 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal-HM: Restoring Physical Generative Logic in Multimodal Anomaly Detection via Hierarchical Modulation
Dec 25, 2025Multimodal Unsupervised Anomaly Detection (UAD) is critical for quality assurance in smart manufacturing, particularly in complex processes like robotic welding. However, existing methods often suffer from causal blindness, treating process modalities (e.g., real-time video, audio, and sensors) and result modalities (e.g., post-weld images) as equal feature sources, thereby ignoring the inherent physical generative logic. Furthermore, the heterogeneity gap between high-dimensional visual data and low-dimensional sensor signals frequently leads to critical process context being drowned out. In this paper, we propose Causal-HM, a unified multimodal UAD framework that explicitly models the physical Process to Result dependency. Specifically, our framework incorporates two key innovations: a Sensor-Guided CHM Modulation mechanism that utilizes low-dimensional sensor signals as context to guide high-dimensional audio-visual feature extraction , and a Causal-Hierarchical Architecture that enforces a unidirectional generative mapping to identify anomalies that violate physical consistency. Extensive experiments on our newly constructed Weld-4M benchmark across four modalities demonstrate that Causal-HM achieves a state-of-the-art (SOTA) I-AUROC of 90.7%. Code will be released after the paper is accepted.
LaQual: A Novel Framework for Automated Evaluation of LLM App Quality
Aug 26, 2025LLM app stores are quickly emerging as platforms that gather a wide range of intelligent applications based on LLMs, giving users many choices for content creation, coding support, education, and more. However, the current methods for ranking and recommending apps in these stores mostly rely on static metrics like user activity and favorites, which makes it hard for users to efficiently find high-quality apps. To address these challenges, we propose LaQual, an automated framework for evaluating the quality of LLM apps. LaQual consists of three main stages: first, it labels and classifies LLM apps in a hierarchical way to accurately match them to different scenarios; second, it uses static indicators, such as time-weighted user engagement and functional capability metrics, to filter out low-quality apps; and third, it conducts a dynamic, scenario-adaptive evaluation, where the LLM itself generates scenario-specific evaluation metrics, scoring rules, and tasks for a thorough quality assessment. Experiments on a popular LLM app store show that LaQual is effective. Its automated scores are highly consistent with human judgments (with Spearman's rho of 0.62 and p=0.006 in legal consulting, and rho of 0.60 and p=0.009 in travel planning). By effectively screening, LaQual can reduce the pool of candidate LLM apps by 66.7% to 81.3%. User studies further confirm that LaQual significantly outperforms baseline systems in decision confidence, comparison efficiency (with average scores of 5.45 compared to 3.30), and the perceived value of its evaluation reports (4.75 versus 2.25). Overall, these results demonstrate that LaQual offers a scalable, objective, and user-centered solution for finding and recommending high-quality LLM apps in real-world use cases.
From Assistants to Adversaries: Exploring the Security Risks of Mobile LLM Agents
May 19, 2025
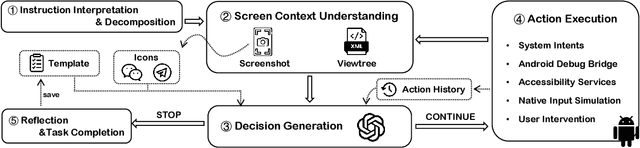
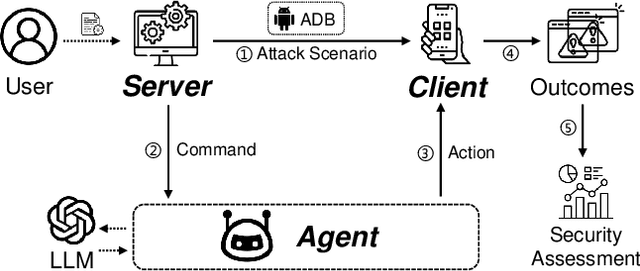

The growing adoption of large language models (LLMs) has led to a new paradigm in mobile computing--LLM-powered mobile AI agents--capable of decomposing and automating complex tasks directly on smartphones. However, the security implications of these agents remain largely unexplored. In this paper, we present the first comprehensive security analysis of mobile LLM agents, encompassing three representative categories: System-level AI Agents developed by original equipment manufacturers (e.g., YOYO Assistant), Third-party Universal Agents (e.g., Zhipu AI AutoGLM), and Emerging Agent Frameworks (e.g., Alibaba Mobile Agent). We begin by analyzing the general workflow of mobile agents and identifying security threats across three core capability dimensions: language-based reasoning, GUI-based interaction, and system-level execution. Our analysis reveals 11 distinct attack surfaces, all rooted in the unique capabilities and interaction patterns of mobile LLM agents, and spanning their entire operational lifecycle. To investigate these threats in practice, we introduce AgentScan, a semi-automated security analysis framework that systematically evaluates mobile LLM agents across all 11 attack scenarios. Applying AgentScan to nine widely deployed agents, we uncover a concerning trend: every agent is vulnerable to targeted attacks. In the most severe cases, agents exhibit vulnerabilities across eight distinct attack vectors. These attacks can cause behavioral deviations, privacy leakage, or even full execution hijacking. Based on these findings, we propose a set of defensive design principles and practical recommendations for building secure mobile LLM agents. Our disclosures have received positive feedback from two major device vendors. Overall, this work highlights the urgent need for standardized security practices in the fast-evolving landscape of LLM-driven mobile automation.
Unveiling the Landscape of LLM Deployment in the Wild: An Empirical Study
May 05, 2025
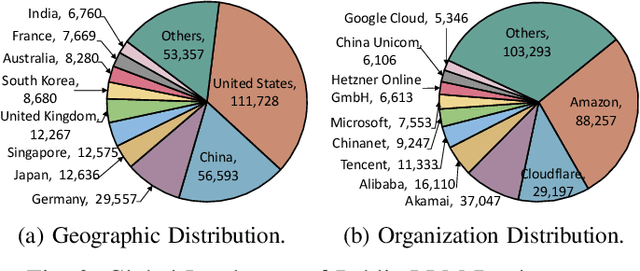


Background: Large language models (LLMs) are increasingly deployed via open-source and commercial frameworks, enabling individuals and organizations to self-host advanced AI capabilities. However, insecure defaults and misconfigurations often expose LLM services to the public Internet, posing significant security and system engineering risks. Aims: This study aims to unveil the current landscape of public-facing LLM deployments in the wild through a large-scale empirical study, focusing on service prevalence, exposure characteristics, systemic vulnerabilities, and associated risks. Method: We conducted an Internet-wide measurement to identify public-facing LLM deployments across 15 frameworks, discovering 320,102 services. We extracted 158 unique API endpoints, grouped into 12 functional categories based on capabilities and security risks. We further analyzed configurations, authentication practices, and geographic distributions, revealing deployment trends and systemic issues in real-world LLM system engineering. Results: Our study shows that public LLM deployments are rapidly growing but often insecure. Among all endpoints, we observe widespread use of insecure protocols, poor TLS configurations, and unauthenticated access to critical operations. Security risks, including model disclosure, system leakage, and unauthorized access, are pervasive, highlighting the need for secure-by-default frameworks and stronger deployment practices. Conclusions: Public-facing LLM deployments suffer from widespread security and configuration flaws, exposing services to misuse, model theft, resource hijacking, and remote exploitation. Strengthening default security, deployment practices, and operational standards is critical for the growing self-hosted LLM ecosystem.
Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions
Mar 30, 2025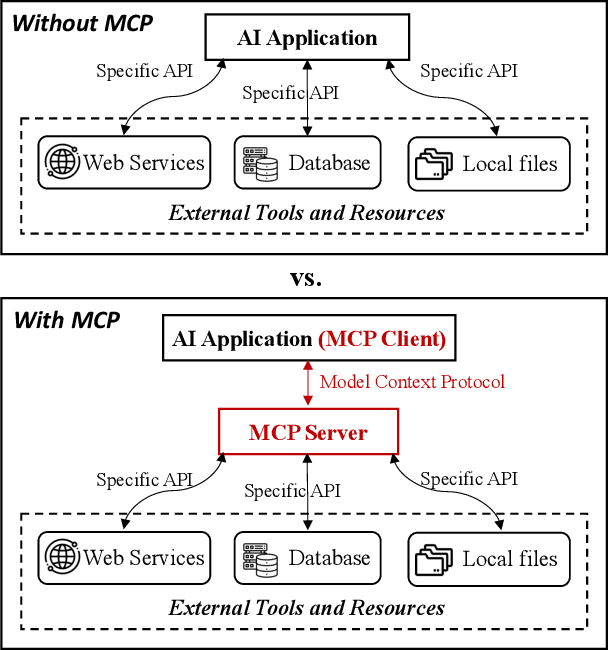
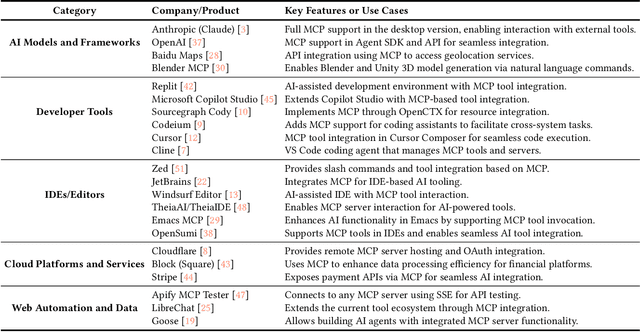
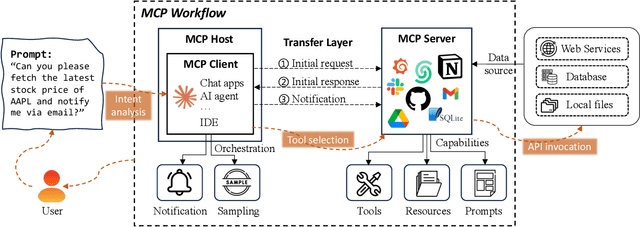
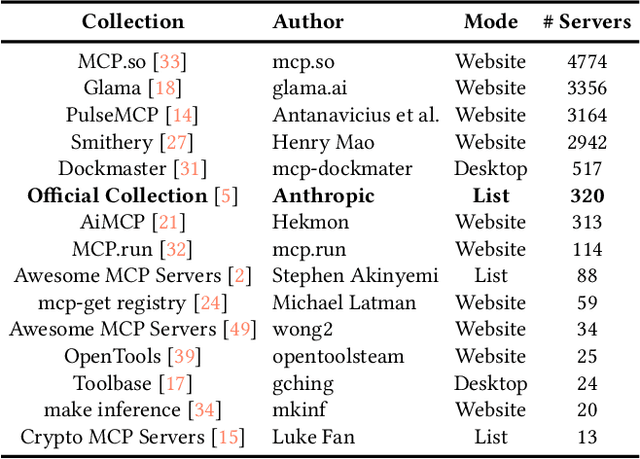
The Model Context Protocol (MCP) is a standardized interface designed to enable seamless interaction between AI models and external tools and resources, breaking down data silos and facilitating interoperability across diverse systems. This paper provides a comprehensive overview of MCP, focusing on its core components, workflow, and the lifecycle of MCP servers, which consists of three key phases: creation, operation, and update. We analyze the security and privacy risks associated with each phase and propose strategies to mitigate potential threats. The paper also examines the current MCP landscape, including its adoption by industry leaders and various use cases, as well as the tools and platforms supporting its integration. We explore future directions for MCP, highlighting the challenges and opportunities that will influence its adoption and evolution within the broader AI ecosystem. Finally, we offer recommendations for MCP stakeholders to ensure its secure and sustainable development as the AI landscape continues to evolve.
The Next Frontier of LLM Applications: Open Ecosystems and Hardware Synergy
Mar 06, 2025



Large Language Model (LLM) applications, including LLM app stores and autonomous agents, are shaping the future of AI ecosystems. However, platform silos, fragmented hardware integration, and the absence of standardized interfaces limit scalability, interoperability, and resource efficiency. While LLM app stores democratize AI, their closed ecosystems restrict modular AI reuse and cross-platform portability. Meanwhile, agent-based frameworks offer flexibility but often lack seamless integration across diverse environments. This paper envisions the future of LLM applications and proposes a three-layer decoupled architecture grounded in software engineering principles such as layered system design, service-oriented architectures, and hardware-software co-design. This architecture separates application logic, communication protocols, and hardware execution, enhancing modularity, efficiency, and cross-platform compatibility. Beyond architecture, we highlight key security and privacy challenges for safe, scalable AI deployment and outline research directions in software and security engineering. This vision aims to foster open, secure, and interoperable LLM ecosystems, guiding future advancements in AI applications.
LLM App Squatting and Cloning
Nov 12, 2024Impersonation tactics, such as app squatting and app cloning, have posed longstanding challenges in mobile app stores, where malicious actors exploit the names and reputations of popular apps to deceive users. With the rapid growth of Large Language Model (LLM) stores like GPT Store and FlowGPT, these issues have similarly surfaced, threatening the integrity of the LLM app ecosystem. In this study, we present the first large-scale analysis of LLM app squatting and cloning using our custom-built tool, LLMappCrazy. LLMappCrazy covers 14 squatting generation techniques and integrates Levenshtein distance and BERT-based semantic analysis to detect cloning by analyzing app functional similarities. Using this tool, we generated variations of the top 1000 app names and found over 5,000 squatting apps in the dataset. Additionally, we observed 3,509 squatting apps and 9,575 cloning cases across six major platforms. After sampling, we find that 18.7% of the squatting apps and 4.9% of the cloning apps exhibited malicious behavior, including phishing, malware distribution, fake content dissemination, and aggressive ad injection.
PathSeeker: Exploring LLM Security Vulnerabilities with a Reinforcement Learning-Based Jailbreak Approach
Sep 21, 2024



In recent years, Large Language Models (LLMs) have gained widespread use, accompanied by increasing concerns over their security. Traditional jailbreak attacks rely on internal model details or have limitations when exploring the unsafe behavior of the victim model, limiting their generalizability. In this paper, we introduce PathSeeker, a novel black-box jailbreak method inspired by the concept of escaping a security maze. This work is inspired by the game of rats escaping a maze. We think that each LLM has its unique "security maze", and attackers attempt to find the exit learning from the received feedback and their accumulated experience to compromise the target LLM's security defences. Our approach leverages multi-agent reinforcement learning, where smaller models collaborate to guide the main LLM in performing mutation operations to achieve the attack objectives. By progressively modifying inputs based on the model's feedback, our system induces richer, harmful responses. During our manual attempts to perform jailbreak attacks, we found that the vocabulary of the response of the target model gradually became richer and eventually produced harmful responses. Based on the observation, we also introduce a reward mechanism that exploits the expansion of vocabulary richness in LLM responses to weaken security constraints. Our method outperforms five state-of-the-art attack techniques when tested across 13 commercial and open-source LLMs, achieving high attack success rates, especially in strongly aligned commercial models like GPT-4o-mini, Claude-3.5, and GLM-4-air with strong safety alignment. This study aims to improve the understanding of LLM security vulnerabilities and we hope that this sturdy can contribute to the development of more robust defenses.
VoiceWukong: Benchmarking Deepfake Voice Detection
Sep 10, 2024
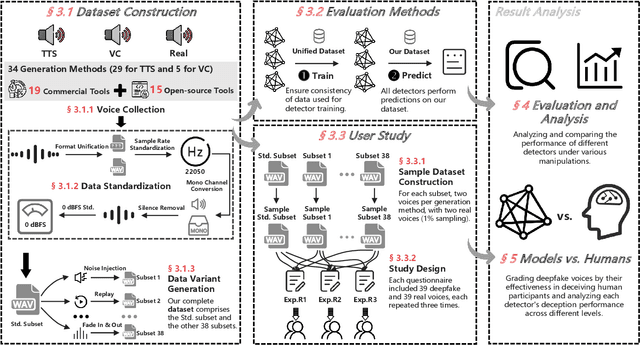
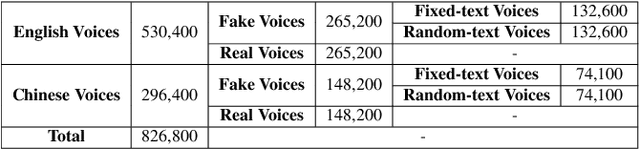
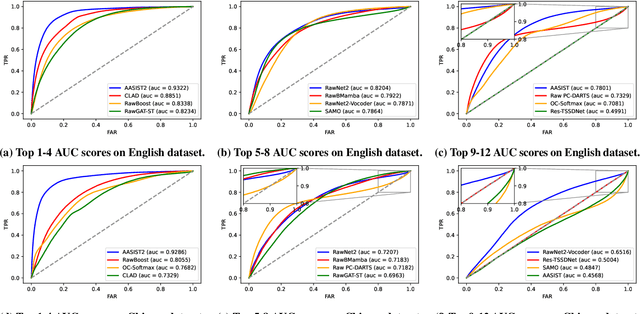
With the rapid advancement of technologies like text-to-speech (TTS) and voice conversion (VC), detecting deepfake voices has become increasingly crucial. However, both academia and industry lack a comprehensive and intuitive benchmark for evaluating detectors. Existing datasets are limited in language diversity and lack many manipulations encountered in real-world production environments. To fill this gap, we propose VoiceWukong, a benchmark designed to evaluate the performance of deepfake voice detectors. To build the dataset, we first collected deepfake voices generated by 19 advanced and widely recognized commercial tools and 15 open-source tools. We then created 38 data variants covering six types of manipulations, constructing the evaluation dataset for deepfake voice detection. VoiceWukong thus includes 265,200 English and 148,200 Chinese deepfake voice samples. Using VoiceWukong, we evaluated 12 state-of-the-art detectors. AASIST2 achieved the best equal error rate (EER) of 13.50%, while all others exceeded 20%. Our findings reveal that these detectors face significant challenges in real-world applications, with dramatically declining performance. In addition, we conducted a user study with more than 300 participants. The results are compared with the performance of the 12 detectors and a multimodel large language model (MLLM), i.e., Qwen2-Audio, where different detectors and humans exhibit varying identification capabilities for deepfake voices at different deception levels, while the LALM demonstrates no detection ability at all. Furthermore, we provide a leaderboard for deepfake voice detection, publicly available at {https://voicewukong.github.io}.
On the (In)Security of LLM App Stores
Jul 11, 2024LLM app stores have seen rapid growth, leading to the proliferation of numerous custom LLM apps. However, this expansion raises security concerns. In this study, we propose a three-layer concern framework to identify the potential security risks of LLM apps, i.e., LLM apps with abusive potential, LLM apps with malicious intent, and LLM apps with exploitable vulnerabilities. Over five months, we collected 786,036 LLM apps from six major app stores: GPT Store, FlowGPT, Poe, Coze, Cici, and Character.AI. Our research integrates static and dynamic analysis, the development of a large-scale toxic word dictionary (i.e., ToxicDict) comprising over 31,783 entries, and automated monitoring tools to identify and mitigate threats. We uncovered that 15,146 apps had misleading descriptions, 1,366 collected sensitive personal information against their privacy policies, and 15,996 generated harmful content such as hate speech, self-harm, extremism, etc. Additionally, we evaluated the potential for LLM apps to facilitate malicious activities, finding that 616 apps could be used for malware generation, phishing, etc. Our findings highlight the urgent need for robust regulatory frameworks and enhanced enforcement mechanisms.