 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Post-Stroke Aphasia Via Brain Responses to Speech in a Deep Learning Framework
Jan 17, 2024



Aphasia, a language disorder primarily caused by a stroke, is traditionally diagnosed using behavioral language tests. However, these tests are time-consuming, require manual interpretation by trained clinicians, suffer from low ecological validity, and diagnosis can be biased by comorbid motor and cognitive problems present in aphasia. In this study, we introduce an automated screening tool for speech processing impairments in aphasia that relies on time-locked brain responses to speech, known as neural tracking, within a deep learning framework. We modeled electroencephalography (EEG) responses to acoustic, segmentation, and linguistic speech representations of a story using convolutional neural networks trained on a large sample of healthy participants, serving as a model for intact neural tracking of speech. Subsequently, we evaluated our models on an independent sample comprising 26 individuals with aphasia (IWA) and 22 healthy controls. Our results reveal decreased tracking of all speech representations in IWA. Utilizing a support vector machine classifier with neural tracking measures as input, we demonstrate high accuracy in aphasia detection at the individual level (85.42\%) in a time-efficient manner (requiring 9 minutes of EEG data). Given its high robustness, time efficiency, and generalizability to unseen data, our approach holds significant promise for clinical applications.
Extracting Different Levels of Speech Information from EEG Using an LSTM-Based Model
Jun 17, 2021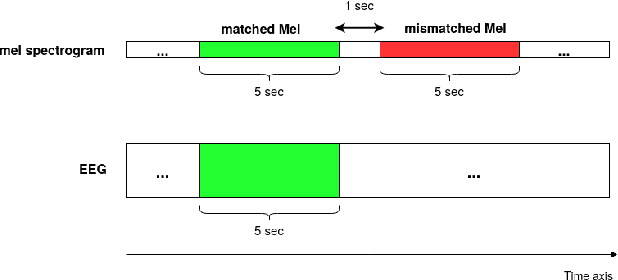
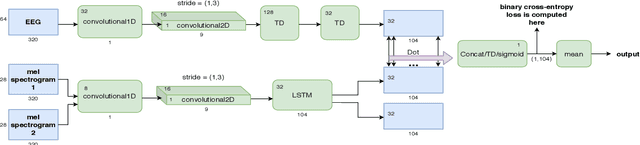
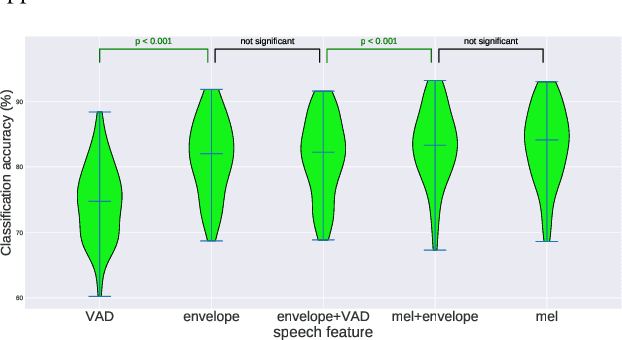
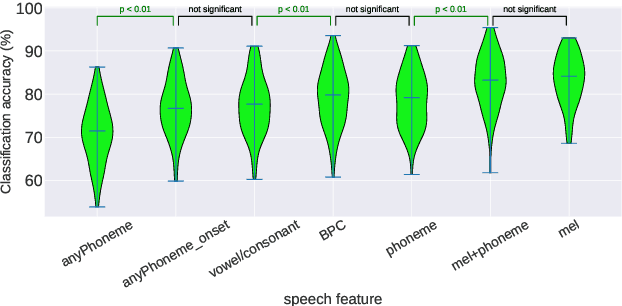
Decoding the speech signal that a person is listening to from the human brain via electroencephalography (EEG) can help us understand how our auditory system works. Linear models have been used to reconstruct the EEG from speech or vice versa. Recently, Artificial Neural Networks (ANNs) such as Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) based architectures have outperformed linear models in modeling the relation between EEG and speech. Before attempting to use these models in real-world applications such as hearing tests or (second) language comprehension assessment we need to know what level of speech information is being utilized by these models. In this study, we aim to analyze the performance of an LSTM-based model using different levels of speech features. The task of the model is to determine which of two given speech segments is matched with the recorded EEG. We used low- and high-level speech features including: envelope, mel spectrogram, voice activity, phoneme identity, and word embedding. Our results suggest that the model exploits information about silences, intensity, and broad phonetic classes from the EEG. Furthermore, the mel spectrogram, which contains all this information, yields the highest accuracy (84%) among all the features.