 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionFlow: A Pipelined Action Acceleration for Vision Language Models on Edge
Dec 23, 2025Vision-Language-Action (VLA) models have emerged as a unified paradigm for robotic perception and control, enabling emergent generalization and long-horizon task execution. However, their deployment in dynamic, real-world environments is severely hin dered by high inference latency. While smooth robotic interaction requires control frequencies of 20 to 30 Hz, current VLA models typi cally operate at only 3-5 Hz on edge devices due to the memory bound nature of autoregressive decoding. Existing optimizations often require extensive retraining or compromise model accuracy. To bridge this gap, we introduce ActionFlow, a system-level inference framework tailored for resource-constrained edge plat forms. At the core of ActionFlow is a Cross-Request Pipelin ing strategy, a novel scheduler that redefines VLA inference as a macro-pipeline of micro-requests. The strategy intelligently batches memory-bound Decode phases with compute-bound Prefill phases across continuous time steps to maximize hardware utilization. Furthermore, to support this scheduling, we propose a Cross Request State Packed Forward operator and a Unified KV Ring Buffer, which fuse fragmented memory operations into efficient dense computations. Experimental results demonstrate that ActionFlow achieves a 2.55x improvement in FPS on the OpenVLA-7B model without retraining, enabling real-time dy namic manipulation on edge hardware. Our work is available at https://anonymous.4open.science/r/ActionFlow-1D47.
Distributed Clustering based on Distributional Kernel
Sep 14, 2024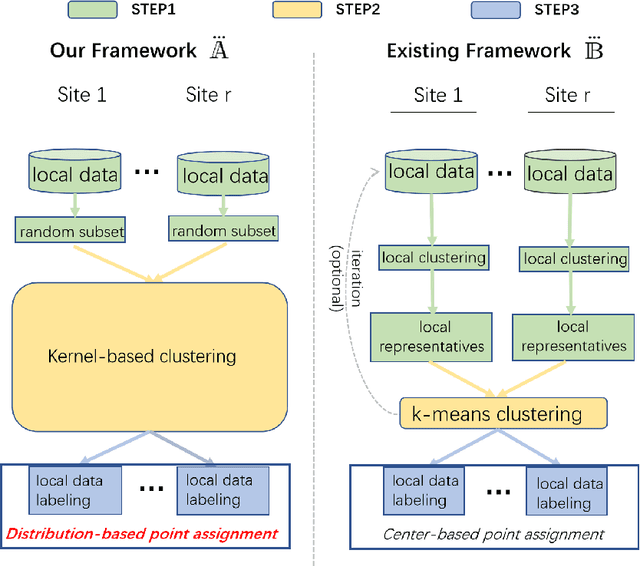

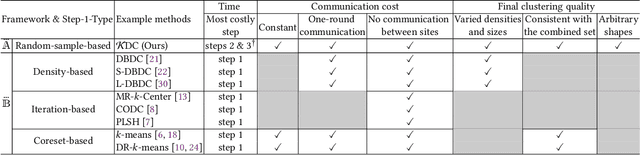
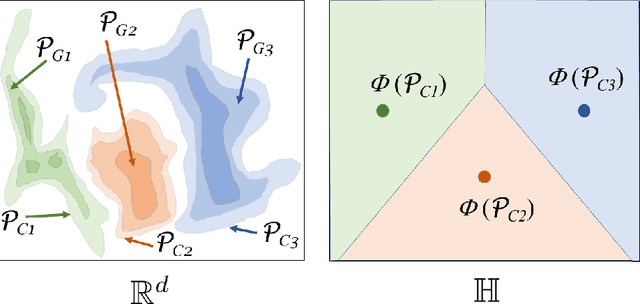
This paper introduces a new framework for clustering in a distributed network called Distributed Clustering based on Distributional Kernel (K) or KDC that produces the final clusters based on the similarity with respect to the distributions of initial clusters, as measured by K. It is the only framework that satisfies all three of the following properties. First, KDC guarantees that the combined clustering outcome from all sites is equivalent to the clustering outcome of its centralized counterpart from the combined dataset from all sites. Second, the maximum runtime cost of any site in distributed mode is smaller than the runtime cost in centralized mode. Third, it is designed to discover clusters of arbitrary shapes, sizes and densities. To the best of our knowledge, this is the first distributed clustering framework that employs a distributional kernel. The distribution-based clustering leads directly to significantly better clustering outcomes than existing methods of distributed clustering. In addition, we introduce a new clustering algorithm called Kernel Bounded Cluster Cores, which is the best clustering algorithm applied to KDC among existing clustering algorithms. We also show that KDC is a generic framework that enables a quadratic time clustering algorithm to deal with large datasets that would otherwise be impossible.
PriorNet: A Novel Lightweight Network with Multidimensional Interactive Attention for Efficient Image Dehazing
Apr 24, 2024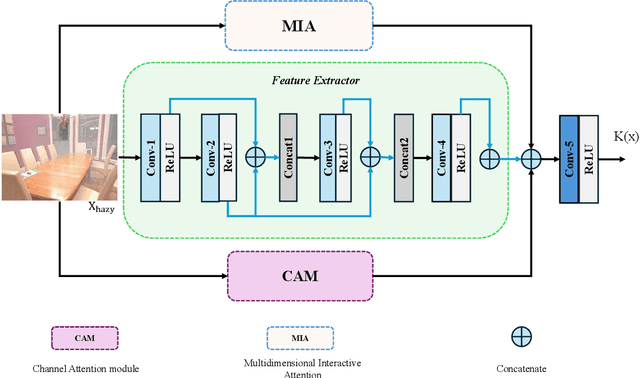
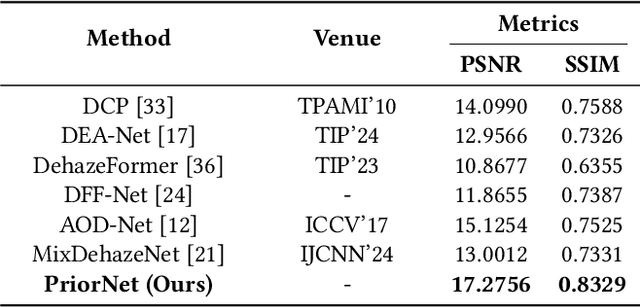
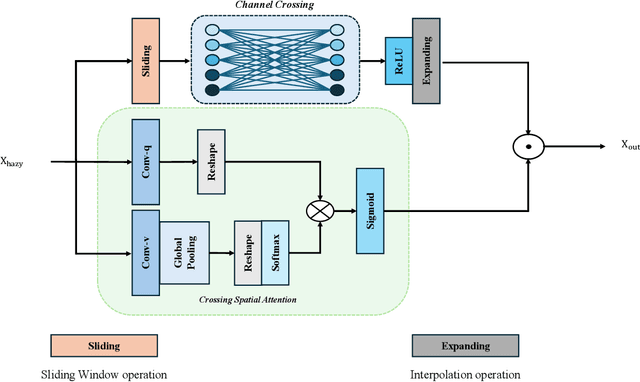

Hazy images degrade visual quality, and dehazing is a crucial prerequisite for subsequent processing tasks. Most current dehazing methods rely on neural networks and face challenges such as high computational parameter pressure and weak generalization capabilities. This paper introduces PriorNet--a novel, lightweight, and highly applicable dehazing network designed to significantly improve the clarity and visual quality of hazy images while avoiding excessive detail extraction issues. The core of PriorNet is the original Multi-Dimensional Interactive Attention (MIA) mechanism, which effectively captures a wide range of haze characteristics, substantially reducing the computational load and generalization difficulties associated with complex systems. By utilizing a uniform convolutional kernel size and incorporating skip connections, we have streamlined the feature extraction process. Simplifying the number of layers and architecture not only enhances dehazing efficiency but also facilitates easier deployment on edge devices. Extensive testing across multiple datasets has demonstrated PriorNet's exceptional performance in dehazing and clarity restoration, maintaining image detail and color fidelity in single-image dehazing tasks. Notably, with a model size of just 18Kb, PriorNet showcases superior dehazing generalization capabilities compared to other methods. Our research makes a significant contribution to advancing image dehazing technology, providing new perspectives and tools for the field and related domains, particularly emphasizing the importance of improving universality and deployability.
Nonconvex optimization for optimum retrieval of the transmission matrix of a multimode fiber
Aug 02, 2023Transmission matrix (TM) allows light control through complex media such as multimode fibers (MMFs), gaining great attention in areas like biophotonics over the past decade. The measurement of a complex-valued TM is highly desired as it supports full modulation of the light field, yet demanding as the holographic setup is usually entailed. Efforts have been taken to retrieve a TM directly from intensity measurements with several representative phase retrieval algorithms, which still see limitations like slow or suboptimum recovery, especially under noisy environment. Here, a modified non-convex optimization approach is proposed. Through numerical evaluations, it shows that the nonconvex method offers an optimum efficiency of focusing with less running time or sampling rate. The comparative test under different signal-to-noise levels further indicates its improved robustness for TM retrieval. Experimentally, the optimum retrieval of the TM of a MMF is collectively validated by multiple groups of single-spot and multi-spot focusing demonstrations. Focus scanning on the working plane of the MMF is also conducted where our method achieves 93.6% efficiency of the gold standard holography method when the sampling rate is 8. Based on the recovered TM, image transmission through the MMF with high fidelity can be realized via another phase retrieval. Thanks to parallel operation and GPU acceleration, the nonconvex approach can retrieve an 8685$\times$1024 TM (sampling rate=8) with 42.3 s on a regular computer. In brief, the proposed method provides optimum efficiency and fast implementation for TM retrieval, which will facilitate wide applications in deep-tissue optical imaging, manipulation and treatment.
Learning-based multiplexed transmission of scattered twisted light through a kilometer-scale standard multimode fiber
Jan 17, 2022Multiplexing multiple orbital angular momentum (OAM) modes of light has the potential to increase data capacity in optical communication. However, the distribution of such modes over long distances remains challenging. Free-space transmission is strongly influenced by atmospheric turbulence and light scattering, while the wave distortion induced by the mode dispersion in fibers disables OAM demultiplexing in fiber-optic communications. Here, a deep-learning-based approach is developed to recover the data from scattered OAM channels without measuring any phase information. Over a 1-km-long standard multimode fiber, the method is able to identify different OAM modes with an accuracy of more than 99.9% in parallel demultiplexing of 24 scattered OAM channels. To demonstrate the transmission quality, color images are encoded in multiplexed twisted light and our method achieves decoding the transmitted data with an error rate of 0.13%. Our work shows the artificial intelligence algorithm could benefit the use of OAM multiplexing in commercial fiber networks and high-performance optical communication in turbulent environments.
DLAU: A Scalable Deep Learning Accelerator Unit on FPGA
May 23, 2016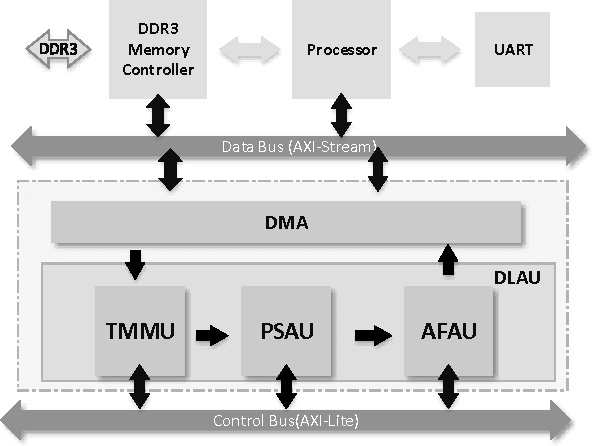
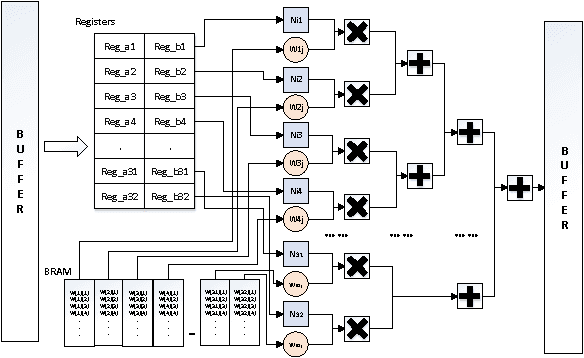
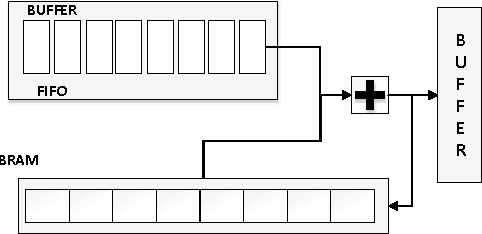
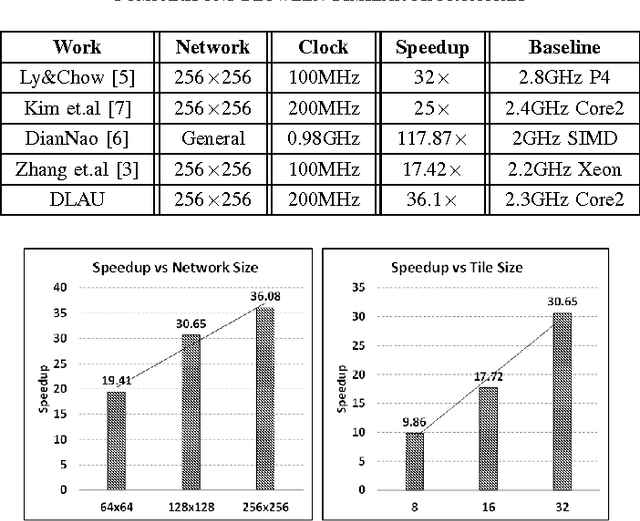
As the emerging field of machine learning, deep learning shows excellent ability in solving complex learning problems. However, the size of the networks becomes increasingly large scale due to the demands of the practical applications, which poses significant challenge to construct a high performance implementations of deep learning neural networks. In order to improve the performance as well to maintain the low power cost, in this paper we design DLAU, which is a scalable accelerator architecture for large-scale deep learning networks using FPGA as the hardware prototype. The DLAU accelerator employs three pipelined processing units to improve the throughput and utilizes tile techniques to explore locality for deep learning applications. Experimental results on the state-of-the-art Xilinx FPGA board demonstrate that the DLAU accelerator is able to achieve up to 36.1x speedup comparing to the Intel Core2 processors, with the power consumption at 234mW.