 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Attention and Gated Shifting for Fine-Grained Event Spotting in Videos
Jul 10, 2025
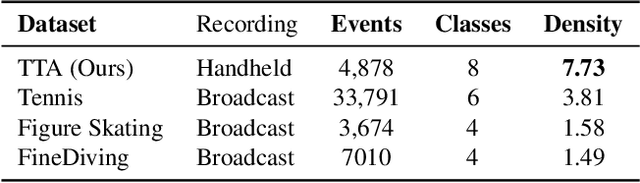
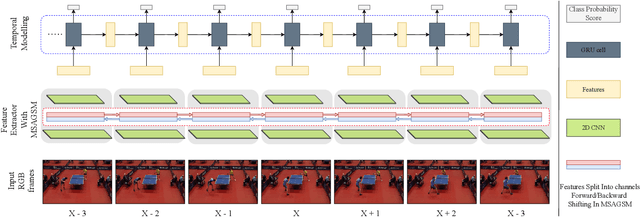
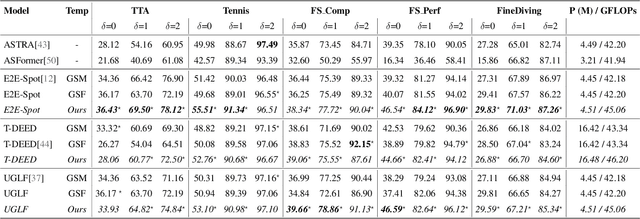
Precise Event Spotting (PES) in sports videos requires frame-level recognition of fine-grained actions from single-camera footage. Existing PES models typically incorporate lightweight temporal modules such as Gate Shift Module (GSM) or Gate Shift Fuse (GSF) to enrich 2D CNN feature extractors with temporal context. However, these modules are limited in both temporal receptive field and spatial adaptability. We propose a Multi-Scale Attention Gate Shift Module (MSAGSM) that enhances GSM with multi-scale temporal dilations and multi-head spatial attention, enabling efficient modeling of both short- and long-term dependencies while focusing on salient regions. MSAGSM is a lightweight plug-and-play module that can be easily integrated with various 2D backbones. To further advance the field, we introduce the Table Tennis Australia (TTA) dataset-the first PES benchmark for table tennis-containing over 4800 precisely annotated events. Extensive experiments across five PES benchmarks demonstrate that MSAGSM consistently improves performance with minimal overhead, setting new state-of-the-art results.
Action Spotting and Precise Event Detection in Sports: Datasets, Methods, and Challenges
May 06, 2025Video event detection has become an essential component of sports analytics, enabling automated identification of key moments and enhancing performance analysis, viewer engagement, and broadcast efficiency. Recent advancements in deep learning, particularly Convolutional Neural Networks (CNNs) and Transformers, have significantly improved accuracy and efficiency in Temporal Action Localization (TAL), Action Spotting (AS), and Precise Event Spotting (PES). This survey provides a comprehensive overview of these three key tasks, emphasizing their differences, applications, and the evolution of methodological approaches. We thoroughly review and categorize existing datasets and evaluation metrics specifically tailored for sports contexts, highlighting the strengths and limitations of each. Furthermore, we analyze state-of-the-art techniques, including multi-modal approaches that integrate audio and visual information, methods utilizing self-supervised learning and knowledge distillation, and approaches aimed at generalizing across multiple sports. Finally, we discuss critical open challenges and outline promising research directions toward developing more generalized, efficient, and robust event detection frameworks applicable to diverse sports. This survey serves as a foundation for future research on efficient, generalizable, and multi-modal sports event detection.
Enabling clustering algorithms to detect clusters of varying densities through scale-invariant data preprocessing
Jan 21, 2024In this paper, we show that preprocessing data using a variant of rank transformation called 'Average Rank over an Ensemble of Sub-samples (ARES)' makes clustering algorithms robust to data representation and enable them to detect varying density clusters. Our empirical results, obtained using three most widely used clustering algorithms-namely KMeans, DBSCAN, and DP (Density Peak)-across a wide range of real-world datasets, show that clustering after ARES transformation produces better and more consistent results.
Requirements Framework for Engineering Human-centered Artificial Intelligence-Based Software Systems
Mar 06, 2023



[Context] Artificial intelligence (AI) components used in building software solutions have substantially increased in recent years. However, many of these solutions end up focusing on technical aspects and ignore critical human-centered aspects. [Objective] Including human-centered aspects during requirements engineering (RE) when building AI-based software can help achieve more responsible, unbiased, and inclusive AI-based software solutions. [Method] In this paper, we present a new framework developed based on human-centered AI guidelines and a user survey to aid in collecting requirements for human-centered AI-based software. We provide a catalog to elicit these requirements and a conceptual model to present them visually. [Results] The framework is applied to a case study to elicit and model requirements for enhancing the quality of 360 degree~videos intended for virtual reality (VR) users. [Conclusion] We found that our proposed approach helped the project team fully understand the needs of the project to deliver. Furthermore, the framework helped to understand what requirements need to be captured at the initial stages against later stages in the engineering process of AI-based software.
A Novel Data Pre-processing Technique: Making Data Mining Robust to Different Units and Scales of Measurement
Nov 08, 2021
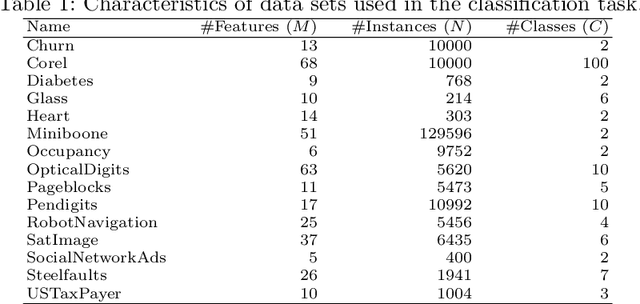


Many existing data mining algorithms use feature values directly in their model, making them sensitive to units/scales used to measure/represent data. Pre-processing of data based on rank transformation has been suggested as a potential solution to overcome this issue. However, the resulting data after pre-processing with rank transformation is uniformly distributed, which may not be very useful in many data mining applications. In this paper, we present a better and effective alternative based on ranks over multiple sub-samples of data. We call the proposed pre-processing technique as ARES | Average Rank over an Ensemble of Sub-samples. Our empirical results of widely used data mining algorithms for classification and anomaly detection in a wide range of data sets suggest that ARES results in more consistent task specific? outcome across various algorithms and data sets. In addition to this, it results in better or competitive outcome most of the time compared to the most widely used min-max normalisation and the traditional rank transformation.
* This paper is published in a special issue of the Australian Journal of Intelligent Information Processing Systems as part of the proceedings of the International Conference on Neural Information Processing (ICONIP) 2019
Improved histogram-based anomaly detector with the extended principal component features
Sep 27, 2019

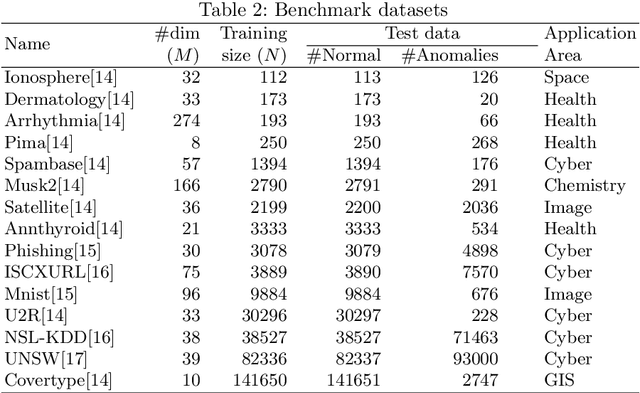
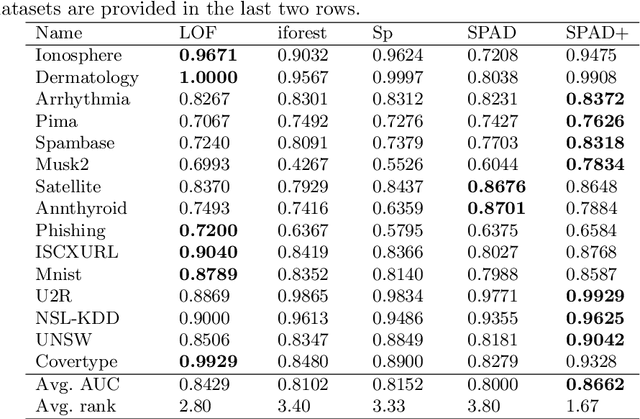
In this era of big data, databases are growing rapidly in terms of the number of records. Fast automatic detection of anomalous records in these massive databases is a challenging task. Traditional distance based anomaly detectors are not applicable in these massive datasets. Recently, a simple but extremely fast anomaly detector using one-dimensional histograms has been introduced. The anomaly score of a data instance is computed as the product of the probability mass of histograms in each dimensions where it falls into. It is shown to produce competitive results compared to many state-of-the-art methods in many datasets. Because it assumes data features are independent of each other, it results in poor detection accuracy when there is correlation between features. To address this issue, we propose to increase the feature size by adding more features based on principal components. Our results show that using the original input features together with principal components improves the detection accuracy of histogram-based anomaly detector significantly without compromising much in terms of run-time.