 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode Readability in the Age of Large Language Models: An Industrial Case Study from Atlassian
Jan 20, 2025Programmers spend a significant amount of time reading code during the software development process. This trend is amplified by the emergence of large language models (LLMs) that automatically generate code. However, little is known about the readability of the LLM-generated code and whether it is still important from practitioners' perspectives in this new era. In this paper, we conduct a survey to explore the practitioners' perspectives on code readability in the age of LLMs and investigate the readability of our LLM-based software development agents framework, HULA, by comparing its generated code with human-written code in real-world scenarios. Overall, the findings underscore that (1) readability remains a critical aspect of software development; (2) the readability of our LLM-generated code is comparable to human-written code, fostering the establishment of appropriate trust and driving the broad adoption of our LLM-powered software development platform.
MORTAR: Metamorphic Multi-turn Testing for LLM-based Dialogue Systems
Dec 20, 2024With the widespread application of LLM-based dialogue systems in daily life, quality assurance has become more important than ever. Recent research has successfully introduced methods to identify unexpected behaviour in single-turn scenarios. However, multi-turn dialogue testing remains underexplored, with the Oracle problem in multi-turn testing posing a persistent challenge for dialogue system developers and researchers. In this paper, we propose MORTAR, a MetamORphic multi-TuRn diAlogue testing appRoach, which mitigates the test oracle problem in the assessment of LLM-based dialogue systems. MORTAR automates the generation of follow-up question-answer (QA) dialogue test cases with multiple dialogue-level perturbations and metamorphic relations. MORTAR employs a novel knowledge graph-based dialogue information model which effectively generates perturbed dialogue test datasets and detects bugs of multi-turn dialogue systems in a low-cost manner. The proposed approach does not require an LLM as a judge, eliminating potential of any biases in the evaluation step. According to the experiment results on multiple LLM-based dialogue systems and comparisons with single-turn metamorphic testing approaches, MORTAR explores more unique bugs in LLM-based dialogue systems, especially for severe bugs that MORTAR detects up to four times more unique bugs than the most effective existing metamorphic testing approach.
Protect Your Secrets: Understanding and Measuring Data Exposure in VSCode Extensions
Dec 01, 2024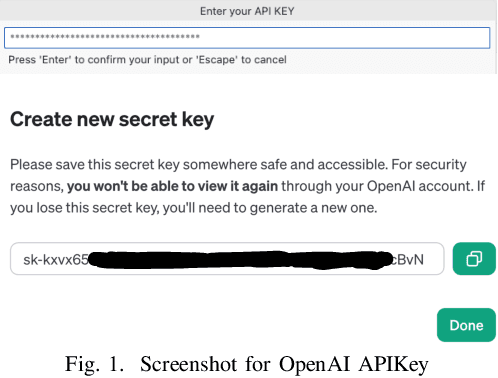
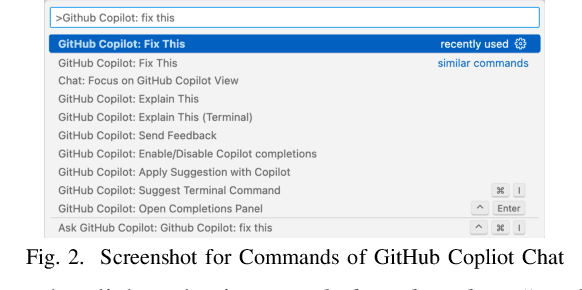
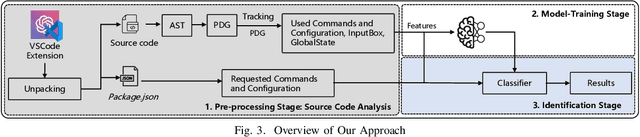

Recent years have witnessed the emerging trend of extensions in modern Integrated Development Environments (IDEs) like Visual Studio Code (VSCode) that significantly enhance developer productivity. Especially, popular AI coding assistants like GitHub Copilot and Tabnine provide conveniences like automated code completion and debugging. While these extensions offer numerous benefits, they may introduce privacy and security concerns to software developers. However, there is no existing work that systematically analyzes the security and privacy concerns, including the risks of data exposure in VSCode extensions. In this paper, we investigate on the security issues of cross-extension interactions in VSCode and shed light on the vulnerabilities caused by data exposure among different extensions. Our study uncovers high-impact security flaws that could allow adversaries to stealthily acquire or manipulate credential-related data (e.g., passwords, API keys, access tokens) from other extensions if not properly handled by extension vendors. To measure their prevalence, we design a novel automated risk detection framework that leverages program analysis and natural language processing techniques to automatically identify potential risks in VSCode extensions. By applying our tool to 27,261 real-world VSCode extensions, we discover that 8.5\% of them (i.e., 2,325 extensions) are exposed to credential-related data leakage through various vectors, such as commands, user input, and configurations. Our study sheds light on the security challenges and flaws of the extension-in-IDE paradigm and provides suggestions and recommendations for improving the security of VSCode extensions and mitigating the risks of data exposure.
Human-In-the-Loop Software Development Agents
Nov 19, 2024Recently, Large Language Models (LLMs)-based multi-agent paradigms for software engineering are introduced to automatically resolve software development tasks (e.g., from a given issue to source code). However, existing work is evaluated based on historical benchmark datasets, does not consider human feedback at each stage of the automated software development process, and has not been deployed in practice. In this paper, we introduce a Human-in-the-loop LLM-based Agents framework (HULA) for software development that allows software engineers to refine and guide LLMs when generating coding plans and source code for a given task. We design, implement, and deploy the HULA framework into Atlassian JIRA for internal uses. Through a multi-stage evaluation of the HULA framework, Atlassian software engineers perceive that HULA can minimize the overall development time and effort, especially in initiating a coding plan and writing code for straightforward tasks. On the other hand, challenges around code quality are raised to be solved in some cases. We draw lessons learned and discuss opportunities for future work, which will pave the way for the advancement of LLM-based agents in software development.
AI for DevSecOps: A Landscape and Future Opportunities
Apr 07, 2024



DevOps has emerged as one of the most rapidly evolving software development paradigms. With the growing concerns surrounding security in software systems, the DevSecOps paradigm has gained prominence, urging practitioners to incorporate security practices seamlessly into the DevOps workflow. However, integrating security into the DevOps workflow can impact agility and impede delivery speed. Recently, the advancement of artificial intelligence (AI) has revolutionized automation in various software domains, including software security. AI-driven security approaches, particularly those leveraging machine learning or deep learning, hold promise in automating security workflows. They reduce manual efforts, which can be integrated into DevOps to ensure uninterrupted delivery speed and align with the DevSecOps paradigm simultaneously. This paper seeks to contribute to the critical intersection of AI and DevSecOps by presenting a comprehensive landscape of AI-driven security techniques applicable to DevOps and identifying avenues for enhancing security, trust, and efficiency in software development processes. We analyzed 99 research papers spanning from 2017 to 2023. Specifically, we address two key research questions (RQs). In RQ1, we identified 12 security tasks associated with the DevOps process and reviewed existing AI-driven security approaches. In RQ2, we discovered 15 challenges encountered by existing AI-driven security approaches and derived future research opportunities. Drawing insights from our findings, we discussed the state-of-the-art AI-driven security approaches, highlighted challenges in existing research, and proposed avenues for future opportunities.
Navigating Fairness: Practitioners' Understanding, Challenges, and Strategies in AI/ML Development
Mar 21, 2024
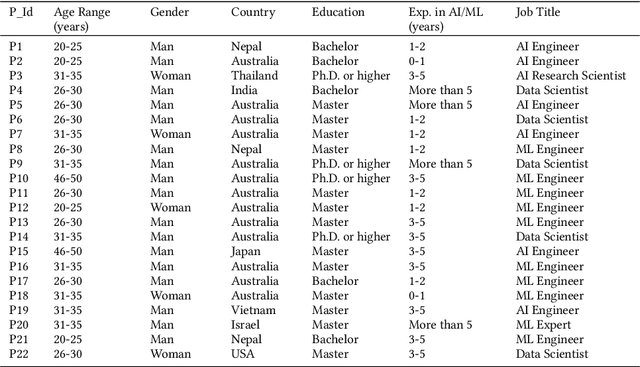
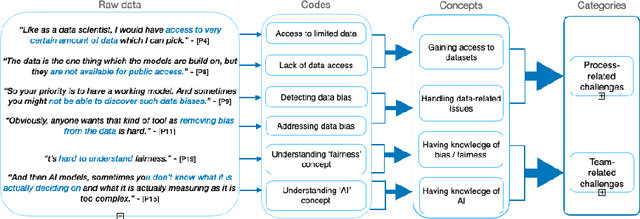

The rise in the use of AI/ML applications across industries has sparked more discussions about the fairness of AI/ML in recent times. While prior research on the fairness of AI/ML exists, there is a lack of empirical studies focused on understanding the views and experiences of AI practitioners in developing a fair AI/ML. Understanding AI practitioners' views and experiences on the fairness of AI/ML is important because they are directly involved in its development and deployment and their insights can offer valuable real-world perspectives on the challenges associated with ensuring fairness in AI/ML. We conducted semi-structured interviews with 22 AI practitioners to investigate their understanding of what a 'fair AI/ML' is, the challenges they face in developing a fair AI/ML, the consequences of developing an unfair AI/ML, and the strategies they employ to ensure AI/ML fairness. We developed a framework showcasing the relationship between AI practitioners' understanding of 'fair AI/ML' and (i) their challenges in its development, (ii) the consequences of developing an unfair AI/ML, and (iii) strategies used to ensure AI/ML fairness. Additionally, we also identify areas for further investigation and offer recommendations to aid AI practitioners and AI companies in navigating fairness.
Practitioners' Challenges and Perceptions of CI Build Failure Predictions at Atlassian
Feb 15, 2024



Continuous Integration (CI) build failures could significantly impact the software development process and teams, such as delaying the release of new features and reducing developers' productivity. In this work, we report on an empirical study that investigates CI build failures throughout product development at Atlassian. Our quantitative analysis found that the repository dimension is the key factor influencing CI build failures. In addition, our qualitative survey revealed that Atlassian developers perceive CI build failures as challenging issues in practice. Furthermore, we found that the CI build prediction can not only provide proactive insight into CI build failures but also facilitate the team's decision-making. Our study sheds light on the challenges and expectations involved in integrating CI build prediction tools into the Bitbucket environment, providing valuable insights for enhancing CI processes.
Pitfalls in Language Models for Code Intelligence: A Taxonomy and Survey
Oct 27, 2023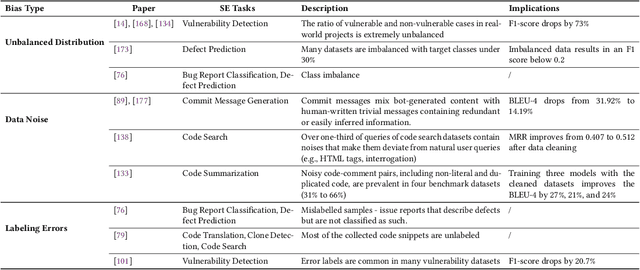
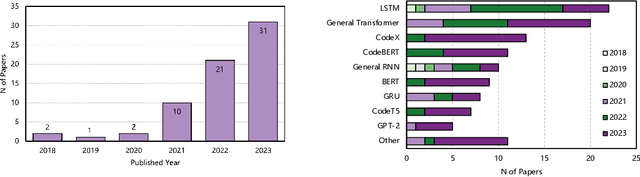
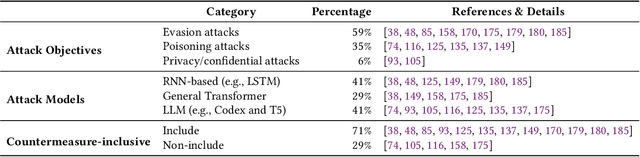

Modern language models (LMs) have been successfully employed in source code generation and understanding, leading to a significant increase in research focused on learning-based code intelligence, such as automated bug repair, and test case generation. Despite their great potential, language models for code intelligence (LM4Code) are susceptible to potential pitfalls, which hinder realistic performance and further impact their reliability and applicability in real-world deployment. Such challenges drive the need for a comprehensive understanding - not just identifying these issues but delving into their possible implications and existing solutions to build more reliable language models tailored to code intelligence. Based on a well-defined systematic research approach, we conducted an extensive literature review to uncover the pitfalls inherent in LM4Code. Finally, 67 primary studies from top-tier venues have been identified. After carefully examining these studies, we designed a taxonomy of pitfalls in LM4Code research and conducted a systematic study to summarize the issues, implications, current solutions, and challenges of different pitfalls for LM4Code systems. We developed a comprehensive classification scheme that dissects pitfalls across four crucial aspects: data collection and labeling, system design and learning, performance evaluation, and deployment and maintenance. Through this study, we aim to provide a roadmap for researchers and practitioners, facilitating their understanding and utilization of LM4Code in reliable and trustworthy ways.
Ethics in the Age of AI: An Analysis of AI Practitioners' Awareness and Challenges
Jul 14, 2023



Ethics in AI has become a debated topic of public and expert discourse in recent years. But what do people who build AI - AI practitioners - have to say about their understanding of AI ethics and the challenges associated with incorporating it in the AI-based systems they develop? Understanding AI practitioners' views on AI ethics is important as they are the ones closest to the AI systems and can bring about changes and improvements. We conducted a survey aimed at understanding AI practitioners' awareness of AI ethics and their challenges in incorporating ethics. Based on 100 AI practitioners' responses, our findings indicate that majority of AI practitioners had a reasonable familiarity with the concept of AI ethics, primarily due to workplace rules and policies. Privacy protection and security was the ethical principle that majority of them were aware of. Formal education/training was considered somewhat helpful in preparing practitioners to incorporate AI ethics. The challenges that AI practitioners faced in the development of ethical AI-based systems included (i) general challenges, (ii) technology-related challenges and (iii) human-related challenges. We also identified areas needing further investigation and provided recommendations to assist AI practitioners and companies in incorporating ethics into AI development.
Learning to Quantize Vulnerability Patterns and Match to Locate Statement-Level Vulnerabilities
May 26, 2023



Deep learning (DL) models have become increasingly popular in identifying software vulnerabilities. Prior studies found that vulnerabilities across different vulnerable programs may exhibit similar vulnerable scopes, implicitly forming discernible vulnerability patterns that can be learned by DL models through supervised training. However, vulnerable scopes still manifest in various spatial locations and formats within a program, posing challenges for models to accurately identify vulnerable statements. Despite this challenge, state-of-the-art vulnerability detection approaches fail to exploit the vulnerability patterns that arise in vulnerable programs. To take full advantage of vulnerability patterns and unleash the ability of DL models, we propose a novel vulnerability-matching approach in this paper, drawing inspiration from program analysis tools that locate vulnerabilities based on pre-defined patterns. Specifically, a vulnerability codebook is learned, which consists of quantized vectors representing various vulnerability patterns. During inference, the codebook is iterated to match all learned patterns and predict the presence of potential vulnerabilities within a given program. Our approach was extensively evaluated on a real-world dataset comprising more than 188,000 C/C++ functions. The evaluation results show that our approach achieves an F1-score of 94% (6% higher than the previous best) and 82% (19% higher than the previous best) for function and statement-level vulnerability identification, respectively. These substantial enhancements highlight the effectiveness of our approach to identifying vulnerabilities. The training code and pre-trained models are available at https://github.com/optimatch/optimatch.