 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIGMA: A Physics-Based Benchmark for Gas Chimney Understanding in Seismic Images
Mar 24, 2026Seismic images reconstruct subsurface reflectivity from field recordings, guiding exploration and reservoir monitoring. Gas chimneys are vertical anomalies caused by subsurface fluid migration. Understanding these phenomena is crucial for assessing hydrocarbon potential and avoiding drilling hazards. However, accurate detection is challenging due to strong seismic attenuation and scattering. Traditional physics-based methods are computationally expensive and sensitive to model errors, while deep learning offers efficient alternatives, yet lacks labeled datasets. In this work, we introduce \textbf{SIGMA}, a new physics-based dataset for gas chimney understanding in seismic images, featuring (i) pixel-level gas-chimney mask for detection and (ii) paired degraded and ground-truth image for enhancement. We employed physics-based methods that cover a wide range of geological settings and data acquisition conditions. Comprehensive experiments demonstrate that SIGMA serves as a challenging benchmark for gas chimney interpretation and benefits general seismic understanding.
DiFlowDubber: Discrete Flow Matching for Automated Video Dubbing via Cross-Modal Alignment and Synchronization
Mar 17, 2026Video dubbing has broad applications in filmmaking, multimedia creation, and assistive speech technology. Existing approaches either train directly on limited dubbing datasets or adopt a two-stage pipeline that adapts pre-trained text-to-speech (TTS) models, which often struggle to produce expressive prosody, rich acoustic characteristics, and precise synchronization. To address these issues, we propose DiFlowDubber with a novel two-stage training framework that effectively transfers knowledge from a pre-trained TTS model to video-driven dubbing, with a discrete flow matching generative backbone. Specifically, we design a FaPro module that captures global prosody and stylistic cues from facial expressions and leverages this information to guide the modeling of subsequent speech attributes. To ensure precise speech-lip synchronization, we introduce a Synchronizer module that bridges the modality gap among text, video, and speech, thereby improving cross-modal alignment and generating speech that is temporally synchronized with lip movements. Experiments on two primary benchmark datasets demonstrate that DiFlowDubber outperforms previous methods across multiple metrics.
MulVuln: Enhancing Pre-trained LMs with Shared and Language-Specific Knowledge for Multilingual Vulnerability Detection
Oct 05, 2025Software vulnerabilities (SVs) pose a critical threat to safety-critical systems, driving the adoption of AI-based approaches such as machine learning and deep learning for software vulnerability detection. Despite promising results, most existing methods are limited to a single programming language. This is problematic given the multilingual nature of modern software, which is often complex and written in multiple languages. Current approaches often face challenges in capturing both shared and language-specific knowledge of source code, which can limit their performance on diverse programming languages and real-world codebases. To address this gap, we propose MULVULN, a novel multilingual vulnerability detection approach that learns from source code across multiple languages. MULVULN captures both the shared knowledge that generalizes across languages and the language-specific knowledge that reflects unique coding conventions. By integrating these aspects, it achieves more robust and effective detection of vulnerabilities in real-world multilingual software systems. The rigorous and extensive experiments on the real-world and diverse REEF dataset, consisting of 4,466 CVEs with 30,987 patches across seven programming languages, demonstrate the superiority of MULVULN over thirteen effective and state-of-the-art baselines. Notably, MULVULN achieves substantially higher F1-score, with improvements ranging from 1.45% to 23.59% compared to the baseline methods.
DiFlow-TTS: Discrete Flow Matching with Factorized Speech Tokens for Low-Latency Zero-Shot Text-To-Speech
Sep 11, 2025Zero-shot Text-to-Speech (TTS) aims to synthesize high-quality speech that mimics the voice of an unseen speaker using only a short reference sample, requiring not only speaker adaptation but also accurate modeling of prosodic attributes. Recent approaches based on language models, diffusion, and flow matching have shown promising results in zero-shot TTS, but still suffer from slow inference and repetition artifacts. Discrete codec representations have been widely adopted for speech synthesis, and recent works have begun to explore diffusion models in purely discrete settings, suggesting the potential of discrete generative modeling for speech synthesis. However, existing flow-matching methods typically embed these discrete tokens into a continuous space and apply continuous flow matching, which may not fully leverage the advantages of discrete representations. To address these challenges, we introduce DiFlow-TTS, which, to the best of our knowledge, is the first model to explore purely Discrete Flow Matching for speech synthesis. DiFlow-TTS explicitly models factorized speech attributes within a compact and unified architecture. It leverages in-context learning by conditioning on textual content, along with prosodic and acoustic attributes extracted from a reference speech, enabling effective attribute cloning in a zero-shot setting. In addition, the model employs a factorized flow prediction mechanism with distinct heads for prosody and acoustic details, allowing it to learn aspect-specific distributions. Experimental results demonstrate that DiFlow-TTS achieves promising performance in several key metrics, including naturalness, prosody, preservation of speaker style, and energy control. It also maintains a compact model size and achieves low-latency inference, generating speech up to 25.8 times faster than the latest existing baselines.
RESOUND: Speech Reconstruction from Silent Videos via Acoustic-Semantic Decomposed Modeling
May 28, 2025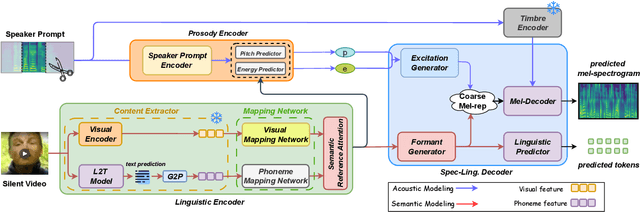
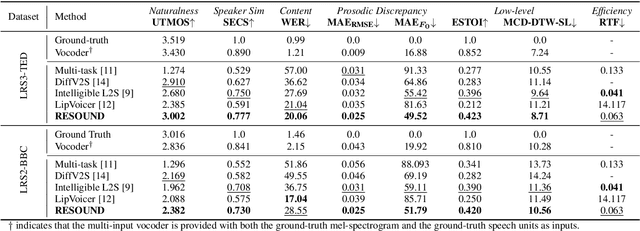

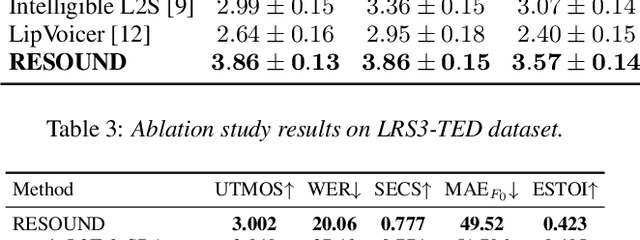
Lip-to-speech (L2S) synthesis, which reconstructs speech from visual cues, faces challenges in accuracy and naturalness due to limited supervision in capturing linguistic content, accents, and prosody. In this paper, we propose RESOUND, a novel L2S system that generates intelligible and expressive speech from silent talking face videos. Leveraging source-filter theory, our method involves two components: an acoustic path to predict prosody and a semantic path to extract linguistic features. This separation simplifies learning, allowing independent optimization of each representation. Additionally, we enhance performance by integrating speech units, a proven unsupervised speech representation technique, into waveform generation alongside mel-spectrograms. This allows RESOUND to synthesize prosodic speech while preserving content and speaker identity. Experiments conducted on two standard L2S benchmarks confirm the effectiveness of the proposed method across various metrics.
OZSpeech: One-step Zero-shot Speech Synthesis with Learned-Prior-Conditioned Flow Matching
May 19, 2025Text-to-speech (TTS) systems have seen significant advancements in recent years, driven by improvements in deep learning and neural network architectures. Viewing the output speech as a data distribution, previous approaches often employ traditional speech representations, such as waveforms or spectrograms, within the Flow Matching framework. However, these methods have limitations, including overlooking various speech attributes and incurring high computational costs due to additional constraints introduced during training. To address these challenges, we introduce OZSpeech, the first TTS method to explore optimal transport conditional flow matching with one-step sampling and a learned prior as the condition, effectively disregarding preceding states and reducing the number of sampling steps. Our approach operates on disentangled, factorized components of speech in token format, enabling accurate modeling of each speech attribute, which enhances the TTS system's ability to precisely clone the prompt speech. Experimental results show that our method achieves promising performance over existing methods in content accuracy, naturalness, prosody generation, and speaker style preservation. Audio samples are available at our demo page https://ozspeech.github.io/OZSpeech_Web/.
CompeteSMoE -- Statistically Guaranteed Mixture of Experts Training via Competition
May 19, 2025
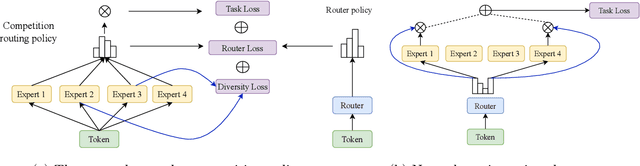


Sparse mixture of experts (SMoE) offers an appealing solution to scale up the model complexity beyond the mean of increasing the network's depth or width. However, we argue that effective SMoE training remains challenging because of the suboptimal routing process where experts that perform computation do not directly contribute to the routing process. In this work, we propose competition, a novel mechanism to route tokens to experts with the highest neural response. Theoretically, we show that the competition mechanism enjoys a better sample efficiency than the traditional softmax routing. Furthermore, we develop CompeteSMoE, a simple yet effective algorithm to train large language models by deploying a router to learn the competition policy, thus enjoying strong performances at a low training overhead. Our extensive empirical evaluations on both the visual instruction tuning and language pre-training tasks demonstrate the efficacy, robustness, and scalability of CompeteSMoE compared to state-of-the-art SMoE strategies. We have made the implementation available at: https://github.com/Fsoft-AIC/CompeteSMoE. This work is an improved version of the previous study at arXiv:2402.02526
XCOMPS: A Multilingual Benchmark of Conceptual Minimal Pairs
Feb 27, 2025



We introduce XCOMPS in this work, a multilingual conceptual minimal pair dataset covering 17 languages. Using this dataset, we evaluate LLMs' multilingual conceptual understanding through metalinguistic prompting, direct probability measurement, and neurolinguistic probing. By comparing base, instruction-tuned, and knowledge-distilled models, we find that: 1) LLMs exhibit weaker conceptual understanding for low-resource languages, and accuracy varies across languages despite being tested on the same concept sets. 2) LLMs excel at distinguishing concept-property pairs that are visibly different but exhibit a marked performance drop when negative pairs share subtle semantic similarities. 3) Instruction tuning improves performance in concept understanding but does not enhance internal competence; knowledge distillation can enhance internal competence in conceptual understanding for low-resource languages with limited gains in explicit task performance. 4) More morphologically complex languages yield lower concept understanding scores and require deeper layers for conceptual reasoning.
Effective Context Modeling Framework for Emotion Recognition in Conversations
Dec 21, 2024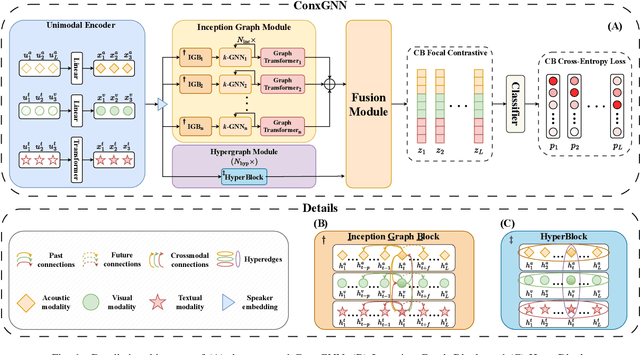
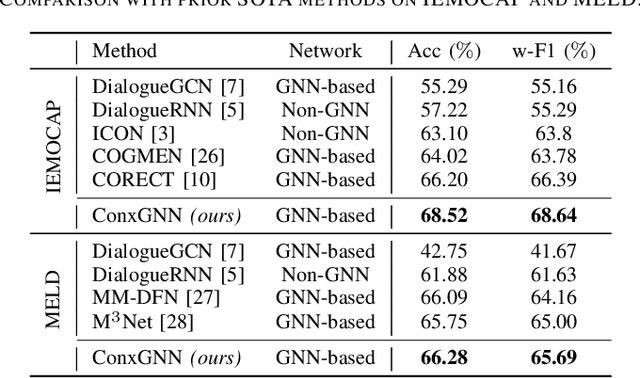
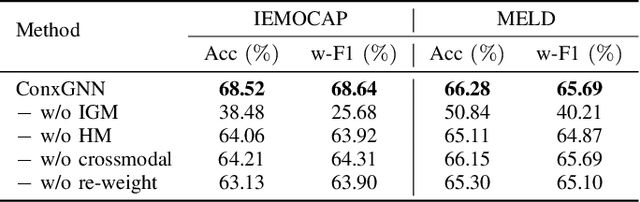
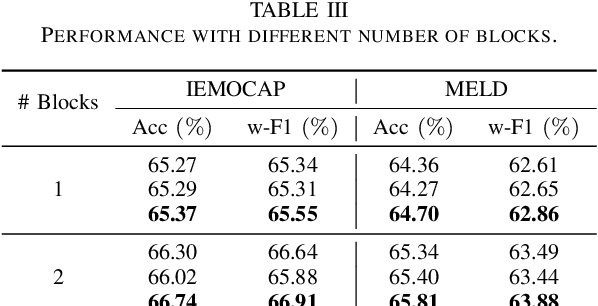
Emotion Recognition in Conversations (ERC) facilitates a deeper understanding of the emotions conveyed by speakers in each utterance within a conversation. Recently, Graph Neural Networks (GNNs) have demonstrated their strengths in capturing data relationships, particularly in contextual information modeling and multimodal fusion. However, existing methods often struggle to fully capture the complex interactions between multiple modalities and conversational context, limiting their expressiveness. To overcome these limitations, we propose ConxGNN, a novel GNN-based framework designed to capture contextual information in conversations. ConxGNN features two key parallel modules: a multi-scale heterogeneous graph that captures the diverse effects of utterances on emotional changes, and a hypergraph that models the multivariate relationships among modalities and utterances. The outputs from these modules are integrated into a fusion layer, where a cross-modal attention mechanism is applied to produce a contextually enriched representation. Additionally, ConxGNN tackles the challenge of recognizing minority or semantically similar emotion classes by incorporating a re-weighting scheme into the loss functions. Experimental results on the IEMOCAP and MELD benchmark datasets demonstrate the effectiveness of our method, achieving state-of-the-art performance compared to previous baselines.
LIBMoE: A Library for comprehensive benchmarking Mixture of Experts in Large Language Models
Nov 01, 2024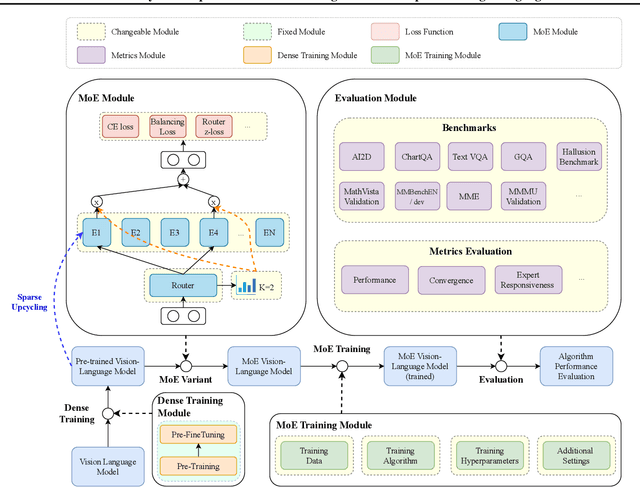
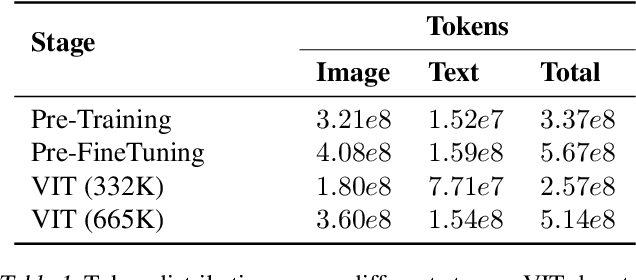
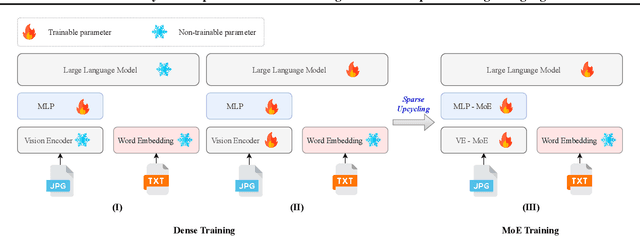
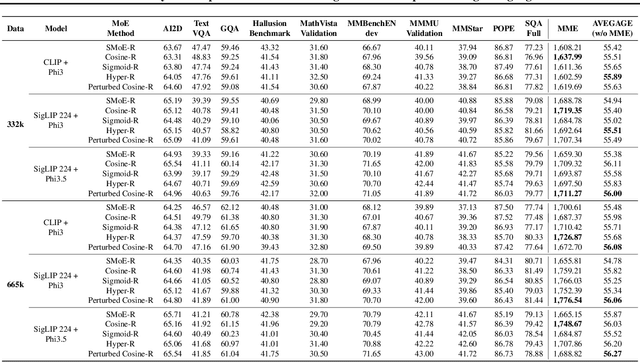
Mixture of Experts (MoEs) plays an important role in the development of more efficient and effective large language models (LLMs). Due to the enormous resource requirements, studying large scale MoE algorithms remain in-accessible to many researchers. This work develops \emph{LibMoE}, a comprehensive and modular framework to streamline the research, training, and evaluation of MoE algorithms. Built upon three core principles: (i) modular design, (ii) efficient training; (iii) comprehensive evaluation, LibMoE brings MoE in LLMs more accessible to a wide range of researchers by standardizing the training and evaluation pipelines. Using LibMoE, we extensively benchmarked five state-of-the-art MoE algorithms over three different LLMs and 11 datasets under the zero-shot setting. The results show that despite the unique characteristics, all MoE algorithms perform roughly similar when averaged across a wide range of tasks. With the modular design and extensive evaluation, we believe LibMoE will be invaluable for researchers to make meaningful progress towards the next generation of MoE and LLMs. Project page: \url{https://fsoft-aic.github.io/fsoft-LibMoE.github.io}.