 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Achieve the Intended Aim of Deep Clustering Now, without Deep Learning
Feb 05, 2026Deep clustering (DC) is often quoted to have a key advantage over $k$-means clustering. Yet, this advantage is often demonstrated using image datasets only, and it is unclear whether it addresses the fundamental limitations of $k$-means clustering. Deep Embedded Clustering (DEC) learns a latent representation via an autoencoder and performs clustering based on a $k$-means-like procedure, while the optimization is conducted in an end-to-end manner. This paper investigates whether the deep-learned representation has enabled DEC to overcome the known fundamental limitations of $k$-means clustering, i.e., its inability to discover clusters of arbitrary shapes, varied sizes and densities. Our investigations on DEC have a wider implication on deep clustering methods in general. Notably, none of these methods exploit the underlying data distribution. We uncover that a non-deep learning approach achieves the intended aim of deep clustering by making use of distributional information of clusters in a dataset to effectively address these fundamental limitations.
Rethinking Divisive Hierarchical Clustering from a Distributional Perspective
Jan 27, 2026We uncover that current objective-based Divisive Hierarchical Clustering (DHC) methods produce a dendrogram that does not have three desired properties i.e., no unwarranted splitting, group similar clusters into a same subset, ground-truth correspondence. This shortcoming has their root cause in using a set-oriented bisecting assessment criterion. We show that this shortcoming can be addressed by using a distributional kernel, instead of the set-oriented criterion; and the resultant clusters achieve a new distribution-oriented objective to maximize the total similarity of all clusters (TSC). Our theoretical analysis shows that the resultant dendrogram guarantees a lower bound of TSC. The empirical evaluation shows the effectiveness of our proposed method on artificial and Spatial Transcriptomics (bioinformatics) datasets. Our proposed method successfully creates a dendrogram that is consistent with the biological regions in a Spatial Transcriptomics dataset, whereas other contenders fail.
Mass Distribution versus Density Distribution in the Context of Clustering
Jan 14, 2026This paper investigates two fundamental descriptors of data, i.e., density distribution versus mass distribution, in the context of clustering. Density distribution has been the de facto descriptor of data distribution since the introduction of statistics. We show that density distribution has its fundamental limitation -- high-density bias, irrespective of the algorithms used to perform clustering. Existing density-based clustering algorithms have employed different algorithmic means to counter the effect of the high-density bias with some success, but the fundamental limitation of using density distribution remains an obstacle to discovering clusters of arbitrary shapes, sizes and densities. Using the mass distribution as a better foundation, we propose a new algorithm which maximizes the total mass of all clusters, called mass-maximization clustering (MMC). The algorithm can be easily changed to maximize the total density of all clusters in order to examine the fundamental limitation of using density distribution versus mass distribution. The key advantage of the MMC over the density-maximization clustering is that the maximization is conducted without a bias towards dense clusters.
LLMs Meet Isolation Kernel: Lightweight, Learning-free Binary Embeddings for Fast Retrieval
Jan 14, 2026Large language models (LLMs) have recently enabled remarkable progress in text representation. However, their embeddings are typically high-dimensional, leading to substantial storage and retrieval overhead. Although recent approaches such as Matryoshka Representation Learning (MRL) and Contrastive Sparse Representation (CSR) alleviate these issues to some extent, they still suffer from retrieval accuracy degradation. This paper proposes \emph{Isolation Kernel Embedding} or IKE, a learning-free method that transforms an LLM embedding into a binary embedding using Isolation Kernel (IK). IKE is an ensemble of diverse (random) partitions, enabling robust estimation of ideal kernel in the LLM embedding space, thus reducing retrieval accuracy loss as the ensemble grows. Lightweight and based on binary encoding, it offers low memory footprint and fast bitwise computation, lowering retrieval latency. Experiments on multiple text retrieval datasets demonstrate that IKE offers up to 16.7x faster retrieval and 16x lower memory usage than LLM embeddings, while maintaining comparable or better accuracy. Compared to CSR and other compression methods, IKE consistently achieves the best balance between retrieval efficiency and effectiveness.
A New Framework for Explainable Rare Cell Identification in Single-Cell Transcriptomics Data
Jan 04, 2026The detection of rare cell types in single-cell transcriptomics data is crucial for elucidating disease pathogenesis and tissue development dynamics. However, a critical gap that persists in current methods is their inability to provide an explanation based on genes for each cell they have detected as rare. We identify three primary sources of this deficiency. First, the anomaly detectors often function as "black boxes", designed to detect anomalies but unable to explain why a cell is anomalous. Second, the standard analytical framework hinders interpretability by relying on dimensionality reduction techniques, such as Principal Component Analysis (PCA), which transform meaningful gene expression data into abstract, uninterpretable features. Finally, existing explanation algorithms cannot be readily applied to this domain, as single-cell data is characterized by high dimensionality, noise, and substantial sparsity. To overcome these limitations, we introduce a framework for explainable anomaly detection in single-cell transcriptomics data which not only identifies individual anomalies, but also provides a visual explanation based on genes that makes an instance anomalous. This framework has two key ingredients that are not existed in current methods applied in this domain. First, it eliminates the PCA step which is deemed to be an essential component in previous studies. Second, it employs the state-of-art anomaly detector and explainer as the efficient and effective means to find each rare cell and the relevant gene subspace in order to provide explanations for each rare cell as well as the typical normal cell associated with the rare cell's closest normal cells.
Distribution-Based Feature Attribution for Explaining the Predictions of Any Classifier
Nov 12, 2025The proliferation of complex, black-box AI models has intensified the need for techniques that can explain their decisions. Feature attribution methods have become a popular solution for providing post-hoc explanations, yet the field has historically lacked a formal problem definition. This paper addresses this gap by introducing a formal definition for the problem of feature attribution, which stipulates that explanations be supported by an underlying probability distribution represented by the given dataset. Our analysis reveals that many existing model-agnostic methods fail to meet this criterion, while even those that do often possess other limitations. To overcome these challenges, we propose Distributional Feature Attribution eXplanations (DFAX), a novel, model-agnostic method for feature attribution. DFAX is the first feature attribution method to explain classifier predictions directly based on the data distribution. We show through extensive experiments that DFAX is more effective and efficient than state-of-the-art baselines.
Contrastive Multi-View Graph Hashing
Aug 17, 2025Multi-view graph data, which both captures node attributes and rich relational information from diverse sources, is becoming increasingly prevalent in various domains. The effective and efficient retrieval of such data is an important task. Although multi-view hashing techniques have offered a paradigm for fusing diverse information into compact binary codes, they typically assume attributes-based inputs per view. This makes them unsuitable for multi-view graph data, where effectively encoding and fusing complex topological information from multiple heterogeneous graph views to generate unified binary embeddings remains a significant challenge. In this work, we propose Contrastive Multi-view Graph Hashing (CMGHash), a novel end-to-end framework designed to learn unified and discriminative binary embeddings from multi-view graph data. CMGHash learns a consensus node representation space using a contrastive multi-view graph loss, which aims to pull $k$-nearest neighbors from all graphs closer while pushing away negative pairs, i.e., non-neighbor nodes. Moreover, we impose binarization constraints on this consensus space, enabling its conversion to a corresponding binary embedding space at minimal cost. Extensive experiments on several benchmark datasets demonstrate that CMGHash significantly outperforms existing approaches in terms of retrieval accuracy.
An Online Automatic Modulation Classification Scheme Based on Isolation Distributional Kernel
Oct 03, 2024



Automatic Modulation Classification (AMC), as a crucial technique in modern non-cooperative communication networks, plays a key role in various civil and military applications. However, existing AMC methods usually are complicated and can work in batch mode only due to their high computational complexity. This paper introduces a new online AMC scheme based on Isolation Distributional Kernel. Our method stands out in two aspects. Firstly, it is the first proposal to represent baseband signals using a distributional kernel. Secondly, it introduces a pioneering AMC technique that works well in online settings under realistic time-varying channel conditions. Through extensive experiments in online settings, we demonstrate the effectiveness of the proposed classifier. Our results indicate that the proposed approach outperforms existing baseline models, including two state-of-the-art deep learning classifiers. Moreover, it distinguishes itself as the first online classifier for AMC with linear time complexity, which marks a significant efficiency boost for real-time applications.
RAD: A Dataset and Benchmark for Real-Life Anomaly Detection with Robotic Observations
Oct 01, 2024



Recent advancements in industrial anomaly detection have been hindered by the lack of realistic datasets that accurately represent real-world conditions. Existing algorithms are often developed and evaluated using idealized datasets, which deviate significantly from real-life scenarios characterized by environmental noise and data corruption such as fluctuating lighting conditions, variable object poses, and unstable camera positions. To address this gap, we introduce the Realistic Anomaly Detection (RAD) dataset, the first multi-view RGB-based anomaly detection dataset specifically collected using a real robot arm, providing unique and realistic data scenarios. RAD comprises 4765 images across 13 categories and 4 defect types, collected from more than 50 viewpoints, providing a comprehensive and realistic benchmark. This multi-viewpoint setup mirrors real-world conditions where anomalies may not be detectable from every perspective. Moreover, by sampling varying numbers of views, the algorithm's performance can be comprehensively evaluated across different viewpoints. This approach enhances the thoroughness of performance assessment and helps improve the algorithm's robustness. Besides, to support 3D multi-view reconstruction algorithms, we propose a data augmentation method to improve the accuracy of pose estimation and facilitate the reconstruction of 3D point clouds. We systematically evaluate state-of-the-art RGB-based and point cloud-based models using RAD, identifying limitations and future research directions. The code and dataset could found at https://github.com/kaichen-z/RAD
Distributed Clustering based on Distributional Kernel
Sep 14, 2024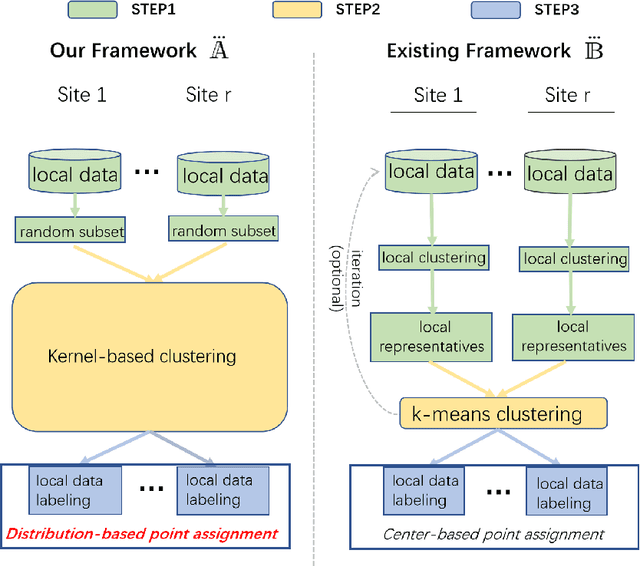

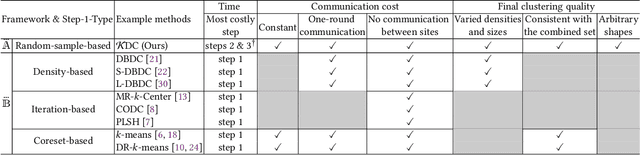
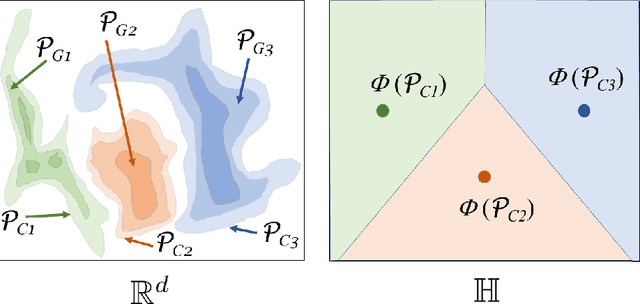
This paper introduces a new framework for clustering in a distributed network called Distributed Clustering based on Distributional Kernel (K) or KDC that produces the final clusters based on the similarity with respect to the distributions of initial clusters, as measured by K. It is the only framework that satisfies all three of the following properties. First, KDC guarantees that the combined clustering outcome from all sites is equivalent to the clustering outcome of its centralized counterpart from the combined dataset from all sites. Second, the maximum runtime cost of any site in distributed mode is smaller than the runtime cost in centralized mode. Third, it is designed to discover clusters of arbitrary shapes, sizes and densities. To the best of our knowledge, this is the first distributed clustering framework that employs a distributional kernel. The distribution-based clustering leads directly to significantly better clustering outcomes than existing methods of distributed clustering. In addition, we introduce a new clustering algorithm called Kernel Bounded Cluster Cores, which is the best clustering algorithm applied to KDC among existing clustering algorithms. We also show that KDC is a generic framework that enables a quadratic time clustering algorithm to deal with large datasets that would otherwise be impossible.