 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaQual: A Novel Framework for Automated Evaluation of LLM App Quality
Aug 26, 2025LLM app stores are quickly emerging as platforms that gather a wide range of intelligent applications based on LLMs, giving users many choices for content creation, coding support, education, and more. However, the current methods for ranking and recommending apps in these stores mostly rely on static metrics like user activity and favorites, which makes it hard for users to efficiently find high-quality apps. To address these challenges, we propose LaQual, an automated framework for evaluating the quality of LLM apps. LaQual consists of three main stages: first, it labels and classifies LLM apps in a hierarchical way to accurately match them to different scenarios; second, it uses static indicators, such as time-weighted user engagement and functional capability metrics, to filter out low-quality apps; and third, it conducts a dynamic, scenario-adaptive evaluation, where the LLM itself generates scenario-specific evaluation metrics, scoring rules, and tasks for a thorough quality assessment. Experiments on a popular LLM app store show that LaQual is effective. Its automated scores are highly consistent with human judgments (with Spearman's rho of 0.62 and p=0.006 in legal consulting, and rho of 0.60 and p=0.009 in travel planning). By effectively screening, LaQual can reduce the pool of candidate LLM apps by 66.7% to 81.3%. User studies further confirm that LaQual significantly outperforms baseline systems in decision confidence, comparison efficiency (with average scores of 5.45 compared to 3.30), and the perceived value of its evaluation reports (4.75 versus 2.25). Overall, these results demonstrate that LaQual offers a scalable, objective, and user-centered solution for finding and recommending high-quality LLM apps in real-world use cases.
Unveiling the Landscape of LLM Deployment in the Wild: An Empirical Study
May 05, 2025
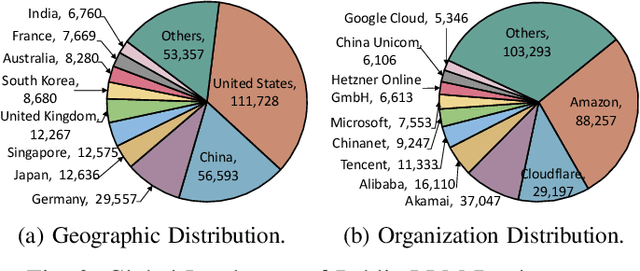


Background: Large language models (LLMs) are increasingly deployed via open-source and commercial frameworks, enabling individuals and organizations to self-host advanced AI capabilities. However, insecure defaults and misconfigurations often expose LLM services to the public Internet, posing significant security and system engineering risks. Aims: This study aims to unveil the current landscape of public-facing LLM deployments in the wild through a large-scale empirical study, focusing on service prevalence, exposure characteristics, systemic vulnerabilities, and associated risks. Method: We conducted an Internet-wide measurement to identify public-facing LLM deployments across 15 frameworks, discovering 320,102 services. We extracted 158 unique API endpoints, grouped into 12 functional categories based on capabilities and security risks. We further analyzed configurations, authentication practices, and geographic distributions, revealing deployment trends and systemic issues in real-world LLM system engineering. Results: Our study shows that public LLM deployments are rapidly growing but often insecure. Among all endpoints, we observe widespread use of insecure protocols, poor TLS configurations, and unauthenticated access to critical operations. Security risks, including model disclosure, system leakage, and unauthorized access, are pervasive, highlighting the need for secure-by-default frameworks and stronger deployment practices. Conclusions: Public-facing LLM deployments suffer from widespread security and configuration flaws, exposing services to misuse, model theft, resource hijacking, and remote exploitation. Strengthening default security, deployment practices, and operational standards is critical for the growing self-hosted LLM ecosystem.
Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions
Mar 30, 2025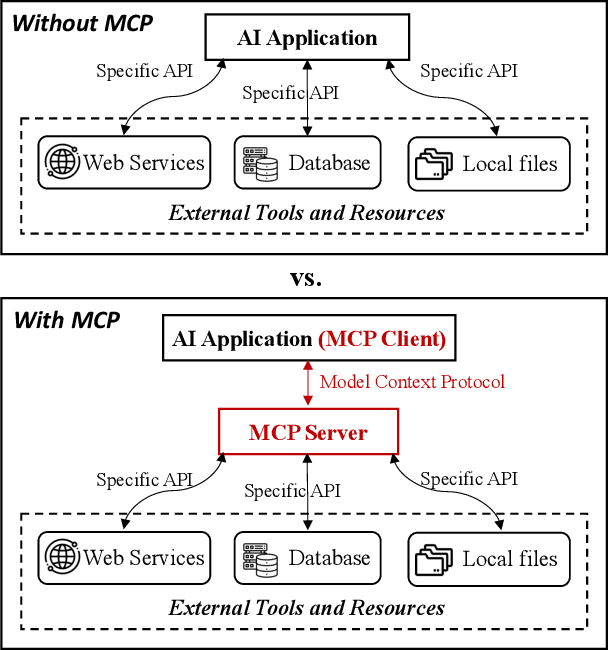
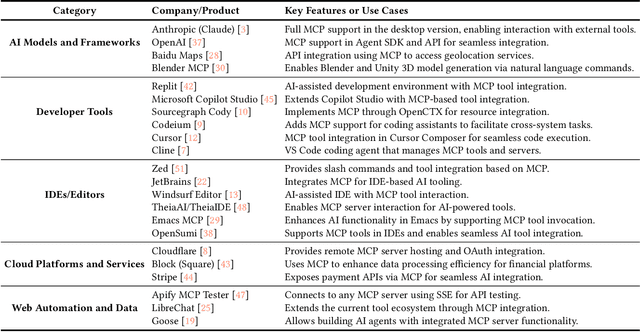
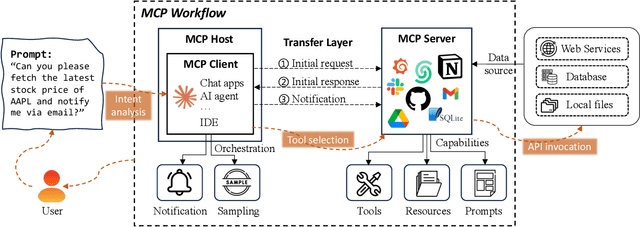
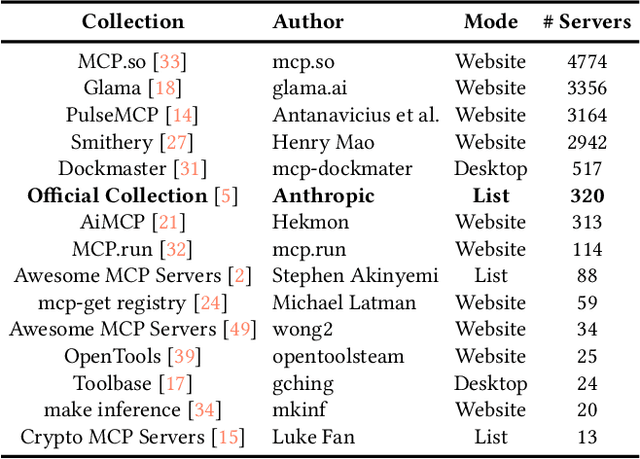
The Model Context Protocol (MCP) is a standardized interface designed to enable seamless interaction between AI models and external tools and resources, breaking down data silos and facilitating interoperability across diverse systems. This paper provides a comprehensive overview of MCP, focusing on its core components, workflow, and the lifecycle of MCP servers, which consists of three key phases: creation, operation, and update. We analyze the security and privacy risks associated with each phase and propose strategies to mitigate potential threats. The paper also examines the current MCP landscape, including its adoption by industry leaders and various use cases, as well as the tools and platforms supporting its integration. We explore future directions for MCP, highlighting the challenges and opportunities that will influence its adoption and evolution within the broader AI ecosystem. Finally, we offer recommendations for MCP stakeholders to ensure its secure and sustainable development as the AI landscape continues to evolve.
The Next Frontier of LLM Applications: Open Ecosystems and Hardware Synergy
Mar 06, 2025



Large Language Model (LLM) applications, including LLM app stores and autonomous agents, are shaping the future of AI ecosystems. However, platform silos, fragmented hardware integration, and the absence of standardized interfaces limit scalability, interoperability, and resource efficiency. While LLM app stores democratize AI, their closed ecosystems restrict modular AI reuse and cross-platform portability. Meanwhile, agent-based frameworks offer flexibility but often lack seamless integration across diverse environments. This paper envisions the future of LLM applications and proposes a three-layer decoupled architecture grounded in software engineering principles such as layered system design, service-oriented architectures, and hardware-software co-design. This architecture separates application logic, communication protocols, and hardware execution, enhancing modularity, efficiency, and cross-platform compatibility. Beyond architecture, we highlight key security and privacy challenges for safe, scalable AI deployment and outline research directions in software and security engineering. This vision aims to foster open, secure, and interoperable LLM ecosystems, guiding future advancements in AI applications.
LLM App Squatting and Cloning
Nov 12, 2024Impersonation tactics, such as app squatting and app cloning, have posed longstanding challenges in mobile app stores, where malicious actors exploit the names and reputations of popular apps to deceive users. With the rapid growth of Large Language Model (LLM) stores like GPT Store and FlowGPT, these issues have similarly surfaced, threatening the integrity of the LLM app ecosystem. In this study, we present the first large-scale analysis of LLM app squatting and cloning using our custom-built tool, LLMappCrazy. LLMappCrazy covers 14 squatting generation techniques and integrates Levenshtein distance and BERT-based semantic analysis to detect cloning by analyzing app functional similarities. Using this tool, we generated variations of the top 1000 app names and found over 5,000 squatting apps in the dataset. Additionally, we observed 3,509 squatting apps and 9,575 cloning cases across six major platforms. After sampling, we find that 18.7% of the squatting apps and 4.9% of the cloning apps exhibited malicious behavior, including phishing, malware distribution, fake content dissemination, and aggressive ad injection.
On the (In)Security of LLM App Stores
Jul 11, 2024LLM app stores have seen rapid growth, leading to the proliferation of numerous custom LLM apps. However, this expansion raises security concerns. In this study, we propose a three-layer concern framework to identify the potential security risks of LLM apps, i.e., LLM apps with abusive potential, LLM apps with malicious intent, and LLM apps with exploitable vulnerabilities. Over five months, we collected 786,036 LLM apps from six major app stores: GPT Store, FlowGPT, Poe, Coze, Cici, and Character.AI. Our research integrates static and dynamic analysis, the development of a large-scale toxic word dictionary (i.e., ToxicDict) comprising over 31,783 entries, and automated monitoring tools to identify and mitigate threats. We uncovered that 15,146 apps had misleading descriptions, 1,366 collected sensitive personal information against their privacy policies, and 15,996 generated harmful content such as hate speech, self-harm, extremism, etc. Additionally, we evaluated the potential for LLM apps to facilitate malicious activities, finding that 616 apps could be used for malware generation, phishing, etc. Our findings highlight the urgent need for robust regulatory frameworks and enhanced enforcement mechanisms.
GPT Store Mining and Analysis
May 16, 2024As a pivotal extension of the renowned ChatGPT, the GPT Store serves as a dynamic marketplace for various Generative Pre-trained Transformer (GPT) models, shaping the frontier of conversational AI. This paper presents an in-depth measurement study of the GPT Store, with a focus on the categorization of GPTs by topic, factors influencing GPT popularity, and the potential security risks. Our investigation starts with assessing the categorization of GPTs in the GPT Store, analyzing how they are organized by topics, and evaluating the effectiveness of the classification system. We then examine the factors that affect the popularity of specific GPTs, looking into user preferences, algorithmic influences, and market trends. Finally, the study delves into the security risks of the GPT Store, identifying potential threats and evaluating the robustness of existing security measures. This study offers a detailed overview of the GPT Store's current state, shedding light on its operational dynamics and user interaction patterns. Our findings aim to enhance understanding of the GPT ecosystem, providing valuable insights for future research, development, and policy-making in generative AI.
Large Language Models for Software Engineering: A Systematic Literature Review
Sep 12, 2023
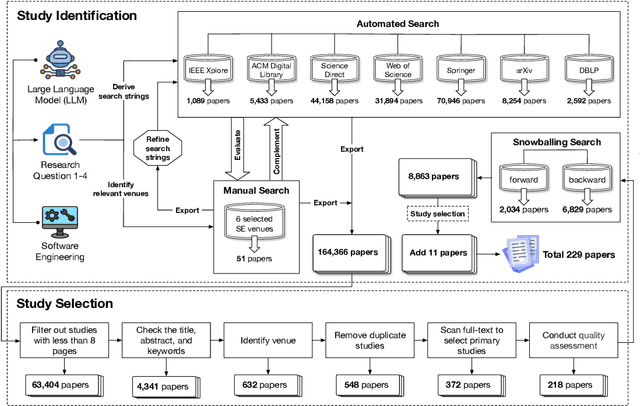

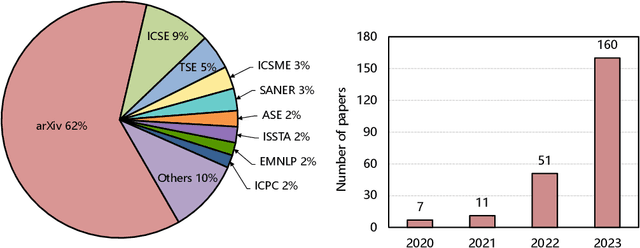
Large Language Models (LLMs) have significantly impacted numerous domains, including Software Engineering (SE). Many recent publications have explored LLMs applied to various SE tasks. Nevertheless, a comprehensive understanding of the application, effects, and possible limitations of LLMs on SE is still in its early stages. To bridge this gap, we conducted a systematic literature review on LLM4SE, with a particular focus on understanding how LLMs can be exploited to optimize processes and outcomes. We collect and analyze 229 research papers from 2017 to 2023 to answer four key research questions (RQs). In RQ1, we categorize different LLMs that have been employed in SE tasks, characterizing their distinctive features and uses. In RQ2, we analyze the methods used in data collection, preprocessing, and application highlighting the role of well-curated datasets for successful LLM for SE implementation. RQ3 investigates the strategies employed to optimize and evaluate the performance of LLMs in SE. Finally, RQ4 examines the specific SE tasks where LLMs have shown success to date, illustrating their practical contributions to the field. From the answers to these RQs, we discuss the current state-of-the-art and trends, identifying gaps in existing research, and flagging promising areas for future study.