 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling clustering algorithms to detect clusters of varying densities through scale-invariant data preprocessing
Jan 21, 2024In this paper, we show that preprocessing data using a variant of rank transformation called 'Average Rank over an Ensemble of Sub-samples (ARES)' makes clustering algorithms robust to data representation and enable them to detect varying density clusters. Our empirical results, obtained using three most widely used clustering algorithms-namely KMeans, DBSCAN, and DP (Density Peak)-across a wide range of real-world datasets, show that clustering after ARES transformation produces better and more consistent results.
Clustering based on Point-Set Kernel
Feb 14, 2020


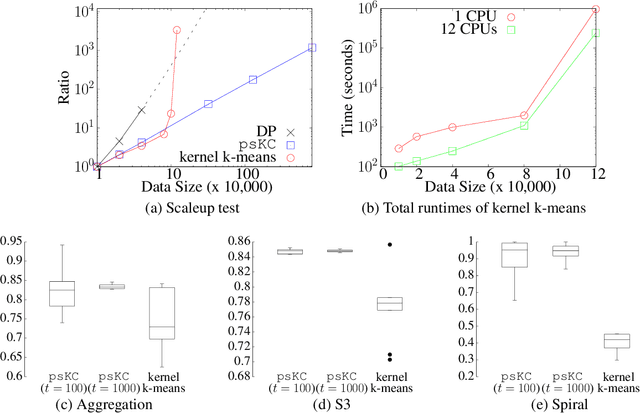
Measuring similarity between two objects is the core operation in existing cluster analyses in grouping similar objects into clusters. Cluster analyses have been applied to a number of applications, including image segmentation, social network analysis, and computational biology. This paper introduces a new similarity measure called point-set kernel which computes the similarity between an object and a sample of objects generated from an unknown distribution. The proposed clustering procedure utilizes this new measure to characterize both the typical point of every cluster and the cluster grown from the typical point. We show that the new clustering procedure is both effective and efficient such that it can deal with large scale datasets. In contrast, existing clustering algorithms are either efficient or effective; and even efficient ones have difficulty dealing with large scale datasets without special hardware. We show that the proposed algorithm is more effective and runs orders of magnitude faster than the state-of-the-art density-peak clustering and scalable kernel k-means clustering when applying to datasets of millions of data points, on commonly used computing machines.
Isolation Kernel: The X Factor in Efficient and Effective Large Scale Online Kernel Learning
Jul 02, 2019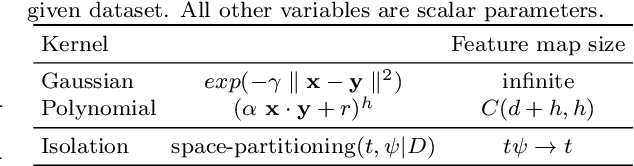
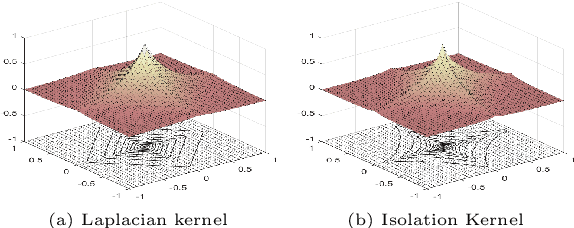
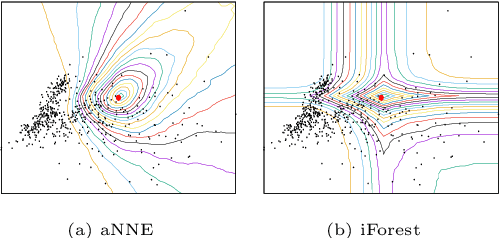

Large scale online kernel learning aims to build an efficient and scalable kernel-based predictive model incrementally from a sequence of potentially infinite data points. To achieve this aim, the method must be able to deal with a potentially infinite number of support vectors. The current state-of-the-art is unable to deal with even a moderate number of support vectors. This paper identifies the root cause of the current methods, i.e., the type of kernel used which has a feature map of infinite dimensionality. With this revelation and together with our discovery that a recently introduced Isolation Kernel has a finite feature map, to achieve the above aim of large scale online kernel learning becomes extremely simple---simply use Isolation Kernel instead of kernels having infinite feature map. We show for the first time that online kernel learning is able to deal with a potentially infinite number of support vectors.
A simple efficient density estimator that enables fast systematic search
Sep 12, 2017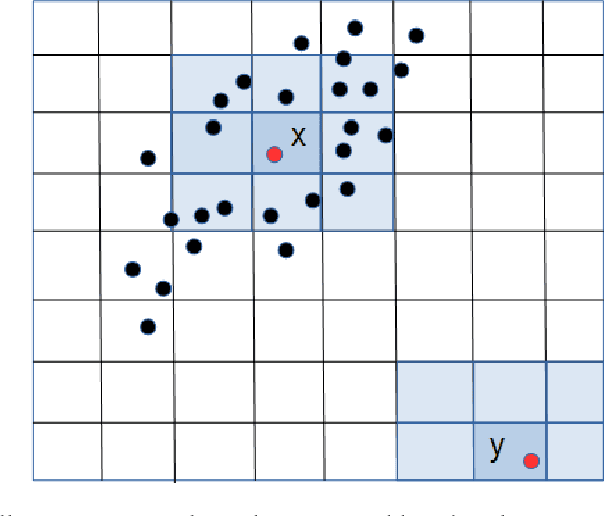


This paper introduces a simple and efficient density estimator that enables fast systematic search. To show its advantage over commonly used kernel density estimator, we apply it to outlying aspects mining. Outlying aspects mining discovers feature subsets (or subspaces) that describe how a query stand out from a given dataset. The task demands a systematic search of subspaces. We identify that existing outlying aspects miners are restricted to datasets with small data size and dimensions because they employ kernel density estimator, which is computationally expensive, for subspace assessments. We show that a recent outlying aspects miner can run orders of magnitude faster by simply replacing its density estimator with the proposed density estimator, enabling it to deal with large datasets with thousands of dimensions that would otherwise be impossible.