 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXCOMPS: A Multilingual Benchmark of Conceptual Minimal Pairs
Feb 27, 2025



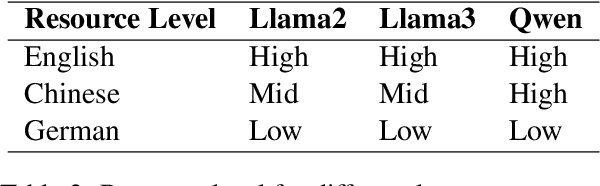
We introduce XCOMPS in this work, a multilingual conceptual minimal pair dataset covering 17 languages. Using this dataset, we evaluate LLMs' multilingual conceptual understanding through metalinguistic prompting, direct probability measurement, and neurolinguistic probing. By comparing base, instruction-tuned, and knowledge-distilled models, we find that: 1) LLMs exhibit weaker conceptual understanding for low-resource languages, and accuracy varies across languages despite being tested on the same concept sets. 2) LLMs excel at distinguishing concept-property pairs that are visibly different but exhibit a marked performance drop when negative pairs share subtle semantic similarities. 3) Instruction tuning improves performance in concept understanding but does not enhance internal competence; knowledge distillation can enhance internal competence in conceptual understanding for low-resource languages with limited gains in explicit task performance. 4) More morphologically complex languages yield lower concept understanding scores and require deeper layers for conceptual reasoning.
Large Language Models as Neurolinguistic Subjects: Identifying Internal Representations for Form and Meaning
Nov 12, 2024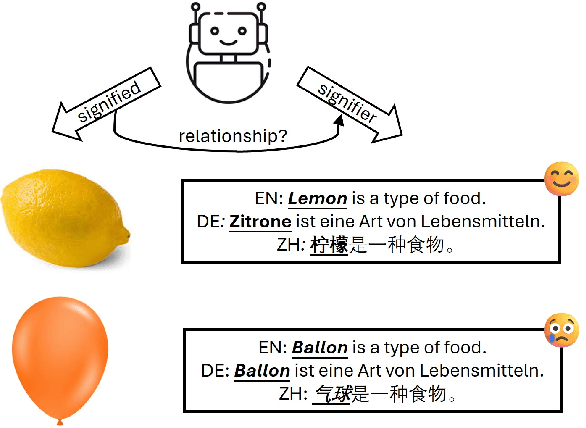
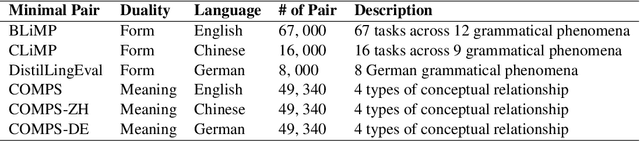
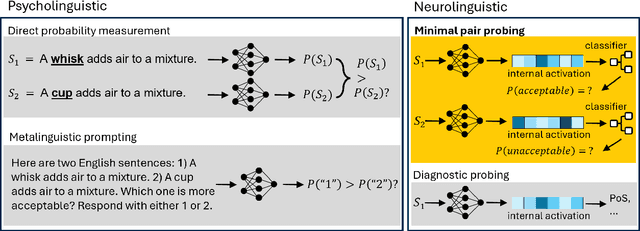
This study investigates the linguistic understanding of Large Language Models (LLMs) regarding signifier (form) and signified (meaning) by distinguishing two LLM evaluation paradigms: psycholinguistic and neurolinguistic. Traditional psycholinguistic evaluations often reflect statistical biases that may misrepresent LLMs' true linguistic capabilities. We introduce a neurolinguistic approach, utilizing a novel method that combines minimal pair and diagnostic probing to analyze activation patterns across model layers. This method allows for a detailed examination of how LLMs represent form and meaning, and whether these representations are consistent across languages. Our contributions are three-fold: (1) We compare neurolinguistic and psycholinguistic methods, revealing distinct patterns in LLM assessment; (2) We demonstrate that LLMs exhibit higher competence in form compared to meaning, with the latter largely correlated to the former; (3) We present new conceptual minimal pair datasets for Chinese (COMPS-ZH) and German (COMPS-DE), complementing existing English datasets.