 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveMathematicianBench: A Live Benchmark for Mathematician-Level Reasoning with Proof Sketches
Apr 02, 2026Mathematical reasoning is a hallmark of human intelligence, and whether large language models (LLMs) can meaningfully perform it remains a central question in artificial intelligence and cognitive science. As LLMs are increasingly integrated into scientific workflows, rigorous evaluation of their mathematical capabilities becomes a practical necessity. Existing benchmarks are limited by synthetic settings and data contamination. We present LiveMathematicianBench, a dynamic multiple-choice benchmark for research-level mathematical reasoning built from recent arXiv papers published after model training cutoffs. By grounding evaluation in newly published theorems, it provides a realistic testbed beyond memorized patterns. The benchmark introduces a thirteen-category logical taxonomy of theorem types (e.g., implication, equivalence, existence, uniqueness), enabling fine-grained evaluation across reasoning forms. It employs a proof-sketch-guided distractor pipeline that uses high-level proof strategies to construct plausible but invalid answer choices reflecting misleading proof directions, increasing sensitivity to genuine understanding over surface-level matching. We also introduce a substitution-resistant mechanism to distinguish answer recognition from substantive reasoning. Evaluation shows the benchmark is far from saturated: Gemini-3.1-pro-preview, the best model, achieves only 43.5%. Under substitution-resistant evaluation, accuracy drops sharply: GPT-5.4 scores highest at 30.6%, while Gemini-3.1-pro-preview falls to 17.6%, below the 20% random baseline. A dual-mode protocol reveals that proof-sketch access yields consistent accuracy gains, suggesting models can leverage high-level proof strategies for reasoning. Overall, LiveMathematicianBench offers a scalable, contamination-resistant testbed for studying research-level mathematical reasoning in LLMs.
SVGS: Single-View to 3D Object Editing via Gaussian Splatting
Mar 30, 2026Text-driven 3D scene editing has attracted considerable interest due to its convenience and user-friendliness. However, methods that rely on implicit 3D representations, such as Neural Radiance Fields (NeRF), while effective in rendering complex scenes, are hindered by slow processing speeds and limited control over specific regions of the scene. Moreover, existing approaches, including Instruct-NeRF2NeRF and GaussianEditor, which utilize multi-view editing strategies, frequently produce inconsistent results across different views when executing text instructions. This inconsistency can adversely affect the overall performance of the model, complicating the task of balancing the consistency of editing results with editing efficiency. To address these challenges, we propose a novel method termed Single-View to 3D Object Editing via Gaussian Splatting (SVGS), which is a single-view text-driven editing technique based on 3D Gaussian Splatting (3DGS). Specifically, in response to text instructions, we introduce a single-view editing strategy grounded in multi-view diffusion models, which reconstructs 3D scenes by leveraging only those views that yield consistent editing results. Additionally, we employ sparse 3D Gaussian Splatting as the 3D representation, which significantly enhances editing efficiency. We conducted a comparative analysis of SVGS against existing baseline methods across various scene settings, and the results indicate that SVGS outperforms its counterparts in both editing capability and processing speed, representing a significant advancement in 3D editing technology. For further details, please visit our project page at: https://amateurc.github.io/svgs.github.io.
A Very Big Video Reasoning Suite
Feb 24, 2026Rapid progress in video models has largely focused on visual quality, leaving their reasoning capabilities underexplored. Video reasoning grounds intelligence in spatiotemporally consistent visual environments that go beyond what text can naturally capture, enabling intuitive reasoning over spatiotemporal structure such as continuity, interaction, and causality. However, systematically studying video reasoning and its scaling behavior is hindered by the lack of large-scale training data. To address this gap, we introduce the Very Big Video Reasoning (VBVR) Dataset, an unprecedentedly large-scale resource spanning 200 curated reasoning tasks following a principled taxonomy and over one million video clips, approximately three orders of magnitude larger than existing datasets. We further present VBVR-Bench, a verifiable evaluation framework that moves beyond model-based judging by incorporating rule-based, human-aligned scorers, enabling reproducible and interpretable diagnosis of video reasoning capabilities. Leveraging the VBVR suite, we conduct one of the first large-scale scaling studies of video reasoning and observe early signs of emergent generalization to unseen reasoning tasks. Together, VBVR lays a foundation for the next stage of research in generalizable video reasoning. The data, benchmark toolkit, and models are publicly available at https://video-reason.com/ .
AVMeme Exam: A Multimodal Multilingual Multicultural Benchmark for LLMs' Contextual and Cultural Knowledge and Thinking
Jan 25, 2026Internet audio-visual clips convey meaning through time-varying sound and motion, which extend beyond what text alone can represent. To examine whether AI models can understand such signals in human cultural contexts, we introduce AVMeme Exam, a human-curated benchmark of over one thousand iconic Internet sounds and videos spanning speech, songs, music, and sound effects. Each meme is paired with a unique Q&A assessing levels of understanding from surface content to context and emotion to usage and world knowledge, along with metadata such as original year, transcript, summary, and sensitivity. We systematically evaluate state-of-the-art multimodal large language models (MLLMs) alongside human participants using this benchmark. Our results reveal a consistent limitation: current models perform poorly on textless music and sound effects, and struggle to think in context and in culture compared to surface content. These findings highlight a key gap in human-aligned multimodal intelligence and call for models that can perceive contextually and culturally beyond the surface of what they hear and see. Project page: avmemeexam.github.io/public
From Chains to DAGs: Probing the Graph Structure of Reasoning in LLMs
Jan 24, 2026Recent progress in large language models has renewed interest in mechanistically characterizing how multi-step reasoning is represented and computed. While much prior work treats reasoning as a linear chain of steps, many reasoning problems are more naturally structured as directed acyclic graphs (DAGs), where intermediate conclusions may depend on multiple premises, branch into parallel sub-derivations, and later merge or be reused. Understanding whether such graph-structured reasoning is reflected in model internals remains an open question. In this work, we introduce Reasoning DAG Probing, a framework that directly asks whether LLM hidden states encode the geometry of a reasoning DAG in a linearly accessible form, and where this structure emerges across layers. Within this framework, we associate each reasoning node with a textual realization and train lightweight probes to predict two graph-theoretic properties from hidden states: node depth and pairwise node distance. We use these probes to analyze the layerwise emergence of DAG structure and evaluate controls that disrupt reasoning-relevant structure while preserving superficial textual properties. Our results provide evidence that reasoning DAG geometry is meaningfully encoded in intermediate layers, with recoverability varying systematically by node depth and model scale, suggesting that LLM reasoning is not only sequential but exhibits measurable internal graph structure.
Far from the Shallow: Brain-Predictive Reasoning Embedding through Residual Disentanglement
Oct 26, 2025Understanding how the human brain progresses from processing simple linguistic inputs to performing high-level reasoning is a fundamental challenge in neuroscience. While modern large language models (LLMs) are increasingly used to model neural responses to language, their internal representations are highly "entangled," mixing information about lexicon, syntax, meaning, and reasoning. This entanglement biases conventional brain encoding analyses toward linguistically shallow features (e.g., lexicon and syntax), making it difficult to isolate the neural substrates of cognitively deeper processes. Here, we introduce a residual disentanglement method that computationally isolates these components. By first probing an LM to identify feature-specific layers, our method iteratively regresses out lower-level representations to produce four nearly orthogonal embeddings for lexicon, syntax, meaning, and, critically, reasoning. We used these disentangled embeddings to model intracranial (ECoG) brain recordings from neurosurgical patients listening to natural speech. We show that: 1) This isolated reasoning embedding exhibits unique predictive power, accounting for variance in neural activity not explained by other linguistic features and even extending to the recruitment of visual regions beyond classical language areas. 2) The neural signature for reasoning is temporally distinct, peaking later (~350-400ms) than signals related to lexicon, syntax, and meaning, consistent with its position atop a processing hierarchy. 3) Standard, non-disentangled LLM embeddings can be misleading, as their predictive success is primarily attributable to linguistically shallow features, masking the more subtle contributions of deeper cognitive processing.
Layer-wise Minimal Pair Probing Reveals Contextual Grammatical-Conceptual Hierarchy in Speech Representations
Sep 19, 2025Transformer-based speech language models (SLMs) have significantly improved neural speech recognition and understanding. While existing research has examined how well SLMs encode shallow acoustic and phonetic features, the extent to which SLMs encode nuanced syntactic and conceptual features remains unclear. By drawing parallels with linguistic competence assessments for large language models, this study is the first to systematically evaluate the presence of contextual syntactic and semantic features across SLMs for self-supervised learning (S3M), automatic speech recognition (ASR), speech compression (codec), and as the encoder for auditory large language models (AudioLLMs). Through minimal pair designs and diagnostic feature analysis across 71 tasks spanning diverse linguistic levels, our layer-wise and time-resolved analysis uncovers that 1) all speech encode grammatical features more robustly than conceptual ones.
SightSound-R1: Cross-Modal Reasoning Distillation from Vision to Audio Language Models
Sep 19, 2025While large audio-language models (LALMs) have demonstrated state-of-the-art audio understanding, their reasoning capability in complex soundscapes still falls behind large vision-language models (LVLMs). Compared to the visual domain, one bottleneck is the lack of large-scale chain-of-thought audio data to teach LALM stepwise reasoning. To circumvent this data and modality gap, we present SightSound-R1, a cross-modal distillation framework that transfers advanced reasoning from a stronger LVLM teacher to a weaker LALM student on the same audio-visual question answering (AVQA) dataset. SightSound-R1 consists of three core steps: (i) test-time scaling to generate audio-focused chains of thought (CoT) from an LVLM teacher, (ii) audio-grounded validation to filter hallucinations, and (iii) a distillation pipeline with supervised fine-tuning (SFT) followed by Group Relative Policy Optimization (GRPO) for the LALM student. Results show that SightSound-R1 improves LALM reasoning performance both in the in-domain AVQA test set as well as in unseen auditory scenes and questions, outperforming both pretrained and label-only distilled baselines. Thus, we conclude that vision reasoning can be effectively transferred to audio models and scaled with abundant audio-visual data.
XCOMPS: A Multilingual Benchmark of Conceptual Minimal Pairs
Feb 27, 2025



We introduce XCOMPS in this work, a multilingual conceptual minimal pair dataset covering 17 languages. Using this dataset, we evaluate LLMs' multilingual conceptual understanding through metalinguistic prompting, direct probability measurement, and neurolinguistic probing. By comparing base, instruction-tuned, and knowledge-distilled models, we find that: 1) LLMs exhibit weaker conceptual understanding for low-resource languages, and accuracy varies across languages despite being tested on the same concept sets. 2) LLMs excel at distinguishing concept-property pairs that are visibly different but exhibit a marked performance drop when negative pairs share subtle semantic similarities. 3) Instruction tuning improves performance in concept understanding but does not enhance internal competence; knowledge distillation can enhance internal competence in conceptual understanding for low-resource languages with limited gains in explicit task performance. 4) More morphologically complex languages yield lower concept understanding scores and require deeper layers for conceptual reasoning.
Large Language Models as Neurolinguistic Subjects: Identifying Internal Representations for Form and Meaning
Nov 12, 2024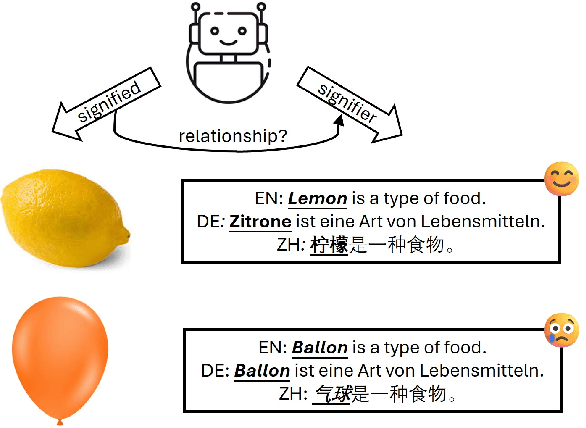
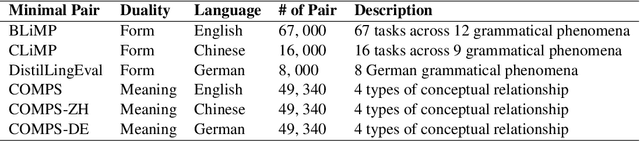
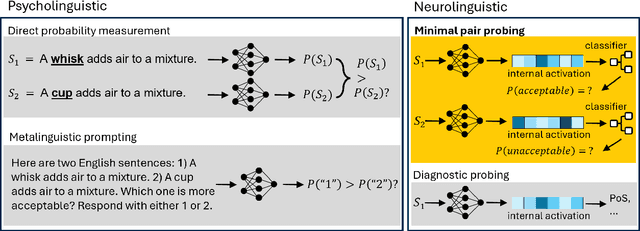
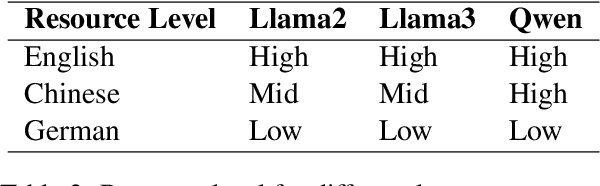
This study investigates the linguistic understanding of Large Language Models (LLMs) regarding signifier (form) and signified (meaning) by distinguishing two LLM evaluation paradigms: psycholinguistic and neurolinguistic. Traditional psycholinguistic evaluations often reflect statistical biases that may misrepresent LLMs' true linguistic capabilities. We introduce a neurolinguistic approach, utilizing a novel method that combines minimal pair and diagnostic probing to analyze activation patterns across model layers. This method allows for a detailed examination of how LLMs represent form and meaning, and whether these representations are consistent across languages. Our contributions are three-fold: (1) We compare neurolinguistic and psycholinguistic methods, revealing distinct patterns in LLM assessment; (2) We demonstrate that LLMs exhibit higher competence in form compared to meaning, with the latter largely correlated to the former; (3) We present new conceptual minimal pair datasets for Chinese (COMPS-ZH) and German (COMPS-DE), complementing existing English datasets.