 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey on deep learning in multimodal medical imaging for cancer detection
Dec 04, 2023The task of multimodal cancer detection is to determine the locations and categories of lesions by using different imaging techniques, which is one of the key research methods for cancer diagnosis. Recently, deep learning-based object detection has made significant developments due to its strength in semantic feature extraction and nonlinear function fitting. However, multimodal cancer detection remains challenging due to morphological differences in lesions, interpatient variability, difficulty in annotation, and imaging artifacts. In this survey, we mainly investigate over 150 papers in recent years with respect to multimodal cancer detection using deep learning, with a focus on datasets and solutions to various challenges such as data annotation, variance between classes, small-scale lesions, and occlusion. We also provide an overview of the advantages and drawbacks of each approach. Finally, we discuss the current scope of work and provide directions for the future development of multimodal cancer detection.
Multi-stage Factorized Spatio-Temporal Representation for RGB-D Action and Gesture Recognition
Sep 11, 2023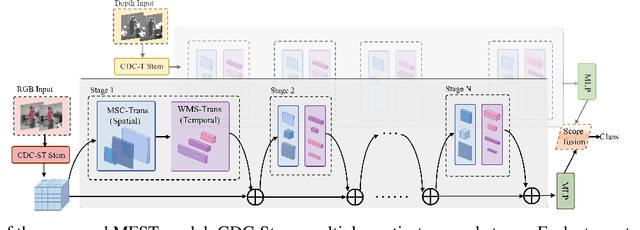
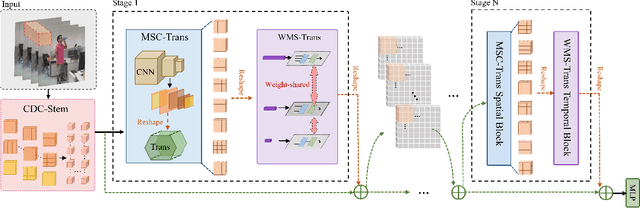
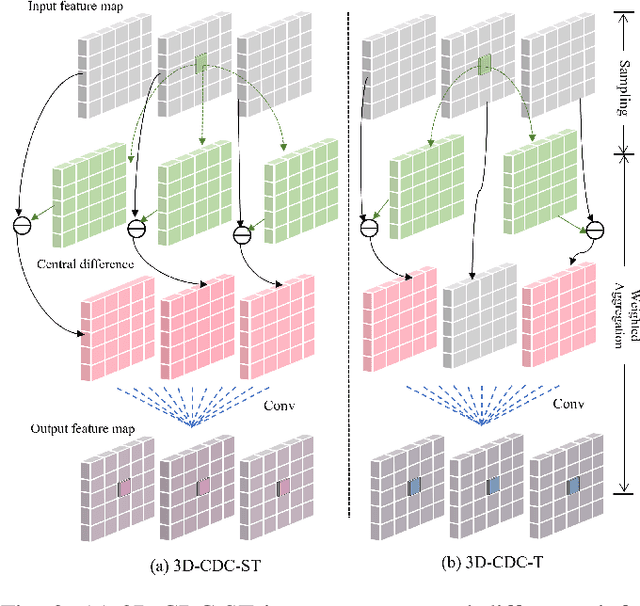
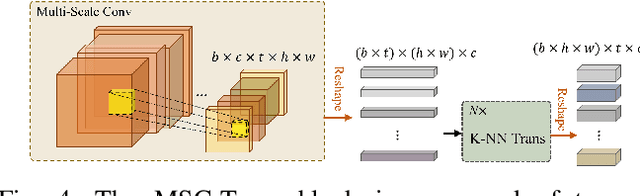
RGB-D action and gesture recognition remain an interesting topic in human-centered scene understanding, primarily due to the multiple granularities and large variation in human motion. Although many RGB-D based action and gesture recognition approaches have demonstrated remarkable results by utilizing highly integrated spatio-temporal representations across multiple modalities (i.e., RGB and depth data), they still encounter several challenges. Firstly, vanilla 3D convolution makes it hard to capture fine-grained motion differences between local clips under different modalities. Secondly, the intricate nature of highly integrated spatio-temporal modeling can lead to optimization difficulties. Thirdly, duplicate and unnecessary information can add complexity and complicate entangled spatio-temporal modeling. To address the above issues, we propose an innovative heuristic architecture called Multi-stage Factorized Spatio-Temporal (MFST) for RGB-D action and gesture recognition. The proposed MFST model comprises a 3D Central Difference Convolution Stem (CDC-Stem) module and multiple factorized spatio-temporal stages. The CDC-Stem enriches fine-grained temporal perception, and the multiple hierarchical spatio-temporal stages construct dimension-independent higher-order semantic primitives. Specifically, the CDC-Stem module captures bottom-level spatio-temporal features and passes them successively to the following spatio-temporal factored stages to capture the hierarchical spatial and temporal features through the Multi- Scale Convolution and Transformer (MSC-Trans) hybrid block and Weight-shared Multi-Scale Transformer (WMS-Trans) block. The seamless integration of these innovative designs results in a robust spatio-temporal representation that outperforms state-of-the-art approaches on RGB-D action and gesture recognition datasets.