 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-decoder Neural Tracking Method for Accurately Predicting Speech Intelligibility
Feb 03, 2026Objective: EEG-based methods can predict speech intelligibility, but their accuracy and robustness lag behind behavioral tests, which typically show test-retest differences under 1 dB. We introduce the multi-decoder method to predict speech reception thresholds (SRTs) from EEG recordings, enabling objective assessment for populations unable to perform behavioral tests; such as those with disorders of consciousness or during hearing aid fitting. Approach: The method aggregates data from hundreds of decoders, each trained on different speech features and EEG preprocessing setups to quantify neural tracking (NT) of speech signals. Using data from 39 participants (ages 18-24), we recorded 29 minutes of EEG per person while they listened to speech at six signal-to-noise ratios and a quiet story. NT values were combined into a high-dimensional feature vector per subject, and a support vector regression model was trained to predict SRTs from these vectors. Main Result: Predictions correlated significantly with behavioral SRTs (r = 0.647, p < 0.001; NRMSE = 0.19), with all differences under 1 dB. SHAP analysis showed theta/delta bands and early lags had slightly greater influence. Using pretrained subject-independent decoders reduced required EEG data collection to 15 minutes (3 minutes of story, 12 minutes across six SNR conditions) without losing accuracy.
Relating EEG to continuous speech using deep neural networks: a review
Feb 06, 2023Objective. When a person listens to continuous speech, a corresponding response is elicited in the brain and can be recorded using electroencephalography (EEG). Linear models are presently used to relate the EEG recording to the corresponding speech signal. The ability of linear models to find a mapping between these two signals is used as a measure of neural tracking of speech. Such models are limited as they assume linearity in the EEG-speech relationship, which omits the nonlinear dynamics of the brain. As an alternative, deep learning models have recently been used to relate EEG to continuous speech, especially in auditory attention decoding (AAD) and single-speech-source paradigms. Approach. This paper reviews and comments on deep-learning-based studies that relate EEG to continuous speech in AAD and single-speech-source paradigms. We point out recurrent methodological pitfalls and the need for a standard benchmark of model analysis. Main results. We gathered 28 studies. The main methodological issues we found are biased cross-validations, data leakage leading to over-fitted models, or disproportionate data size compared to the model's complexity. In addition, we address requirements for a standard benchmark model analysis, such as public datasets, common evaluation metrics, and good practices for the match-mismatch task. Significance. We are the first to present a review paper summarizing the main deep-learning-based studies that relate EEG to speech while addressing methodological pitfalls and important considerations for this newly expanding field. Our study is particularly relevant given the growing application of deep learning in EEG-speech decoding.
Extracting Different Levels of Speech Information from EEG Using an LSTM-Based Model
Jun 17, 2021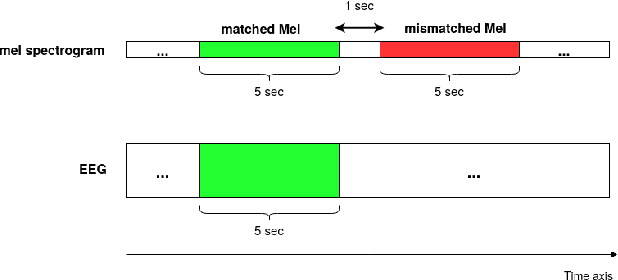
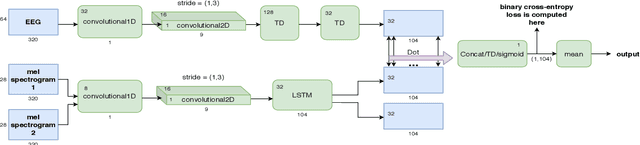
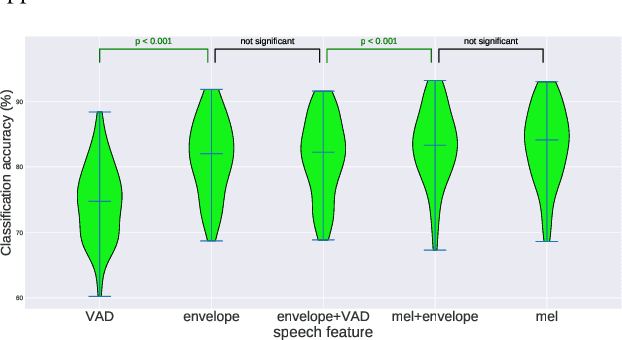
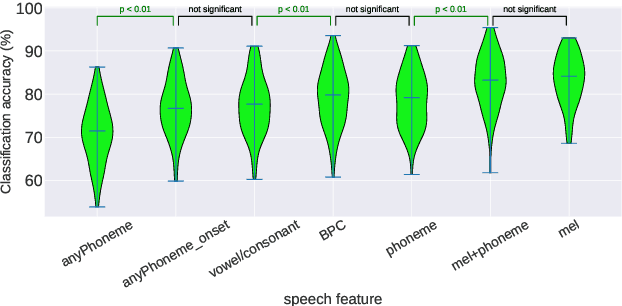
Decoding the speech signal that a person is listening to from the human brain via electroencephalography (EEG) can help us understand how our auditory system works. Linear models have been used to reconstruct the EEG from speech or vice versa. Recently, Artificial Neural Networks (ANNs) such as Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) based architectures have outperformed linear models in modeling the relation between EEG and speech. Before attempting to use these models in real-world applications such as hearing tests or (second) language comprehension assessment we need to know what level of speech information is being utilized by these models. In this study, we aim to analyze the performance of an LSTM-based model using different levels of speech features. The task of the model is to determine which of two given speech segments is matched with the recorded EEG. We used low- and high-level speech features including: envelope, mel spectrogram, voice activity, phoneme identity, and word embedding. Our results suggest that the model exploits information about silences, intensity, and broad phonetic classes from the EEG. Furthermore, the mel spectrogram, which contains all this information, yields the highest accuracy (84%) among all the features.
Predicting speech intelligibility from EEG using a dilated convolutional network
May 19, 2021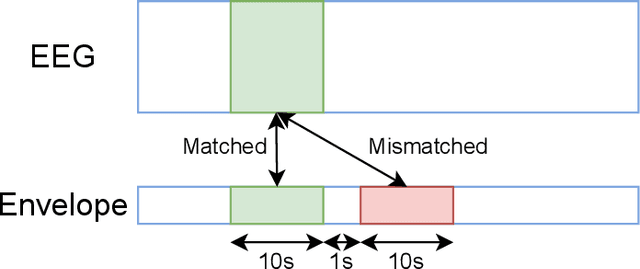
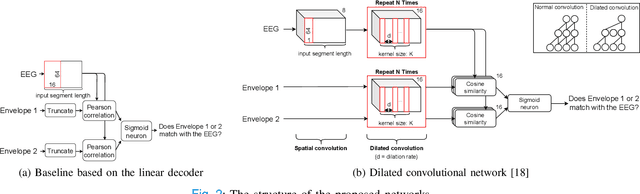
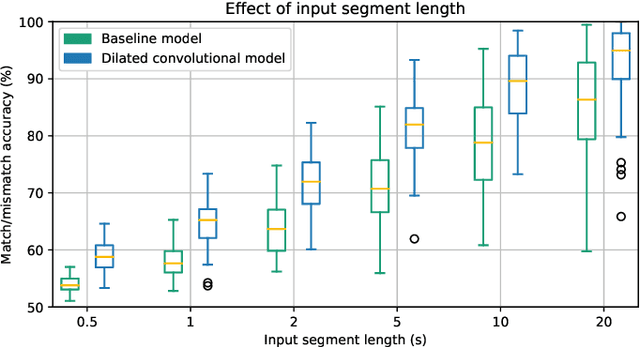
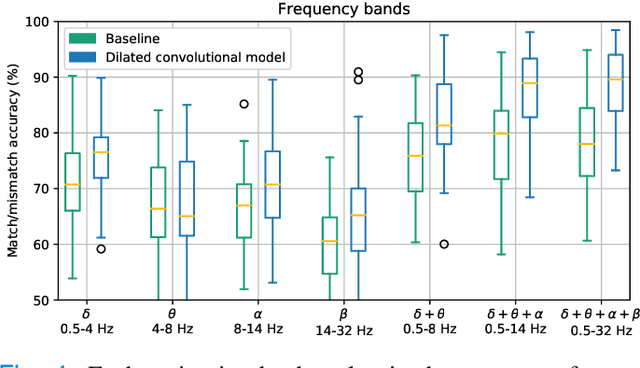
Objective: Currently, only behavioral speech understanding tests are available, which require active participation of the person. As this is infeasible for certain populations, an objective measure of speech intelligibility is required. Recently, brain imaging data has been used to establish a relationship between stimulus and brain response. Linear models have been successfully linked to speech intelligibility but require per-subject training. We present a deep-learning-based model incorporating dilated convolutions that can be used to predict speech intelligibility without subject-specific (re)training. Methods: We evaluated the performance of the model as a function of input segment length, EEG frequency band and receptive field size while comparing it to a baseline model. Next, we evaluated performance on held-out data and finetuning. Finally, we established a link between the accuracy of our model and the state-of-the-art behavioral MATRIX test. Results: The model significantly outperformed the baseline for every input segment length (p$\leq10^{-9}$), for all EEG frequency bands except the theta band (p$\leq0.001$) and for receptive field sizes larger than 125 ms (p$\leq0.05$). Additionally, finetuning significantly increased the accuracy (p$\leq0.05$) on a held-out dataset. Finally, a significant correlation (r=0.59, p=0.0154) was found between the speech reception threshold estimated using the behavioral MATRIX test and our objective method. Conclusion: Our proposed dilated convolutional model can be used as a proxy for speech intelligibility. Significance: Our method is the first to predict the speech reception threshold from EEG for unseen subjects, contributing to objective measures of speech intelligibility.