 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXCOMPS: A Multilingual Benchmark of Conceptual Minimal Pairs
Feb 27, 2025



We introduce XCOMPS in this work, a multilingual conceptual minimal pair dataset covering 17 languages. Using this dataset, we evaluate LLMs' multilingual conceptual understanding through metalinguistic prompting, direct probability measurement, and neurolinguistic probing. By comparing base, instruction-tuned, and knowledge-distilled models, we find that: 1) LLMs exhibit weaker conceptual understanding for low-resource languages, and accuracy varies across languages despite being tested on the same concept sets. 2) LLMs excel at distinguishing concept-property pairs that are visibly different but exhibit a marked performance drop when negative pairs share subtle semantic similarities. 3) Instruction tuning improves performance in concept understanding but does not enhance internal competence; knowledge distillation can enhance internal competence in conceptual understanding for low-resource languages with limited gains in explicit task performance. 4) More morphologically complex languages yield lower concept understanding scores and require deeper layers for conceptual reasoning.
Detecting Post-Stroke Aphasia Via Brain Responses to Speech in a Deep Learning Framework
Jan 17, 2024



Aphasia, a language disorder primarily caused by a stroke, is traditionally diagnosed using behavioral language tests. However, these tests are time-consuming, require manual interpretation by trained clinicians, suffer from low ecological validity, and diagnosis can be biased by comorbid motor and cognitive problems present in aphasia. In this study, we introduce an automated screening tool for speech processing impairments in aphasia that relies on time-locked brain responses to speech, known as neural tracking, within a deep learning framework. We modeled electroencephalography (EEG) responses to acoustic, segmentation, and linguistic speech representations of a story using convolutional neural networks trained on a large sample of healthy participants, serving as a model for intact neural tracking of speech. Subsequently, we evaluated our models on an independent sample comprising 26 individuals with aphasia (IWA) and 22 healthy controls. Our results reveal decreased tracking of all speech representations in IWA. Utilizing a support vector machine classifier with neural tracking measures as input, we demonstrate high accuracy in aphasia detection at the individual level (85.42\%) in a time-efficient manner (requiring 9 minutes of EEG data). Given its high robustness, time efficiency, and generalizability to unseen data, our approach holds significant promise for clinical applications.
Relating EEG to continuous speech using deep neural networks: a review
Feb 06, 2023Objective. When a person listens to continuous speech, a corresponding response is elicited in the brain and can be recorded using electroencephalography (EEG). Linear models are presently used to relate the EEG recording to the corresponding speech signal. The ability of linear models to find a mapping between these two signals is used as a measure of neural tracking of speech. Such models are limited as they assume linearity in the EEG-speech relationship, which omits the nonlinear dynamics of the brain. As an alternative, deep learning models have recently been used to relate EEG to continuous speech, especially in auditory attention decoding (AAD) and single-speech-source paradigms. Approach. This paper reviews and comments on deep-learning-based studies that relate EEG to continuous speech in AAD and single-speech-source paradigms. We point out recurrent methodological pitfalls and the need for a standard benchmark of model analysis. Main results. We gathered 28 studies. The main methodological issues we found are biased cross-validations, data leakage leading to over-fitted models, or disproportionate data size compared to the model's complexity. In addition, we address requirements for a standard benchmark model analysis, such as public datasets, common evaluation metrics, and good practices for the match-mismatch task. Significance. We are the first to present a review paper summarizing the main deep-learning-based studies that relate EEG to speech while addressing methodological pitfalls and important considerations for this newly expanding field. Our study is particularly relevant given the growing application of deep learning in EEG-speech decoding.
Relating the fundamental frequency of speech with EEG using a dilated convolutional network
Jul 05, 2022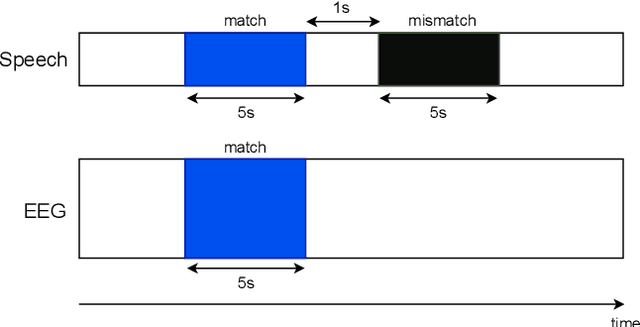
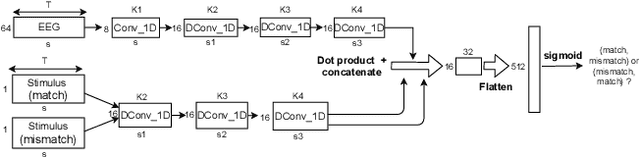
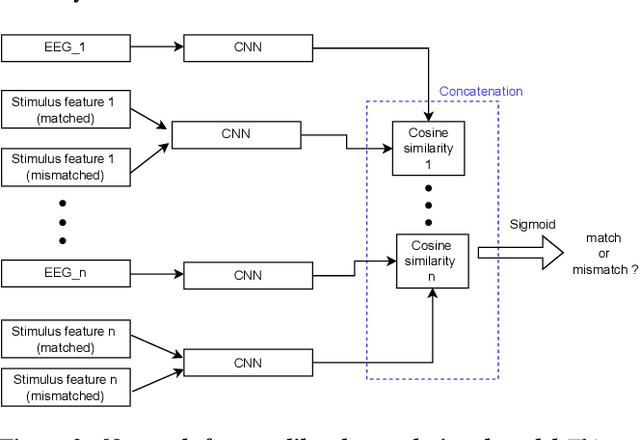
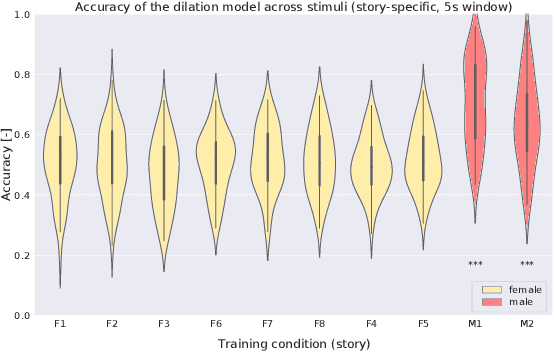
To investigate how speech is processed in the brain, we can model the relation between features of a natural speech signal and the corresponding recorded electroencephalogram (EEG). Usually, linear models are used in regression tasks. Either EEG is predicted, or speech is reconstructed, and the correlation between predicted and actual signal is used to measure the brain's decoding ability. However, given the nonlinear nature of the brain, the modeling ability of linear models is limited. Recent studies introduced nonlinear models to relate the speech envelope to EEG. We set out to include other features of speech that are not coded in the envelope, notably the fundamental frequency of the voice (f0). F0 is a higher-frequency feature primarily coded at the brainstem to midbrain level. We present a dilated-convolutional model to provide evidence of neural tracking of the f0. We show that a combination of f0 and the speech envelope improves the performance of a state-of-the-art envelope-based model. This suggests the dilated-convolutional model can extract non-redundant information from both f0 and the envelope. We also show the ability of the dilated-convolutional model to generalize to subjects not included during training. This latter finding will accelerate f0-based hearing diagnosis.