 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSG: Logit-Balanced Vocabulary Partitioning for LLM Watermarking
Apr 24, 2026Watermarking has emerged as a promising technique for tracing the authorship of content generated by large language models (LLMs). Among existing approaches, the KGW scheme is particularly attractive due to its versatility, efficiency, and effectiveness in natural language generation. However, KGW's effectiveness degrades significantly under low-entropy settings such as code generation and mathematical reasoning. A crucial step in the KGW method is random vocabulary partitioning, which enables adjustments to token selection based on specific preferences. Our study revealed that the next-token probability distribution plays an critical role in determining how much, or even whether, we can modify token selection and, consequently, the effectiveness of watermarking. We refer to this characteristic, associated with the probability distribution of each token prediction, as \emph{watermark strength.} In cases of random vocabulary partitioning, the lower bound of watermark strength is dictated by the next-token probability distribution. However, we found that, by redesigning the vocabulary partitioning algorithm, we can potentially raise this lower bound. In this paper, we propose SSG (\textbf{S}ort-then-\textbf{S}plit by \textbf{G}roups), a method that partitions the vocabulary into two logit-balanced subsets. This design lifts the lower bound of watermark strength for each token prediction, thereby improving watermark detectability. Experiments on code generation and mathematical reasoning datasets demonstrate the effectiveness of SSG.
Towards an Appropriate Level of Reliance on AI: A Preliminary Reliance-Control Framework for AI in Software Engineering
Apr 12, 2026How software developers interact with Artificial Intelligence (AI)-powered tools, including Large Language Models (LLMs), plays a vital role in how these AI-powered tools impact them. While overreliance on AI may lead to long-term negative consequences (e.g., atrophy of critical thinking skills); underreliance might deprive software developers of potential gains in productivity and quality. Based on twenty-two interviews with software developers on using LLMs for software development, we propose a preliminary reliance-control framework where the level of control can be used as a way to identify AI overreliance and underreliance. We also use it to recommend future research to further explore the different control levels supported by the current and emergent LLM-driven tools. Our paper contributes to the emerging discourse on AI overreliance and provides an understanding of the appropriate degree of reliance as essential to developers making the most of these powerful technologies. Our findings can help practitioners, educators, and policymakers promote responsible and effective use of AI tools.
Towards Explainable Stakeholder-Aware Requirements Prioritisation in Aged-Care Digital Health
Mar 31, 2026Requirements engineering for aged-care digital health must account for human aspects, because requirement priorities are shaped not only by technical functionality but also by stakeholders' health conditions, socioeconomics, and lived experience. Knowing which human aspects matter most, and for whom, is critical for inclusive and evidence-based requirements prioritisation. Yet in practice, while some studies have examined human aspects in RE, they have largely relied on expert judgement or model-driven analysis rather than large-scale user studies with meaningful human-in-the-loop validation to determine which aspects matter most and why. To address this gap, we conducted a mixed-methods study with 103 older adults, 105 developers, and 41 caregivers. We first applied an explainable machine learning to identify the human aspects most strongly associated with requirement priorities across 8 aged-care digital health themes, and then conducted 12 semi-structured interviews to validate and interpret the quantitative patterns. The results identify the key human aspects shaping requirement priorities, reveal their directional effects, and expose substantial misalignment across stakeholder groups. Together, these findings show that human-centric requirements analysis should engage stakeholder groups explicitly rather than collapsing their perspectives into a single aggregate view. This paper contributes an identification of the key human aspects driving requirement priorities in aged-care digital health and an explainable, human-centric RE framework that combines ML-derived importance rankings with qualitative validation to surface the stakeholder misalignments that inclusive requirements engineering must address.
Walking the Tightrope of LLMs for Software Development: A Practitioners' Perspective
Nov 09, 2025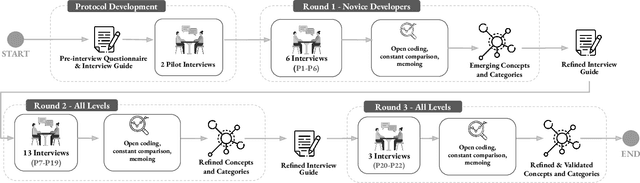

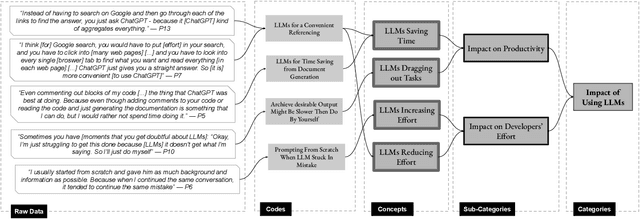
Background: Large Language Models emerged with the potential of provoking a revolution in software development (e.g., automating processes, workforce transformation). Although studies have started to investigate the perceived impact of LLMs for software development, there is a need for empirical studies to comprehend how to balance forward and backward effects of using LLMs. Objective: We investigated how LLMs impact software development and how to manage the impact from a software developer's perspective. Method: We conducted 22 interviews with software practitioners across 3 rounds of data collection and analysis, between October (2024) and September (2025). We employed socio-technical grounded theory (STGT) for data analysis to rigorously analyse interview participants' responses. Results: We identified the benefits (e.g., maintain software development flow, improve developers' mental model, and foster entrepreneurship) and disadvantages (e.g., negative impact on developers' personality and damage to developers' reputation) of using LLMs at individual, team, organisation, and society levels; as well as best practices on how to adopt LLMs. Conclusion: Critically, we present the trade-offs that software practitioners, teams, and organisations face in working with LLMs. Our findings are particularly useful for software team leaders and IT managers to assess the viability of LLMs within their specific context.
Junior Software Developers' Perspectives on Adopting LLMs for Software Engineering: a Systematic Literature Review
Mar 10, 2025Many studies exploring the adoption of Large Language Model-based tools for software development by junior developers have emerged in recent years. These studies have sought to understand developers' perspectives about using those tools, a fundamental pillar for successfully adopting LLM-based tools in Software Engineering. The aim of this paper is to provide an overview of junior software developers' perspectives and use of LLM-based tools for software engineering (LLM4SE). We conducted a systematic literature review (SLR) following guidelines by Kitchenham et al. on 56 primary studies, applying the definition for junior software developers as software developers with equal or less than five years of experience, including Computer Science/Software Engineering students. We found that the majority of the studies focused on comprehending the different aspects of integrating AI tools in SE. Only 8.9\% of the studies provide a clear definition for junior software developers, and there is no uniformity. Searching for relevant information is the most common task using LLM tools. ChatGPT was the most common LLM tool present in the studies (and experiments). A majority of the studies (83.9\%) report both positive and negative perceptions about the impact of adopting LLM tools. We also found and categorised advantages, challenges, and recommendations regarding LLM adoption. Our results indicate that developers are using LLMs not just for code generation, but also to improve their development skills. Critically, they are not just experiencing the benefits of adopting LLM tools, but they are also aware of at least a few LLM limitations, such as the generation of wrong suggestions, potential data leaking, and AI hallucination. Our findings offer implications for software engineering researchers, educators, and developers.
Advice for Diabetes Self-Management by ChatGPT Models: Challenges and Recommendations
Jan 14, 2025



Given their ability for advanced reasoning, extensive contextual understanding, and robust question-answering abilities, large language models have become prominent in healthcare management research. Despite adeptly handling a broad spectrum of healthcare inquiries, these models face significant challenges in delivering accurate and practical advice for chronic conditions such as diabetes. We evaluate the responses of ChatGPT versions 3.5 and 4 to diabetes patient queries, assessing their depth of medical knowledge and their capacity to deliver personalized, context-specific advice for diabetes self-management. Our findings reveal discrepancies in accuracy and embedded biases, emphasizing the models' limitations in providing tailored advice unless activated by sophisticated prompting techniques. Additionally, we observe that both models often provide advice without seeking necessary clarification, a practice that can result in potentially dangerous advice. This underscores the limited practical effectiveness of these models without human oversight in clinical settings. To address these issues, we propose a commonsense evaluation layer for prompt evaluation and incorporating disease-specific external memory using an advanced Retrieval Augmented Generation technique. This approach aims to improve information quality and reduce misinformation risks, contributing to more reliable AI applications in healthcare settings. Our findings seek to influence the future direction of AI in healthcare, enhancing both the scope and quality of its integration.
RepoTransBench: A Real-World Benchmark for Repository-Level Code Translation
Dec 23, 2024



Repository-level code translation refers to translating an entire code repository from one programming language to another while preserving the functionality of the source repository. Many benchmarks have been proposed to evaluate the performance of such code translators. However, previous benchmarks mostly provide fine-grained samples, focusing at either code snippet, function, or file-level code translation. Such benchmarks do not accurately reflect real-world demands, where entire repositories often need to be translated, involving longer code length and more complex functionalities. To address this gap, we propose a new benchmark, named RepoTransBench, which is a real-world repository-level code translation benchmark with an automatically executable test suite. We conduct experiments on RepoTransBench to evaluate the translation performance of 11 advanced LLMs. We find that the Success@1 score (test success in one attempt) of the best-performing LLM is only 7.33%. To further explore the potential of LLMs for repository-level code translation, we provide LLMs with error-related feedback to perform iterative debugging and observe an average 7.09% improvement on Success@1. However, even with this improvement, the Success@1 score of the best-performing LLM is only 21%, which may not meet the need for reliable automatic repository-level code translation. Finally, we conduct a detailed error analysis and highlight current LLMs' deficiencies in repository-level code translation, which could provide a reference for further improvements.
Requirements Engineering for Older Adult Digital Health Software: A Systematic Literature Review
Nov 06, 2024Growth of the older adult population has led to an increasing interest in technology-supported aged care. However, the area has some challenges such as a lack of caregivers and limitations in understanding the emotional, social, physical, and mental well-being needs of seniors. Furthermore, there is a gap in the understanding between developers and ageing people of their requirements. Digital health can be important in supporting older adults wellbeing, emotional requirements, and social needs. Requirements Engineering (RE) is a major software engineering field, which can help to identify, elicit and prioritize the requirements of stakeholders and ensure that the systems meet standards for performance, reliability, and usability. We carried out a systematic review of the literature on RE for older adult digital health software. This was necessary to show the representatives of the current stage of understanding the needs of older adults in aged care digital health. Using established guidelines outlined by the Kitchenham method, the PRISMA and the PICO guideline, we developed a protocol, followed by the systematic exploration of eight databases. This resulted in 69 primary studies of high relevance, which were subsequently subjected to data extraction, synthesis, and reporting. We highlight key RE processes in digital health software for ageing people. It explored the utilization of technology for older user well-being and care, and the evaluations of such solutions. The review also identified key limitations found in existing primary studies that inspire future research opportunities. The results indicate that requirement gathering and understanding have a significant variation between different studies. The differences are in the quality, depth, and techniques adopted for requirement gathering and these differences are largely due to uneven adoption of RE methods.
Model-driven Engineering for Machine Learning Components: A Systematic Literature Review
Nov 01, 2023Context: Machine Learning (ML) has become widely adopted as a component in many modern software applications. Due to the large volumes of data available, organizations want to increasingly leverage their data to extract meaningful insights and enhance business profitability. ML components enable predictive capabilities, anomaly detection, recommendation, accurate image and text processing, and informed decision-making. However, developing systems with ML components is not trivial; it requires time, effort, knowledge, and expertise in ML, data processing, and software engineering. There have been several studies on the use of model-driven engineering (MDE) techniques to address these challenges when developing traditional software and cyber-physical systems. Recently, there has been a growing interest in applying MDE for systems with ML components. Objective: The goal of this study is to further explore the promising intersection of MDE with ML (MDE4ML) through a systematic literature review (SLR). Through this SLR, we wanted to analyze existing studies, including their motivations, MDE solutions, evaluation techniques, key benefits and limitations. Results: We analyzed selected studies with respect to several areas of interest and identified the following: 1) the key motivations behind using MDE4ML; 2) a variety of MDE solutions applied, such as modeling languages, model transformations, tool support, targeted ML aspects, contributions and more; 3) the evaluation techniques and metrics used; and 4) the limitations and directions for future work. We also discuss the gaps in existing literature and provide recommendations for future research. Conclusion: This SLR highlights current trends, gaps and future research directions in the field of MDE4ML, benefiting both researchers and practitioners
Large Language Models for Software Engineering: A Systematic Literature Review
Sep 12, 2023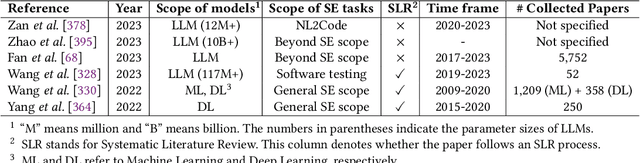
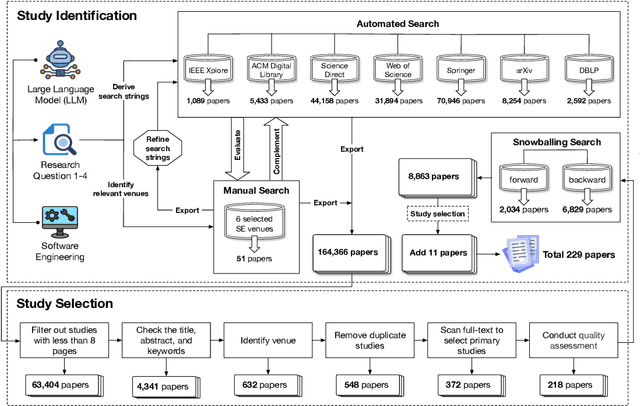

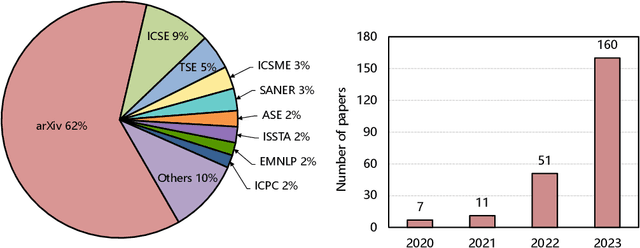
Large Language Models (LLMs) have significantly impacted numerous domains, including Software Engineering (SE). Many recent publications have explored LLMs applied to various SE tasks. Nevertheless, a comprehensive understanding of the application, effects, and possible limitations of LLMs on SE is still in its early stages. To bridge this gap, we conducted a systematic literature review on LLM4SE, with a particular focus on understanding how LLMs can be exploited to optimize processes and outcomes. We collect and analyze 229 research papers from 2017 to 2023 to answer four key research questions (RQs). In RQ1, we categorize different LLMs that have been employed in SE tasks, characterizing their distinctive features and uses. In RQ2, we analyze the methods used in data collection, preprocessing, and application highlighting the role of well-curated datasets for successful LLM for SE implementation. RQ3 investigates the strategies employed to optimize and evaluate the performance of LLMs in SE. Finally, RQ4 examines the specific SE tasks where LLMs have shown success to date, illustrating their practical contributions to the field. From the answers to these RQs, we discuss the current state-of-the-art and trends, identifying gaps in existing research, and flagging promising areas for future study.