 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelating the fundamental frequency of speech with EEG using a dilated convolutional network
Paper and Code
Jul 05, 2022
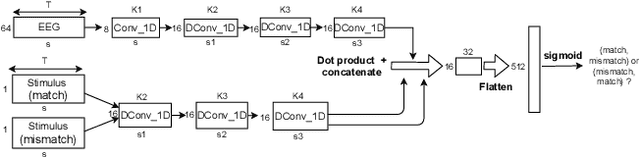
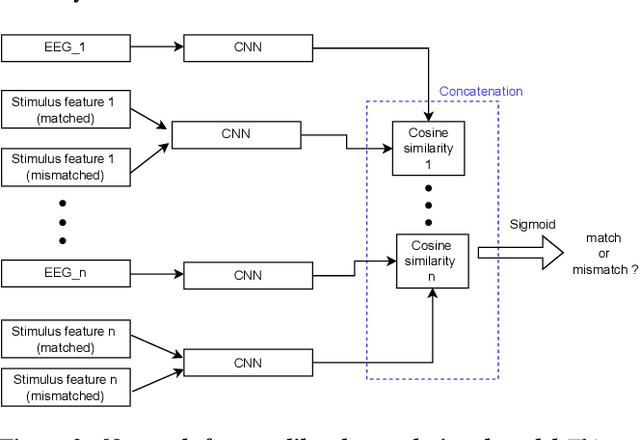
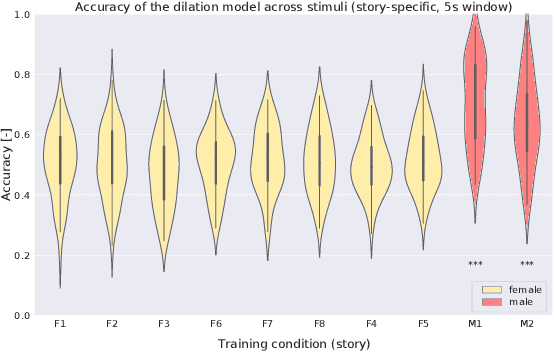
To investigate how speech is processed in the brain, we can model the relation between features of a natural speech signal and the corresponding recorded electroencephalogram (EEG). Usually, linear models are used in regression tasks. Either EEG is predicted, or speech is reconstructed, and the correlation between predicted and actual signal is used to measure the brain's decoding ability. However, given the nonlinear nature of the brain, the modeling ability of linear models is limited. Recent studies introduced nonlinear models to relate the speech envelope to EEG. We set out to include other features of speech that are not coded in the envelope, notably the fundamental frequency of the voice (f0). F0 is a higher-frequency feature primarily coded at the brainstem to midbrain level. We present a dilated-convolutional model to provide evidence of neural tracking of the f0. We show that a combination of f0 and the speech envelope improves the performance of a state-of-the-art envelope-based model. This suggests the dilated-convolutional model can extract non-redundant information from both f0 and the envelope. We also show the ability of the dilated-convolutional model to generalize to subjects not included during training. This latter finding will accelerate f0-based hearing diagnosis.