognition
Sep 11, 2023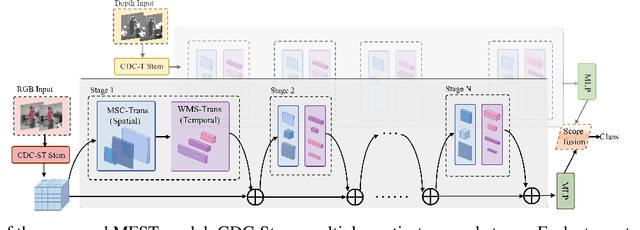
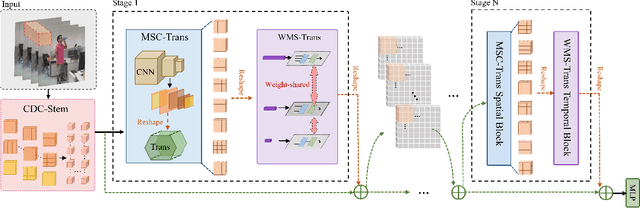
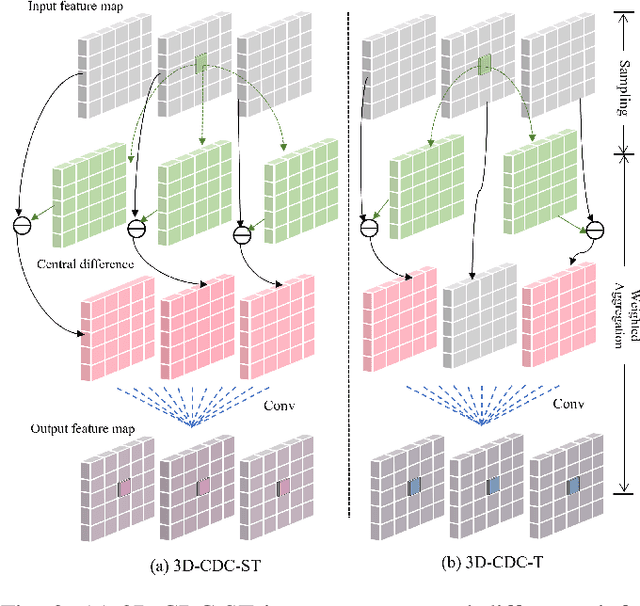
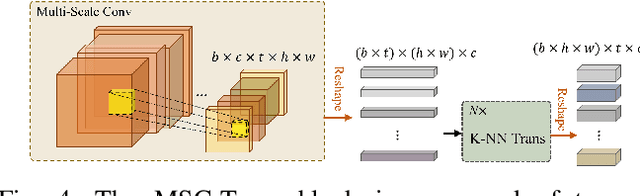
RGB-D action and gesture recognition remain an interesting topic in human-centered scene understanding, primarily due to the multiple granularities and large variation in human motion. Although many RGB-D based action and gesture recognition approaches have demonstrated remarkable results by utilizing highly integrated spatio-temporal representations across multiple modalities (i.e., RGB and depth data), they still encounter several challenges. Firstly, vanilla 3D convolution makes it hard to capture fine-grained motion differences between local clips under different modalities. Secondly, the intricate nature of highly integrated spatio-temporal modeling can lead to optimization difficulties. Thirdly, duplicate and unnecessary information can add complexity and complicate entangled spatio-temporal modeling. To address the above issues, we propose an innovative heuristic architecture called Multi-stage Factorized Spatio-Temporal (MFST) for RGB-D action and gesture recognition. The proposed MFST model comprises a 3D Central Difference Convolution Stem (CDC-Stem) module and multiple factorized spatio-temporal stages. The CDC-Stem enriches fine-grained temporal perception, and the multiple hierarchical spatio-temporal stages construct dimension-independent higher-order semantic primitives. Specifically, the CDC-Stem module captures bottom-level spatio-temporal features and passes them successively to the following spatio-temporal factored stages to capture the hierarchical spatial and temporal features through the Multi- Scale Convolution and Transformer (MSC-Trans) hybrid block and Weight-shared Multi-Scale Transformer (WMS-Trans) block. The seamless integration of these innovative designs results in a robust spatio-temporal representation that outperforms state-of-the-art approaches on RGB-D action and gesture recognition datasets.
A Novel Self-training Approach for Low-resource Speech Recognition
Aug 10, 2023In this paper, we propose a self-training approach for automatic speech recognition (ASR) for low-resource settings. While self-training approaches have been extensively developed and evaluated for high-resource languages such as English, their applications to low-resource languages like Punjabi have been limited, despite the language being spoken by millions globally. The scarcity of annotated data has hindered the development of accurate ASR systems, especially for low-resource languages (e.g., Punjabi and M\=aori languages). To address this issue, we propose an effective self-training approach that generates highly accurate pseudo-labels for unlabeled low-resource speech. Our experimental analysis demonstrates that our approach significantly improves word error rate, achieving a relative improvement of 14.94% compared to a baseline model across four real speech datasets. Further, our proposed approach reports the best results on the Common Voice Punjabi dataset.
How to Design Translation Prompts for ChatGPT: An Empirical Study
Apr 21, 2023The recently released ChatGPT has demonstrated surprising abilities in natural language understanding and natural language generation. Machine translation relies heavily on the abilities of language understanding and generation. Thus, in this paper, we explore how to assist machine translation with ChatGPT. We adopt several translation prompts on a wide range of translations. Our experimental results show that ChatGPT with designed translation prompts can achieve comparable or better performance over commercial translation systems for high-resource language translations. We further evaluate the translation quality using multiple references, and ChatGPT achieves superior performance compared to commercial systems. We also conduct experiments on domain-specific translations, the final results show that ChatGPT is able to comprehend the provided domain keyword and adjust accordingly to output proper translations. At last, we perform few-shot prompts that show consistent improvement across different base prompts. Our work provides empirical evidence that ChatGPT still has great potential in translations.