 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivariant Learning for Unsupervised Image Dehazing
Jan 20, 2026Image Dehazing (ID) aims to produce a clear image from an observation contaminated by haze. Current ID methods typically rely on carefully crafted priors or extensive haze-free ground truth, both of which are expensive or impractical to acquire, particularly in the context of scientific imaging. We propose a new unsupervised learning framework called Equivariant Image Dehazing (EID) that exploits the symmetry of image signals to restore clarity to hazy observations. By enforcing haze consistency and systematic equivariance, EID can recover clear patterns directly from raw, hazy images. Additionally, we propose an adversarial learning strategy to model unknown haze physics and facilitate EID learning. Experiments on two scientific image dehazing benchmarks (including cell microscopy and medical endoscopy) and on natural image dehazing have demonstrated that EID significantly outperforms state-of-the-art approaches. By unifying equivariant learning with modelling haze physics, we hope that EID will enable more versatile and effective haze removal in scientific imaging. Code and datasets will be published.
SHARE: A Fully Unsupervised Framework for Single Hyperspectral Image Restoration
Jan 20, 2026Hyperspectral image (HSI) restoration is a fundamental challenge in computational imaging and computer vision. It involves ill-posed inverse problems, such as inpainting and super-resolution. Although deep learning methods have transformed the field through data-driven learning, their effectiveness hinges on access to meticulously curated ground-truth datasets. This fundamentally restricts their applicability in real-world scenarios where such data is unavailable. This paper presents SHARE (Single Hyperspectral Image Restoration with Equivariance), a fully unsupervised framework that unifies geometric equivariance principles with low-rank spectral modelling to eliminate the need for ground truth. SHARE's core concept is to exploit the intrinsic invariance of hyperspectral structures under differentiable geometric transformations (e.g. rotations and scaling) to derive self-supervision signals through equivariance consistency constraints. Our novel Dynamic Adaptive Spectral Attention (DASA) module further enhances this paradigm shift by explicitly encoding the global low-rank property of HSI and adaptively refining local spectral-spatial correlations through learnable attention mechanisms. Extensive experiments on HSI inpainting and super-resolution tasks demonstrate the effectiveness of SHARE. Our method outperforms many state-of-the-art unsupervised approaches and achieves performance comparable to that of supervised methods. We hope that our approach will shed new light on HSI restoration and broader scientific imaging scenarios. The code will be released at https://github.com/xuwayyy/SHARE.
AIComposer: Any Style and Content Image Composition via Feature Integration
Jul 28, 2025Image composition has advanced significantly with large-scale pre-trained T2I diffusion models. Despite progress in same-domain composition, cross-domain composition remains under-explored. The main challenges are the stochastic nature of diffusion models and the style gap between input images, leading to failures and artifacts. Additionally, heavy reliance on text prompts limits practical applications. This paper presents the first cross-domain image composition method that does not require text prompts, allowing natural stylization and seamless compositions. Our method is efficient and robust, preserving the diffusion prior, as it involves minor steps for backward inversion and forward denoising without training the diffuser. Our method also uses a simple multilayer perceptron network to integrate CLIP features from foreground and background, manipulating diffusion with a local cross-attention strategy. It effectively preserves foreground content while enabling stable stylization without a pre-stylization network. Finally, we create a benchmark dataset with diverse contents and styles for fair evaluation, addressing the lack of testing datasets for cross-domain image composition. Our method outperforms state-of-the-art techniques in both qualitative and quantitative evaluations, significantly improving the LPIPS score by 30.5% and the CSD metric by 18.1%. We believe our method will advance future research and applications. Code and benchmark at https://github.com/sherlhw/AIComposer.
PriorNet: A Novel Lightweight Network with Multidimensional Interactive Attention for Efficient Image Dehazing
Apr 24, 2024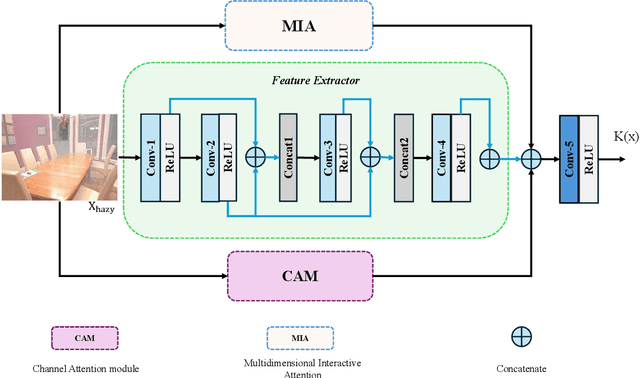
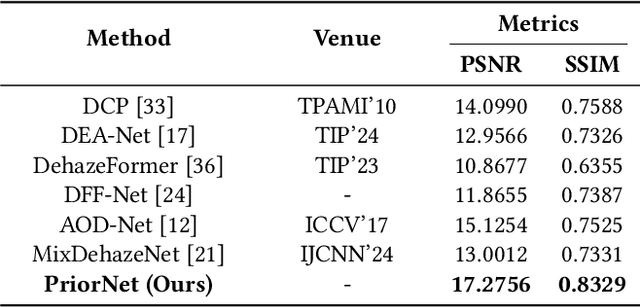
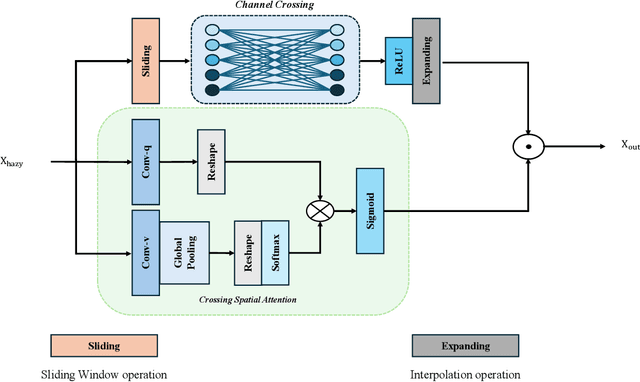

Hazy images degrade visual quality, and dehazing is a crucial prerequisite for subsequent processing tasks. Most current dehazing methods rely on neural networks and face challenges such as high computational parameter pressure and weak generalization capabilities. This paper introduces PriorNet--a novel, lightweight, and highly applicable dehazing network designed to significantly improve the clarity and visual quality of hazy images while avoiding excessive detail extraction issues. The core of PriorNet is the original Multi-Dimensional Interactive Attention (MIA) mechanism, which effectively captures a wide range of haze characteristics, substantially reducing the computational load and generalization difficulties associated with complex systems. By utilizing a uniform convolutional kernel size and incorporating skip connections, we have streamlined the feature extraction process. Simplifying the number of layers and architecture not only enhances dehazing efficiency but also facilitates easier deployment on edge devices. Extensive testing across multiple datasets has demonstrated PriorNet's exceptional performance in dehazing and clarity restoration, maintaining image detail and color fidelity in single-image dehazing tasks. Notably, with a model size of just 18Kb, PriorNet showcases superior dehazing generalization capabilities compared to other methods. Our research makes a significant contribution to advancing image dehazing technology, providing new perspectives and tools for the field and related domains, particularly emphasizing the importance of improving universality and deployability.
Analogical Inference Enhanced Knowledge Graph Embedding
Jan 03, 2023



Knowledge graph embedding (KGE), which maps entities and relations in a knowledge graph into continuous vector spaces, has achieved great success in predicting missing links in knowledge graphs. However, knowledge graphs often contain incomplete triples that are difficult to inductively infer by KGEs. To address this challenge, we resort to analogical inference and propose a novel and general self-supervised framework AnKGE to enhance KGE models with analogical inference capability. We propose an analogical object retriever that retrieves appropriate analogical objects from entity-level, relation-level, and triple-level. And in AnKGE, we train an analogy function for each level of analogical inference with the original element embedding from a well-trained KGE model as input, which outputs the analogical object embedding. In order to combine inductive inference capability from the original KGE model and analogical inference capability enhanced by AnKGE, we interpolate the analogy score with the base model score and introduce the adaptive weights in the score function for prediction. Through extensive experiments on FB15k-237 and WN18RR datasets, we show that AnKGE achieves competitive results on link prediction task and well performs analogical inference.